CIB merge technischer Leitfaden
| Site: | CIB eLearning |
| Course: | CIB merge |
| Book: | CIB merge technischer Leitfaden |
| Printed by: | Guest user |
| Date: | Thursday, 18 June 2026, 10:48 AM |
Table of contents
- 1. Einführung
- 2. Installation
- 3. CIB merge als „Dokumentinterpreter“
- 4. Datenversorgung
- 5. Technische Schnittstellen
- 6. Aufrufparameter im Detail
- 6.1. Allgemeine Hinweise
- 6.2. Hinweis Aufrufbeispiele
- 6.3. Übersicht der Abkürzungen für Aufrufparameter
- 6.4. Parameter --analyse
- 6.5. Parameter --break
- 6.6. Parameter --charformat
- 6.7. Parameter --chart-…
- 6.8. Parameter --codepage
- 6.9. Parameter --colors
- 6.10. Parameter --compress
- 6.11. Parameter --datafile
- 6.12. Parameter --default-mode
- 6.13. Parameter --default-prefix
- 6.14. Parameter --delimiter
- 6.15. Parameter --destination-colorschememapping
- 6.16. Parameter --destination-datastore
- 6.17. Parameter --destination-themedata
- 6.18. Parameter --dialog
- 6.19. Parameter --directory-…
- 6.20. Parameter --directory-set-inline
- 6.21. Parameter --directory-log
- 6.22. Parameter --directory-read
- 6.23. Parameter --directory-remove
- 6.24. Parameter --directory-set
- 6.25. Parameter --directory-write
- 6.26. Parameter --docproperty
- 6.27. Parameter --encrypt
- 6.28. Parameter --field-nesting-level-limit
- 6.29. Parameter --field-results
- 6.30. Parameter --filter
- 6.31. Parameter --fonts
- 6.32. Parameter --headerfile
- 6.33. Parameter --help
- 6.34. Parameter --inline-is-not-this
- 6.35. Parameter --html-switches
- 6.36. Parameter --inputfile
- 6.37. Parameter --input-language
- 6.38. Parameter --intermediatefile
- 6.39. Parameter --keep-fields
- 6.40. Parameter --keep-refs-if-in-list
- 6.41. Parameter --LicenseCompany
- 6.42. Parameter --LicenseKey
- 6.43. Parameter --lists
- 6.44. Parameter --logfile
- 6.45. Parameter -m
- 6.46. Parameter -- max-executiontime
- 6.47. Parameter --maxOutputSize
- 6.48. Parameter --maxSingleSize
- 6.49. Parameter --merge
- 6.50. Parameter --multidatafile
- 6.51. Parameter --next-mode
- 6.52. Parameter --old-compare
- 6.53. Parameter --optimize
- 6.54. Parameter --outputfile
- 6.55. Parameter --output-language
- 6.56. Parameter --parameterfile
- 6.57. Parameter --prefix-delimiter
- 6.58. Parameter --remove-hidden-text
- 6.59. Parameter --replace-header
- 6.60. Parameter --serialletter
- 6.61. Parameter --set
- 6.62. Parameter --short-tokens
- 6.63. Parameter --source-directory
- 6.64. Parameter --statistics
- 6.65. Parameter --target-directory
- 6.66. Parameter --template-combine
- 6.67. Parameter --verbose
- 6.68. Parameter --version
- 6.69. Parameter --window-handle
- 6.70. Parameter --workingset-size
- 7. Besondere Funktionalitäten: Textcaching
- 8. Besondere Funktionalitäten: Ergebnisoptimierung, Verschlüsselung und Komprimierung
- 9. Besondere Funktionalitäten: Mischen von Dokumenten-Eigenschaften
- 10. Anwendungsbeispiele
- 11. Schneller Einstieg
- 12. Sonstiges
1. Einführung
CIB merge ist eine zentrale Komponente aus dem Dokumentbaukasten der CIB office Module. Mit CIB merge bekommt der Anwender ein Werkzeug an die Hand, womit er Dokumentbausteine (=Templates), die auch Feldanweisungen (=Befehle) beinhalten können, interpretieren und mit variablen Daten versorgt zu einem Zieldokument mischen kann. CIB merge unterstützt das RTF-Format von Microsoft als Dokumentenformat. Die variablen Daten können aus einer oder mehreren CSV-Dateien, XML-Dateien oder aus Datenbank(en) eingemischt werden. Es besteht auch die Möglichkeit, eigene UserExit-Funktionen in CIB merge einzuhängen.
Die vorliegende Dokumentation gibt einen schnellen Überblick über die Einsatzmöglichkeiten.
2. Installation
Windows 32/64-Bit
Für die aktive Nutzung des RTF Textinterpreters muss die jeweilige CIB merge Programmversion im Zugriff sein.
Unix allgemein
Es sind aus Gründen mehrerer Libs Archive mit Installationsanleitung für verschiedende Unix-Derivate verfügbar…
Systeme
CIB merge läuft unter Windows 32- und 64-bit.
CIB merge ist für folgende weitere Plattformen verfügbar:
- Solaris Sparc (32/64)
- Solaris x86 (32/64)
- AIX-ppc (32/64)
- Linux-x86 (32/64)
Weitere Plattformen auf Anfrage.
Zusatzmodule
Nach dem bewährten Baukastenprinzip der CIB office Module (=CoMod), gibt es rund um CIB merge auch Zusatzkomponenten, die dem Entwickler entweder die technische Integration in seine bevorzugte Architektur erleichtern oder auch den Funktionsumfang des CIB merge Modules sinnvoll ergänzen können.
Alle Zusatzprodukte sind in separaten technischen Leitfaden ausführlich dokumentiert. Diese Informationen können Sie gerne beim CIB Support anfordern.
CIB chartSiehe dazu eigener TechnischerLeitfadenCIBChart.
Sie eignet sich auch hervorragend für einen Einsatz innerhalb von (Batch)jobs und zur Gestaltung eigener Prozesse (Instanzen) mit den Modulen. Eine Java-Kapselung ist für die CIB runshell ebenfalls verfügbar.
JCoMod WrapperMit dem JCoMod Wrapper erhalten Sie eine komplette JAVA/JNI Kapselung, die eine einfache Ansteuerung von CIB merge aus JAVA ermöglicht. Die entsprechenden JAVA/JNI Schnittstellen bedienen auch die CIB runshell, so dass man die CIB Komponenten auch in eigenen Prozessen innerhalb der JAVA VM starten kann.
CoMod.netCIB documentServer/J2EE
Der Aufruf und die Nutzung des CIB documentsSrvers befreit die Entwickler der aufrufenden Anwendung von den Details der jeweiligen technischen Anbindung der CIB docgen Module:
Der Aufruf der Dokumentgenerierung erfolgt mittels einer standardisierten Auftragsbeschreibung im XML-Format, in der die Eingabe, die Ausgaben, Optionen und sogar Daten für CIB merge formal angegeben sind.
Zusätzlich steht dem Anwendungsentwickler ein Framework aus Java-Klassen zur leichteren Einbindung zur Verfügung.
CIB workbenchCIB pdf toolbox
Beachten Sie dazu den eigenen technischen Leitfaden.
3. CIB merge als „Dokumentinterpreter“
CIB merge ist ein universeller Interpreter zur dynamischen Verarbeitung von Dokumenten mit Feldbefehlen, externer Datenversorgung über CSV- oder XML-Dateien, SQL Zugriffen sowie eigenen User Exits.
Es wird RTF als Dokumenteingabeformat unterstützt.
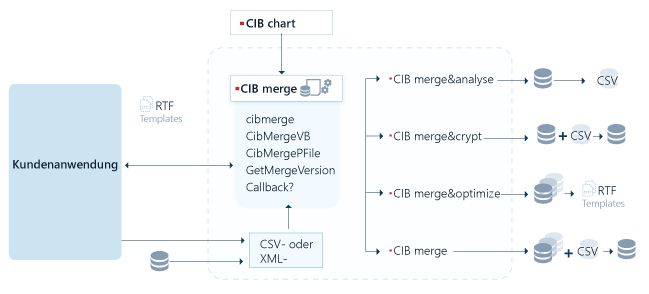
Dem Anwender steht über die Aufrufschnittstelle der gesamte Funktionsumfang des CIB merge zur Verfügung.
Die CIB merge Funktionalität lässt sich in "Aufgabengebiete" untergliedern. Diese können größtenteils aber auch über einen einzigen Aufruf gleichzeitig genutzt werden.3.1. CIB merge
Mit CIB merge ist es möglich:
- Daten aus externen XML und CSV Datenquellen in RTF einzumischen. Dabei werden im RTF Dokument enthaltene Variablenfelder über ihren eindeutigen Namen angesprochen und mit dem angegebenen Inhalt gefüllt. Durch die Möglichkeit der Abarbeitung von Datensätzen wird sowohl die Einzelbrief- als auch die Serienbrieffunktionalität unterstützt.
- Es möglich auch direkte SQL Abfragen aus Dokumenten auszuführen.
- Es ist möglich userseitig aus Dokumente über einen Mischlauf anzusteuern.
3.2. CIB merge&optimize
Die Dokumentbasis (=Templates) wird unter Verwendung von auf dem Markt weitverbreiteten Textsystemen (i.d.R. MS-Office, Open Office) unterschiedlichster Versionen erstellt. Entsprechend sind die einzelnen Bausteine z. T. mit verschiedenen sehr redundanten Informationen angereichert.
CIB merge & optimize ermöglicht es, ohne einen Mischlauf auszuführen, beim Bereitstellen der Bausteine (="Deployen von Templates") in die Anwendungsumgebung, diese entsprechend zu verschlanken, ohne deren Formatierung oder den Inhalt zu ändern.
3.3. CIB merge&crypt
Häufig besteht die Anforderung, die Dokumentbasis (=Templates) geschützt in einer Anwendung zu hinterlegen und ebenso irgendwelche Zwischenergebnisse aus einem Mischlauf gegen "Missbrauch" zu schützen. CIB merge verfügt über entsprechende Aufrufoptionen, die ein Packen und/oder Verschlüsseln ermöglichen.
3.4. CIB merge&analyse
Über eine eigene Umgebung „report & analyse“ bietet CIB die Möglichkeit von Dokumentenprojekten ein eigenes Reporting zu erzeugen. Die CIB merge Komponente leistet in dieser Analyseumgebung wertvolle Dienste, sowohl beim Auswerten der Bausteininhalte des Analyseprojektes als auch beim Erzeugen des eigentlichen Ausgabereports. Beachten Sie hierzu die Detailinformationen aus dem speziellen technischen Leitfaden „CIB report & analyse“.
3.5. Unterstützte Feldbefehle
AllgemeinÜbersicht der grundlegenden Feldbefehle
Unterstützte Text-Funktionen
Unterstützte Datums-Funktionen
Regeln für die Verarbeitung von Text- und Datumsfunktionen
Allgemein
MS-Office stellt ca. 85 verschiedene Feldbefehle zur Verfügung, die man zur Programmierung von dynamischen Dokumenten benutzen kann. Alle Befehle die nicht unmittelbar mit der Formatierung eines Textes zu tun haben, werden von der CIB merge Komponente bei einem Mischlauf ausgewertet und unterstützt.
Die Interpretation der übrigen Feldbefehle, die für die Layout-/Druckdarstellung wichtig sind (z.B. (Gesamt)Seitennummerierungen, Druckdatum, Signaturfelder u.a.), bleibt der CIB format/output-Komponente vorbehalten. CIB merge reicht diese Feldbefehle ungefiltert in das Ergebnisdokument durch.
Ab CIB merge Version 3.13.7:
Das gleiche Verhalten gilt bei einem Rechenausdruck, der Referenzen auf Tabellenelemente enthält: Der Ausdruck wird ungefiltert an das Ergebnisdokument durchgereicht.
Konkret geht es um diese Referenzen: LEFT/LINKS, RIGHT/RECHTS, ABOVE/ÜBER, BELOW /UNTER.
Übersicht der grundlegenden Feldbefehle
Folgende Feldbefehle eines Dokumentes werden bei einem Mischvorgang direkt durch die CIB merge Komponente interpretiert und dynamisch in die Ausgabedatei umgesetzt (die Feldbefehle sind hier lediglich alphabetisch aufgestellt und nicht mit voller Syntax beschrieben):
|
Feldbefehl ( engl. / dt) |
Bedeutung |
|
COMPARE / VERGLEICH |
Vergleicht zwei Werte und gibt den numerischen Wert 1 zurück, wenn der Vergleich wahr ist, und 0 (Null), wenn der Vergleich falsch ist. |
|
DATA / STEUERDATEI |
|
|
DATE |
Fügt das aktuelle Datum ein. |
|
IF / WENN |
Vergleicht Argumente unter Berücksichtigung bestimmter Bedingungen. Kann optional zu einem Schleifenbefehl erweitert werden. |
|
INCLUDEPICTURE / EINFÜGENGRAFIK |
Fügt eine Grafik aus einer Datei ein. Wird von CIB merge nur in Verbindung mit dem Aufrufparameter --EMBED ausgeführt. Ansonsten erfolgt die Interpretation erst durch CIB format/output |
|
INCLUDEPICTURE "?Grafikdatei" (ab CIB merge Version 3.9.174) |
Liefert 0 zurück, wenn die Datei nicht vorhanden ist, ansonsten 1. |
|
INCLUDETEXT / EINFÜGENTEXT |
Fügt einen Text aus einer Datei ein. „Bitte beachten Sie in diesem Zusammenhang den möglichen Feldschalter NEWLISTID“ |
|
INCLUDETEXT "?Textdatei" |
Liefert 0 zurück, wenn die Datei nicht vorhanden ist, ansonsten 1. |
|
INFO / INFO |
Fügt Informationen aus dem Dialogfeld „Eigenschaften“ ein. |
|
MERGEFIELD / SERIENDRUCKFELD |
Legt einen Platzhalter mit Namen fest, der später durch einen angelieferten variablen Inhalt ersetzt wird. |
|
MERGEREC <Alias-Name> |
Fügt die Nummer ein, die der aktuelle Datensatz in der Eingabedatei (bzw. Tabelle) <Alias-Name> hat. |
|
MERGEREC ?<Alias-Name> |
Liefert 0 zurück, wenn keine weiteren Datensätze in der Datei (bzw. Tabelle) <Alias-Name> vorhanden sind. |
|
MERGEREC #<Alias-Name> (ab CIB merge Version 3.12.1) |
Liefert die exakte Anzahl Datensätze der Datei (bzw. Tabelle) <Alias-Name> zurück. Achtung: Diese Funktion kann bei CSV-Datenquellen Resourcen-intensiv sein! |
|
MERGEREC ##<Alias-Name> (ab CIB merge Version 3.12.1) |
Liefert Status-Information über die Anzahl Datensätze der Datei (bzw. Tabelle) <Alias-Name>zurück. Werte: 1 ein Datensatz 2 zwei oder mehr Datensätze Achtung: Diese Funktion hat bei CSV Datenquellen keine negativen Auswirkungen auf die Resourcen. |
|
NEXT / NÄCHSTER |
Geht zum nächsten Datensatz oder Knoten in der Datenversorgung. |
|
NEXTIF / NWENN |
Geht zum nächsten Datensatz oder Knoten in der Datenversorgung, wenn eine bestimmte Bedingung erfüllt ist. |
|
QUOTE / ANGEBEN |
Fügt einen Text in das Dokument ein. |
|
REF / REF |
Legt einen Platzhalter mit Namen fest, der später durch einen angelieferten variablen Inhalt ersetzt wird. |
|
REF "?variable" (ab CIB merge Version 3.9.191) |
Liefert 0 zurück, wenn die Variable nicht vorhanden ist, ansonsten 1. |
|
TO DO: REF DAT |
|
|
TO DO: NEXT DEF |
|
|
SET / BESTIMMEN |
Weist einer Textmarke einen neuen Text zu. |
|
SKIPIF / ÜBERSPRINGEN |
Überspringt während eines Serienbriefes einen Datensatz oder Knoten in der Datenversorgung entsprechend einer Bedingung. Verwendung mit Aliasnamen ist nicht möglich! |
|
TIME / ZEIT |
Fügt die aktuelle Uhrzeit ein. |
|
= Ausdruck / Expression |
Berechnet das Ergebnis eines Ausdruckes (=Formeln). CIB merge unterstützt sehr umfangreiche Funktionen, auch in komplizierten Formeln. |
Einige dieser Feldbefehle ermöglichen mit Zusatzschaltern eine Erweiterung ihrer Funktionalität.
Beispielsweise können mit Hilfe von Schleifenanweisungen beliebig lange dynamische Tabellen erzeugt werden. Auch das dynamische Einfügen von Textbausteinen ist möglich.
Unterstützte Text-Funktionen
CIB merge unterstützt ab Version 3.12.0 die im Folgenden beschriebenen Text-Funktionen.
Hinweise:
- Die Möglichkeit für eine verkettete (mehrfache) Verarbeitung von Textfunktionen ist hier beschrieben.
- Als Parameter einer Textfunktion können feststehende Texte (Strings) verwendet werden. Der Inhalt eines Strings ist in Anführungszeichen anzugeben. Dabei darf der String selbst keine Anführungszeichen enthalten.
|
Text Funktion (Syntax) |
Beschreibung |
|
TRIM(text) |
Löscht Leerzeichen in einem Text, die nicht einzeln zwischen Wörtern stehen und damit als Trennzeichen dienen. TRIM können Sie für Texte verwenden, die Sie aus anderen Anwendungsprogrammen übernommen haben und die eventuell unerwünschte Leerzeichen enthalten. Parameter: text (Typ Text, erforderlich) Der Text, aus dem Sie die Leerzeichen entfernen möchten. Beispiel: =Trim( " abc " ) ergibt abc |
|
LEN(text) |
Gibt die Anzahl der Zeichen einer Zeichenfolge zurück. Parameter: text (Typ Text, erforderlich) Der Text, dessen Länge Sie ermitteln möchten. Leerzeichen zählen als Zeichen. Beispiel: = LEN( "ab abc" ) ergibt 6 |
|
FIND(find_text;within_text;
start_num) |
Mit FIND wird eine Zeichenfolge innerhalb einer anderen gesucht und die Position der gesuchten Zeichenfolge ab dem ersten Zeichen der anderen Zeichenfolge zurückgegeben. Parameter: find_text (Typ Text, erforderlich) Gibt den Text an, den Sie suchen. within_text (Typ Text, erforderlich) Ist der Text, in dem Sie nach find_text suchen möchten. start_num (Typ Zahl, erforderlich) Gibt an, bei welchem Zeichen die Suche begonnen werden soll. Das erste zu find_text gehörende Zeichen hat die Nummer 1. Beispiel: =FIND( "b"; "abc", 1 ) ergibt 2 Hinweise:
|
|
SEARCH(find_text; within_text;
start_num) |
SEARCH sucht eine Zeichenfolge innerhalb einer anderen Zeichenfolge und gibt als Ergebnis die Nummer der Anfangsposition der ersten Zeichenfolge zurück, gerechnet ab dem ersten Zeichen der zweiten Zeichenfolge. Parameter: find_text (Typ Text, erforderlich) Ist der Text, nach dem Sie suchen möchten. Eine als find_text angegebene Zeichenfolge kann die Platzhalterzeichen Fragezeichen (?) und Sternchen (*) enthalten. Ein Fragezeichen ersetzt ein Zeichen, ein Sternchen ersetzt eine beliebige Zeichenfolge. Suchen Sie nach einem Fragezeichen oder Sternchen, müssen Sie vor dem zu suchenden Zeichen zwei Backslashes (\\) eingeben. within_text (Typ Text, erforderlich) Ist der Text, in dem Sie nach find_text suchen möchten. start_num (Typ Zahl, erforderlich) Gibt an, bei welchem Zeichen die Suche begonnen werden soll. Das erste zu find_text gehörende Zeichen hat die Nummer 1. Beispiel: =SEARCH( "b"; "ABC", 1 ) ergibt 2 Hinweise:
|
|
MID(text; start_num; num_chars) |
Die Mid-Funktion gibt eine bestimmte Anzahl zusammenhängender Zeichen aus einem vorgegebenen String zurück. Parameter: text (Typ Text, erforderlich) Text, aus dem Zeichen zurückgegeben werden. start_num(Typ Zahl, erforderlich) Zeichenposition in text, an der der zu entnehmende Teil beginnt. num_chars(Typ Zahl, erforderlich) Gibt die Anzahl der Zeichen ab, die MID aus text zurückgeben soll Beispiel: =MID( "abc"; 2; 1 ) ergibt b Hinweise:
|
|
SUBSTITUTE(text; old_text; new_text;
instance_num) |
Ersetzt alten Text durch neuen Text in einer Zeichenfolge. SUBSTITUTE können Sie immer dann verwenden, wenn Sie innerhalb eines Textes eine bestimmte Zeichenfolge austauschen möchten. REPLACE sollten Sie immer dann verwenden, wenn Sie innerhalb eines Textes eine an einer bestimmten Position beginnende Zeichenfolge ersetzen möchten. Parameter: text (Typ Text, erforderlich) Ist der Text in dem Zeichen ausgetauscht werden sollen. old_text (Typ Text, erforderlich) Ist der Text, den Sie ersetzen möchten. new_text (Typ Text, erforderlich) Ist der Text, durch den Sie old_text ersetzen möchten. instance_num (Typ Zahl, optional) Gibt an, an wie oft old_text durch new_text ersetzt werden soll. Wenn Sie instance_num angeben, wird nur dieses Vorkommen von old_text ersetzt; andernfalls wird old_text an jeder Stelle, an der er in text vorkommt, durch new_text ersetzt. Beispiel: =SUBSTITUTE( "abcbcbcd"; "bc"; "d"; 2 ) ergibt addbcd |
|
REPLACE(old_text; start_num;
num_chars; new_text) |
REPLACE ersetzt in dem Text ab der angegebenen Position eine Zeichenfolge der vorgegebenen Länge durch eine andere Zeichenfolge. Parameter: old_text (Typ Text, erforderlich) Ist der Text, in dem Sie eine Anzahl von Zeichen ersetzen möchten. start_num (Typ Zahl, erforderlich) Die Position des Zeichens in old_text, an der mit dem Ersetzen durch new_text begonnen werden soll. num_chars (Typ Zahl, erforderlich) Die Anzahl der Zeichen in old_text, die REPLACE durch new_text ersetzen soll. new_text (Typ Text, erforderlich) Der Text, durch den Sie Zeichen in old_text ersetzen wollen. Beispiel: =REPLACE( "abcd"; 2; 2; "d" ) ergibt add |
|
LOWER(text) |
Wandelt einen Text in Kleinbuchstaben um. Parameter: text (Typ Text, erforderlich) Der Text, den Sie in Kleinbuchstaben umwandeln möchten. Beispiel: =LOWER( "ABC9" ) ergibt abc9 Hinweise: LOWER nimmt an Zeichen des Texts, die keine Buchstaben sind, keine Änderungen vor. |
|
UPPER(text) |
Wandelt einen Text in Großbuchstaben um. Parameter: text (Typ Text, erforderlich) Der Text, den Sie in Großbuchstaben umwandeln möchten. Beispiel: = UPPER( "abc9" ) ergibt ABC9 Hinweise: UPPER nimmt an Zeichen des Texts, die keine Buchstaben sind, keine Änderungen vor. |
|
LEFT(text; num_chars) |
Schneidet von links beginnend die vorgegebene Anzahl von Zeichen aus. Parameter: text (Typ Text, erforderlich) Die Textzeichenfolge mit den auszuschneidenden Zeichen. num_chars (Typ Zahl, erforderlich) Anzahl der Zeichen, die zurückzugeben sind. Beispiel: =LEFT( "abc"; 2 ) ergibt ab Hinweise:
|
|
RIGHT(text; num_chars) |
Schneidet von rechts beginnend die vorgegebene Anzahl von Zeichen aus. Parameter: text (Typ Text, erforderlich) Die Textzeichenfolge mit den auszuschneidenden Zeichen. num_chars (Typ Zahl, erforderlich) Anzahl der Zeichen, die zurückzugeben sind. Beispiel: =RIGHT( "abc"; 2 ) ergibt bc Hinweise:
|
|
REPT(text; number_times) |
Wiederholt einen Text so oft wie angegeben. Mit REPT können Sie einen Text mit einer bestimmten Häufigkeit wiederholen. Parameter: text (Typ Text, erforderlich) Den zu wiederholenden Text. number_times (Typ Zahl, erforderlich) Eine positive Zahl, die die Anzahl der Wiederholungen angibt. Beispiel: =REPT( "abc"; 2 ) ergibt abcabc Hinweise:
|
|
TOKENIZE(text; delimiters;
tokenIdx) |
Teilt einen Text anhand der angegebenen Trennzeichen in einzelne Textteile und gibt den mit tokenIdx angegebenen Teil zurück (z.B. bei tokenIdx = 3, den dritten Teil). Parameter: text (Typ Text, erforderlich) Den aufzuteilenden Text. delimiters (Typ Text, erforderlich) Liste der Trennzeichen. Wird ein Komma als Trennzeichen verwendet, muss es mit einem Backslash (\) maskiert werden. tokenIdx (Typ Zahl, erforderlich) Nummer des Textteils der zurückgegeben werden soll. Bei einem negativen Index wird vom Ende des Texts mit der Zählung begonnen. Beispiele: =TOKENIZE( "a b c-d"; " -"; 4 ) ergibt d Hinweise:
|
|
BEFORE(text; before_text) |
Gibt die Zeichen von text zurück, die dem ersten Vorkommen von before_text in text vorausgehen, oder gibt eine leere Zeichenfolge zurück, wenn before_text in text nicht enthalten ist. Parameter: text (Typ Text, erforderlich) Ist der Text dem die Zeichenfolge entnommen werden soll. before_text (Typ Text, erforderlich) Der zu suchende Text, der das Ende der zu entnehmenden Zeichenfolge kennzeichnet. Beispiel: =BEFORE( "abcdefg"; "cd" ) liefert ab Hinweise:
|
|
AFTER(text; after_text) |
Gibt die Zeichen von text zurück, die dem ersten Vorkommen von after_text in text folgen, oder gibt eine leere Zeichenfolge zurück, wenn after_text in text nicht enthalten ist. Parameter: text (Typ Text, erforderlich) Ist der Text dem die Zeichenfolge entnommen werden soll. after_text (Typ Text, erforderlich) Der zu suchende Text, der den Beginn der zu entnehmenden Zeichenfolge kennzeichnet. Beispiel: =AFTER( "abcdefg"; "cd" ) liefert efg Hinweise:
|
|
FORMAT(text; format)
|
Gibt text im Format format zurück. Diese Funktion funktioniert ähnlich wie Formatierung von Zahlen. Parameter: text (Typ Text, erforderlich) Ist der zu formatierende Text. format (Typ Text, erforderlich) Gibt das Format an (Details s. unten) Gültige Zeichen zur Angabe des Formats: x Platzhalterzeichen für ein Zeichen des angegebenen Texts. Hinzufügen von Abständen und Trennzeichen: Leerzeichen wird genau in der eingegebenen Form angezeigt / wird genau in der eingegebenen Form angezeigt ( wird genau in der eingegebenen Form angezeigt ) wird genau in der eingegebenen Form angezeigt . wird genau in der eingegebenen Form angezeigt - wird genau in der eingegebenen Form angezeigt Beispiele: =Format(„abcdefghi“;“xxx xxx xxx“) liefert „abc def ghi“ Hinweise:
|
Unterstützte Datums-Funktionen
CIB merge unterstützt ab Version 3.12.12 die im Folgenden beschriebenen Datums-Funktionen.
Die Datumsfunktionen werden analog zu Rechen- oder Textfunktionen
in der Form
{ =DATUMSFUNKTION }in das Dokument eingegeben.
Vorraussetzung für diese Funktionen ist, dass das als Eingabe verwendete Datum (bzw. eine Variable „Datum“) einen gültigen Datumswert besitzt und in einem gültigen Datumsformat formatiert ist.
|
Datums Funktion (Syntax) |
Beschreibung |
|
ADDDAYS(Datum,AnzTage) \@ Format Rückgabe: Datum |
Tage addieren: Parameter: Datum Siehe obige Vorraussetzung AnzTage Ganzzahl Format Muss gültige Syntax für die Datumsformatierung haben
|
|
ADDDAYS_VD(VDatum,AnzTage) \@ Format Rückgabe: Datum |
Tage addieren mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel:
|
|
ADDMONTHS(Datum,AnzMonate) \@ Format Rückgabe: Datum |
Monate addieren: Parameter: Datum Siehe obige Vorraussetzung AnzMonate Ganzzahl Format Muss gültige Syntax für die Datumsformatierung haben
|
|
ADDMONTHS_VD(VDatum,AnzMonate) \@ Format Rückgabe: Datum |
Monate addieren mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel: |
|
ADDYEARS(Datum,AnzJahre) \@ Format Rückgabe: Datum |
Jahre addieren: Parameter: Datum Siehe obige Vorraussetzung AnzJahre Ganzzahl Format Muss gültige Syntax für die Datumsformatierung haben
|
|
ADDYEARS_VD(VDatum,AnzJahre) \@ Format Rückgabe: Datum |
Jahre addieren mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel: |
|
ADDWORKINGDAYS(Datum,AnzTage, \@ Format Rückgabe: Datum |
Werktage addieren: Parameter: Datum Siehe obige Vorraussetzung AnzTage Anzahl Werktage, Ganzzahl Feiertage Optional kann eine Liste von Feiertagen
vorgegeben werden, die bei der Berechnung berücksichtigt werden. Arbeitstage Arbeitstage pro Woche. Format Muss gültige Syntax für die Datumsformatierung haben Beispiel: |
|
ADDWORKINGDAYS_VD(VDatum,AnzTage, \@ Format Rückgabe: Datum |
Werktage addieren mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel: |
|
GETNEXTWORKINGDAY(Datum,Feiertage,Arbeitstage) \@ Format Rückgabe: Datum |
Nächster Werktag ab Datum: Parameter: Datum Siehe obige Vorraussetzung Feiertage Optional kann eine Liste von Feiertagen
vorgegeben werden, die bei der Berechnung berücksichtigt werden. Arbeitstage Arbeitstage pro Woche. Format Muss gültige Syntax für die Datumsformatierung haben Beispiel: |
|
SUBTRACTDAYS(Datum,AnzTage) \@ Format Rückgabe: Datum |
Tage subtrahieren: Parameter: Datum Siehe obige Vorraussetzung AnzTage Ganzzahl Format Muss gültige Syntax für die Datumsformatierung haben
|
|
SUBTRACTDAYS_VD(VDatum,AnzTage) \@ Format Rückgabe: Datum |
Tage subtrahieren mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel: |
|
SUBTRACTMONTHS(Datum,AnzMonate) \@ Format Rückgabe: Datum |
Monate subtrahieren: Parameter: Datum Siehe obige Vorraussetzung AnzMonate Ganzzahl Format Muss gültige Syntax für die Datumsforma-tierung haben
|
|
SUBTRACTMONTHS_VD(VDatum,AnzMonate) \@ Format Rückgabe: Datum |
Monate subtrahieren mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel: |
|
SUBTRACTYEARS(Datum,AnzJahre) \@ Format Rückgabe: Datum |
Jahre subtrahieren: Parameter: Datum Siehe obige Vorraussetzung AnzJahre Ganzzahl Format Muss gültige Syntax für die Datumsforma-tierung haben
|
|
SUBTRACTYEARS_VD(VDatum,AnzJahre) \@ Format Rückgabe: Datum |
Jahre subtrahieren mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel: |
|
SUBTRACTWORKINGDAYS(Datum,AnzTage,Feiertage,Arbeitstage) \@ Format Rückgabe: Datum |
Werktage subtrahieren: Parameter: Datum Siehe obige Vorraussetzung AnzTage Anzahl Werktage, Ganzzahl Feiertage Optional kann eine Liste von Feiertagen
vorgegeben werden, die bei der Berechnung berücksichtigt werden. Arbeitstage Arbeitstage pro Woche. Format Muss gültige Syntax für die Datumsformatierung haben Beispiel: |
|
DATEDIF(Datum1,Datum2,Einheit) Rückgabe: Ganzzahl |
Datumsdifferenz berechnen: Parameter: Datum1 Einheit Mögliche Werte: Y Differenz in kompletten Jahren M Differenz in kompletten Monaten D Differenz in Tagen MD Differenz zwischen den Tagen (in Tagen) YM Differenz zwischen den Monaten (in Monaten) YD Differenz zwischen den Tag.Monat (inTagen)
|
|
DATEDIF_VD(VDatum1,VDatum2,Einheit) Rückgabe: Ganzzahl |
Datumsdifferenz berechnen mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel:
|
|
GETDAYDIFF(Datum1,Datum2) Rückgabe: Ganzzahl |
Differenz in Tagen berechnen: Parameter: Datum1
|
|
GETDAYDIFF_VD(VDatum1,VDatum2) Rückgabe: Ganzzahl |
Differenz in Tagen berechnen mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel: |
|
GETMONTHDIFF(Datum1,Datum2) Rückgabe: Ganzzahl |
Differenz in Monaten berechnen: Parameter: Datum1
|
|
GETMONTHDIFF_VD(VDatum1,VDatum2) Rückgabe: Ganzzahl |
Differenz in Monaten berechnen mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel:
|
|
GETYEARDIFF(Datum1,Datum2) Rückgabe: Ganzzahl |
Differenz in Jahren berechnen: Parameter: Datum1
|
|
GETYEARDIFF_VD(VDatum1,VDatum2) Rückgabe: Ganzzahl |
Differenz in Jahren berechnen mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel:
|
|
GETFIRSTOFMONTH(Datum) \@ Format Rückgabe: Datum |
Erster Tag im Monat:
Parameter: Datum Siehe obige Vorraussetzung Format Muss gültige Syntax für die Datumsformatierung haben
|
|
GETFIRSTOFMONTH_VD(VDatum) \@ Format Rückgabe: Datum |
Erster Tag im Monat berechnen mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel:
|
|
GETFIRSTOFNEXTMONTH(Datum) \@ Format Rückgabe: Datum |
Ersten Tag des nächsten Monats:
Parameter: Datum Siehe obige Vorraussetzung Format Muss gültige Syntax für die Datumsformatierung haben
|
|
GETFIRSTOFNEXTMONTH_VD(VDatum) \@ Format Rückgabe: Datum |
Erster Tag des nächsten Monats berechnen mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel:
|
|
GETFIRSTOFQUARTER(Datum) \@ Format Rückgabe: Datum |
Erster Tag im Quartal:
Parameter: Datum Siehe obige Vorraussetzung Format Muss gültige Syntax für die Datumsformatierung haben
|
|
GETFIRSTOFQUARTER_VD(VDatum) \@ Format Rückgabe: Datum |
Erster Tag des Quartals berechnen mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel:
|
|
GETLASTOFMONTH(Datum) \@ Format Rückgabe: Datum |
Letzter Tag im Monat:
Parameter: Datum Siehe obige Vorraussetzung Format Muss gültige Syntax für die Datumsformatierung haben
|
|
GETLASTOFMONTH_VD(VDatum) \@ Format Rückgabe: Datum |
Letzter Tag des Monats berechnen mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel:
|
|
GETLASTOFLASTMONTH(Datum) \@ Format Rückgabe: Datum |
Letzter Tag des letzten Monats:
Parameter: Datum Siehe obige Vorraussetzung Format Muss gültige Syntax für die Datumsformatierung haben
|
|
GETLASTOFLASTMONTH_VD(VDatum) \@ Format Rückgabe: Datum |
Letzter Tag des letzten Monats berechnen mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel:
|
|
GETLASTOFQUARTER(Datum) \@ Format Rückgabe: Datum |
Letzter Tag im Quartal:
Parameter: Datum Siehe obige Vorraussetzung Format Muss gültige Syntax für die Datumsformatierung haben
|
|
GETLASTOFQUARTER_VD(VDatum) \@ Format Rückgabe: Datum |
Letzter Tag des letzten Quartals berechnen mit Valutadatum: Datumsvariablen
vom Typ Valutadatum werden immer mit 30 Tagen im Monat berechnet. Beispiel:
|
Regeln für die Verarbeitung von Text- und Datumsfunktionen
Verarbeitung von Variablen aus der DatenversorgungInnerhalb einer Text- bzw. Datumsfunktion kann der Name einer Variablen aus der Datenversorgung verwendet werden, um den Inhalt dieser Variablen zu verarbeiten.
Beispiel 1:
{ SET myVar "Mein Inhalt aus der Datenversorgung" }
{= LEFT(myVar; 4) }
Ergebnis: Mein
Der Inhalt der Variablen myVar darf beliebige Zeichen enthalten, auch
Sonderzeichen wie Anführungszeichen, Semikolon, Komma, Klammern, usw.
Beispiel 2:
Um Sonderzeichen, die sonst durch den RTF-Verarbeitung anderweitig interpretiert würden, korrekt verarbeiten zu können wird folgende Vorgehensweise empfohlen:
{ SET COMMA "," }
{ = SUBSTITUTE("123.45"; "."; COMMA; "1") }
Ergebnis: 123,45
Das Sonderzeichen wird hier per SET-Befehl einer Variablen zugewiesen, die anschließend im SUBSTITUTE-Befehl verwendet werden kann.
Beispiel 3:
{ SET myDatum "15.02.2015" }
{= ADDDAYS(myDatum, 14)\@ "tt.MM.jjjj }Ergebnis: 01.03.2015
Um Text- bzw. Datumsfunktionen verkettet zu verarbeiten, d.h. innerhalb einer Text-/Datumsfunktion mit dem Ergebnis einer anderen Text-/Datumsfunktion weiter zu arbeiten, ist der Umweg über Variablen notwendig.
Beispiel:
{SET a " abc "}
{SET b { = TRIM (a)} }
{ = LEFT(b;2)}
Ergebnis: abHier wird zunächst b mit dem Wert abc belegt (die Leerzeichen werden durch die Funktion TRIM entfernt). Dann wird b an die Funktion LEFT übergeben.
3.6. Behandlung von Feldschaltern
Die diversen Feldschalter, die im RTF verwendet werden können und vom CIB merge ausgewertet werden, sind im Detail in den RTF-Schulungsunterlagen erläutert:
Dynamische Dokumente - Band 1 - Grundlagen.pdf
Sie werden in diesem Leitfaden nur insoweit erwähnt, als sie für die Behandlung einiger Parameter von Bedeutung sind, z.B. \* CHARFORMAT.
3.7. Interessante Zusatzfunktionalitäten
CIB merge bietet in direkter Verbindung mit weiteren CIB Komponenten nützliche Zusatzfunktionalitäten für die dynamische Dokumentgenerierung bzw. für die Auswertung eines solchen Dokumentprojektes.
Dynamische Diagramme mit CIB chartDokumentanalysen CIB report&analyse
Dynamische Diagramme mit CIB chart
Oft sind die Tabellen in Rohtexten, die von CIB merge mit aktuellen Daten gefüllt werden, nicht aussagekräftig genug. Eine Ergänzung durch eine optische Geschäftsgrafik, also zum Beispiel um ein Linien- Torten- und Balkendiagramm ist hier wünschenswert. Natürlich müssen diese Grafiken dynamisch erzeugt werden, und zwar ebenfalls aus denselben aktuellen Daten der Anwendung.
CIB chart ist ein Modul zur Erstellung von dynamischen Geschäftsgrafiken, sowohl für Bildschirmoberfläche als auch zur Integration in Dokumente. Das Produkt CIB chart besteht aus
- dem CIB chart designer der dem Textorganisator die Erstellung der Graphikschablone ermöglicht
- dem CIB chart generator, der zur Laufzeit von CIB merge zur Diagrammerzeugung aus den angelieferten variablen Daten dient.
Der CIB chart designer ist eine eigene Windowsanwendung und dient dem Textorganisator zum Entwerfen einer Grafikvorlage mit Beispieldaten. Die Vorlage ist ein Enhanced Metafile (EMF) mit Erweiterungen in Form von CCR (=CIB chart Resource)Befehlen.
Dieses EMF zeigt die Beispielgrafik auf Basis von Testdaten mit dem vom CIB chart designer entworfenen Layout (Farben, Ausmaße und Beschriftungen). Es lässt sich mit den üblichen Grafiktools anzeigen, wie zum Beispiel die Vorschau im Windows Explorer.
In Microsoft Word lässt sich das EMF wie jede andere Grafikdatei über den Menüpunkt „Einfügen/Grafik/Aus Datei…“ komfortabel einfügen, positionieren und skalieren.
Die CCR Erweiterungen in dieser Grafik geben die im CIB chart designer getroffenen Einstellungen und Daten an CIB merge oder CIB format weiter. Damit kann zum Zeitpunkt der Dokumenterstellung die gewünschte Geschäftsgrafik mit den zu diesem Zeitpunkt verfügbaren Praxisdaten und dem vom Textorganisator vordefinierten Layout erstellt werden.
Dokumentanalysen CIB report&analyse
Viele Anwender erstellen sehr komplexe Dokumentprojekte. Um davon interne Projektreports zu erzeugen, oder auch Schwachstellenanalyse in der Dokumentmodellierung zu betreiben, gibt es die Möglichkeit eines „CIB report&analyse“.
Dieses Reporting Verfahren wird auch in die CIB workbench (AddIn unter MS-Office) integriert. Die Nutzung ist in einem eigenen ausführlichen Leitfaden beschrieben.
4. Datenversorgung
Neben der Interpretation von Feldbefehlen wie Bedingungen, Schleifen, Formeln und Einfügen-Anweisungen ist das Einsetzen von variablen Daten eine zentrale Aufgabe des CIB merge.
Es gibt dazu 4 verschiedene Varianten der Datenversorgung, die auch in gemischter Form zur Anwendung kommen können.
- Die versorgten Daten haben einen Aufbau im CSV Dateiformat (auch Verteilung auf mehrere CSV Dateien möglich)
- Es werden Daten über eine XML Datei versorgt
- Es werden aus einem Dokumentbaustein direkt SQL Abfragen getätigt
- Es werden aus einem Dokumentbaustein direkt UserExits angesteuert
4.1. CSV
AllgemeinHinweise zur Verwendung von Trenn- und Sonderzeichen in der Daten-CSV
Hinweise zu UTF-8 kodierten Daten-CSVs
Einzel-CSV-Datei
Multi-CSV-Datei
Allgemein
Bei den CSV Dateien handelt es sich um eine oder mehrere Text-Dateien, die die Namen der Eingabefelder und die zugehörigen Werte enthalten. Die Abkürzung CSV steht für "Comma Separated Values".
Die erste Zeile der Steuerdatei beinhaltet den sog. Steuersatz, der aus durch ";" getrennten Feldnamen besteht. Der Steuersatz kann beliebig viele, nur durch den freien Arbeitsspeicher begrenzte Feldnamen enthalten.
Jede weitere Zeile beinhaltet genau einen Datensatz. Ein Datensatz enthält, ebenfalls durch ";" getrennt, in der Reihenfolge der Feldnamen die jeweils einzufügenden Textbausteine bzw. Daten. Die Anzahl der Einträge im Datensatz muss mit der Anzahl der Feldnamen im Steuersatz übereinstimmen.
CIB merge kann eine einzelne CSV-Datei oder Multi-CSV-Dateien verarbeiten.
Verwendung mit CIB merge:
Der Parameter -d<Datensatzquelle> setzt die CSV-Datei für CIB merge, siehe Kapitel Parameter –d.
Hinweise zur Verwendung von Trenn- und Sonderzeichen in der Daten-CSV
Enthält eine einzufügende Textpassage ein Semikolon, ein Tabulatorzeichen oder ein Anführungszeichen, so muss die gesamte Textpassage in Anführungszeichen gesetzt werden. Anführungszeichen in einer Textpassage müssen dann verdoppelt werden. Um beispielsweise den Firmennamen Wäscherei "Weißer Riese" in einem Rohtext einzufügen, muss der Eintrag in der Steuerdatei folgendes Aussehen haben: ;"Wäscherei ""Weißer Riese""";.
CIB merge kann mit dem Parameter -T auch ein anderes Trennzeichen als ";" auf die CSV-Dateien anwenden, siehe Kapitel 6.14 Parameter –T.
Der Steuersatz kann auch in einer getrennten Steuersatzdatei bereitgestellt werden, die CIB merge mit dem Parameter -h gesetzt wird, siehe Kapitel 6.32 Parameter –h.Hinweise zu UTF-8 kodierten Daten-CSVs
Damit UTF-8 kodierte Datendateien mit Hilfe des CIB merge korrekt eingemischt werden, sind folgende Schritte notwendig:
1. Die
CIB merge par-Datei muss um den folgenden Parameter erweitert werden:
-putf-8
Dieser Parameter sagt aus, dass die Datendateien im UTF-8-Format kodiert sind.
2. Entfernen
der "byte order mark" (BOM) aus den Datendateien.
Da für die Verarbeitung der UTF-8 kodierten Datendateien durch CIB merge der
unter 1.) beschriebene Parameter verwendet wird, werden alle in der Datendatei
enthaltenen Zeichen nach UTF-8-Zeichensatz interpretiert. Dies gilt auch für eine
BOM. Damit kommt es zu Fehlermeldungen bei der Verarbeitung. Aus diesem Grund
müssen alle BOMs aus den verwendeten Datendateien entfernt werden.
Einzel-CSV-Datei

Beschreibung
Bei der Einzel-CSV-Datei werden den Eingabefeldern direkt ihre Werte zugeordnet. Der Anwender benutzt im Dokumentbaustein direkt den Feldnamen um auf einen Wert zuzugreifen.
|
Syntax |
Beispiel |
|
Kopfzeile 1.Datenzeile ... n.Datenzeile |
Feldname1;Feldname2 Wert11; Wert12 ... WertN1; WertN2 |
Multi-CSV-Datei

Beschreibung:
Mit Hilfe einer Multi-CSV-Datei können mehrere CSV-Dateien verwaltet werden. Sie enthält die Namen aller CSV-Dateien, die im aktuellen Mischlauf geladen werden sollen. Über die Felder in der Kopfzeile der Multi CSV Datei, erhält jede CSV-Datei einen Aliasnamen zugeordnet, über den dann im Dokument auf diese CSV Dateien zugegriffen werden kann.
Verwendung mit CIB merge
Für eine Multi CSV-Datenversorgung muss neben dem Parameter –d mit der Multi CSV Datei auch der Parameter -c gesetzt werden, siehe Kapitel 6.50 Parameter -c.
|
Syntax |
Beispiel |
|
Kopfzeile mit Aliasnamen Alle beteiligten CSV-Dateinamen |
Tabelle1; Tabelle2 Tab1.csv; Tab2.csv |

|
|
Syntax |
|
|
Syntax |
|
|
|
|
Tab1.csv |
|
|
Tab2.csv |
|
|
|
CSVName1; CSVName2 Wert11; Wert12 WertN1; WertN2 |
|
|
CSVName1; CSVName2 Wert11; Wert12 WertN1; WertN2 |
Vorteile gegenüber XML:
- Einfaches Format
- Einfache 1-n Beziehung
- Kleinere Dateigröße
4.2. XML
AllgemeinXML-Zusatzkomponenten
XML-Eigenschaften
Allgemein
CIB merge unterstützt seit der Version 3.9.x auch die Verarbeitung von Daten im XML Format. Es gibt für langjährige CIB merge Nutzer auch eine separate Dokumentation um ein Dokumentenprojekt, das bisher auf CSV Datenversorgung basierte, schrittweise in XML basierte Datenversorgung überzuführen.
XML-Zusatzkomponenten
Eine Unterstützung der XML Datenversorgung erfolgt mit Hilfe von zusätzlichen DLLs, die neben der CIB merge DLL installiert sein müssen. Diese Zusatzkomponenten sind in CIB merge Übergabe-Paketen automatisch enthalten und werden von CIB merge nur im Falle einer vorliegenden XML Versorgung dynamisch angezogen.
XML-Eigenschaften
XML-Dokumente besitzen einen physischen und einen logischen Aufbau.
Der physische Aufbau eines XML-Dokumentes besteht aus
Entitäten. Die erste Entität ist die Hauptdatei des XML-Dokuments. Weitere mögliche Entitäten sind über
Entitätenreferenzen
(&name; für das Dokument bzw. %name; für die Dokumenttypdefinition)
eingebundene Zeichenketten, eventuell auch ganze Dateien, sowie
Referenzen
auf Zeichenentitäten zur Einbindung einzelner Zeichen, die über ihre Nummer
referenziert wurden (&#Dezimalzahl;, oder &#xHexadezimalzahl;).
Eine XML-Deklaration wird optional verwendet, um XML-Version, Zeichenkodierung und Verarbeitbarkeit ohne Dokumenttypdefinition zu spezifizieren.
Eine Dokumenttypdefinition wird optional verwendet, um Entitäten sowie den erlaubten logischen Aufbau zu spezifizieren.
Der logische Aufbau eines XML-Dokumentes ist eine Baumstruktur und damit hierarchisch strukturiert. Als Baumknoten gibt es:
Elemente, deren physische Auszeichnung mittels
einem
passenden Paar aus Start-Tag (<Tag-Name>) und End-Tag (</Tag-Name>) oder
einem
Empty-Element-Tag (<Tag-Name />) erfolgen kann,
Attribute
als bei einem Start-Tag oder Empty-Element-Tag geschriebene
Schlüsselwort-Werte-Paare (Attribut-Name="Attribut-Wert") für Zusatz-Informationen
über Elemente (eine Art Meta-Information),
Verarbeitungsanweisungen
(<?Ziel-Name Parameter ?>, engl. Processing
Instruction)
Kommentare
(<!-- Kommentar-Text -->)
Text,
welcher als normaler Text oder in Form eines CDATA-Abschnittes (<![CDATA[ beliebiger
Text]]>) auftreten kann.
Ein XML-Dokument muss genau ein Element auf der obersten Ebene enthalten. Unterhalb von diesem Dokumentelement können weitere Elemente verschachtelt werden.

Der Parameter -d<Datensatzquelle> setzt die CSV-Datei für CIB merge, siehe Kapitel 6.11 Parameter –d.
XML-Datei
|
Syntax |
Beispiel |
|
<XMLKopf>XMLDaten1</XMLKopf> <XMLKopf>XMLDaten2</XMLKopf> <XMLKopf>XMLDaten3</XMLKopf> <XMLKopf>XMLDaten4</XMLKopf>
|
<Daten> <Benutzer>Tester</Benutzer> <Telefon>09/987 654</Telefon> <Strasse>Testweg 9</Strasse> <Ort>99999 Testhausen</Ort> </Daten> |
Multi-XML-Datei
Vorteile gegenüber CSV Nutzung:
- Weniger Dateien
- Arbeitet intern über Knoten
- Mit XPATH können RTF Strukturen vereinfacht werden
4.3. ODBC und SQL
AllgemeinODBC Versionen
SQL
SQL-Abfragen in der Multisteuerdatei
Dynamische Aliasbelegung
SQL-Abfragen im Feld “REF”
Allgemein
Über die im Programmverzeichnis zusätzlich hinterlegte CIB sql DLL sind SQL Zugriffe direkt aus CIB merge möglich. Das Ergebnis einer Abfrage (eine Tabelle) wird wie eine CSV-Steuerdatei verwendet. Anstatt eine Steuerdatei in der Multisteuerdatei zu bestimmen, wird dort eine Abfrage in SQL gestellt. Es ist auch möglich, bestehenden oder neuen Steuerdatei-Aliasen eine Steuerdatei oder SQL-Abfrage dynamisch zuzuweisen. Die dynamische Aliasbelegung ist auch ohne jegliche Steuerdatei oder Multisteuerdatei erlaubt. Weiterhin ist es möglich von einer Ergebnistabelle einer SQL-Abfrage den Wert der ersten Spalte und ersten Zeile sofort in den Rohtext einsetzen (ohne den Umweg über einen Alias, dem Feld “Nächster” und Variablen).
ODBC Versionen
Die CIB sql Dll verwendet intern die ODBC API Conformance Ebenen Core, Level 1 (z.B.: long data) und Level 2 (z.B.: scrollable Cursor). Die SQL Conformance Ebene Extended SQL Grammar wird für Datumsfelder benötigt. Vgl. hierzu ODBC SDK 2.10 Programmers Reference.
Es ist also darauf zu achten, dass die verwendeten ODBC-Versionen und Treiberversionen die entsprechenden Ebenen unterstützen.
Getestet sind die CIB sql-Funktionalitäten mit der ODBC 3.51 unter Windows NT 4.0. Hierbei kamen die Microsoft Jet Odbc-Treiber für MS Access zum Einsatz, die bei den entprechenden ODBC-Versionen mitgeliefert werden.
Diese Version unterstützt selbstverständlich auch joins (select auf mehrere Tabellen).SQL
SQL Zugriffe sollen direkt aus CIB merge
möglich sein. Das Ergebnis einer Abfrage (eine Tabelle) soll wie eine Steuerdatei
verwendet werden. Anstatt eine Steuerdatei in der Multisteuerdatei zu
bestimmen, wird eine Abfrage in SQL gestellt. Eine zweite Erweiterung soll
dynamisch bestehenden oder neuen Steuerdatei-Aliasen eine Steuerdatei oder
SQL-Abfrage zuweisen können. Eine dritte Erweiterung soll von einer
Ergebnistabelle einer SQL-Abfrage den Wert der ersten Spalte und ersten Zeile
sofort in den Rohtext einsetzen (ohne den Umweg über einen Alias, dem Feld
“Nächster” und Variablen). Eine vierte Erweiterung soll die dynamische
Aliasbelegung auch ohne Multisteuerdatei und eventuell sogar ohne normale
Steuerdatei erlauben.
SQL-Abfragen in der Multisteuerdatei
Der Eintrag eines Feldes in der Multisteuerdatei sieht üblicherweise so aus: “[;]Steuerdatei” oder “Kopfsatzdatei;Datensatzdatei”. Für SQL-Zugriffe gibt es die Möglichkeit der “SQL:Datenbank;Abfrage”.
Die neue Funktion ist nur mit einer DLL für SQL-Abfragen verfügbar.
Die Abfrage wird an die Datenbank geschickt. Weitere Zugriffe erfolgen mit den bekannten Befehlen für Steuerdateien mit unveränderter Bedeutung. Der einzige Unterschied ist die Datenquelle: Die Tabelle steht nicht in der Steuerdatei als Menge von Datensätzen, sondern in einer Datenbank. (Die Datenbank muss in den Systemeinstellungen für ODBC als Benutzer- oder Systemdatenquelle eingerichtet sein.)
Das folgende Beispiel stellt zwei Steuerdateien mit den Aliasen NormalDat und SqlDat zur Verfügung. Die Steuerdatei SqlDat enthält dabei zwei Spalten aus der Tabelle Tarife. Die Datenbank, die die Tabelle enthält wird über ODBC mit dem Namen ODBC-Tarifdatenbank zur Verfügung gestellt.
Multisteuerdatei:
NormalDat;SqlDat
“normal.csv”; “SQL:ODBC-Tarifdatenbank;SELECT TarifNr, TarifName FROM Tarife
ORDER BY TarifNr”
Dynamische Aliasbelegung
Der Befehl “Nächster” liest üblicherweise die nächste Datenzeile oder stellt die Leseposition vor den Anfang der Datenquelle. Möglich ist aber auch die Neudefinition oder Neuzuweisung eines Alias mit “NÄCHSTER DEF:Alias;Datenquelle”.
Der Alias wird neu bestimmt, wenn er noch nicht existiert. Falls der Alias bereits belegt ist, wird die damit verbundene Datenquelle geschlossen und der Alias neu belegt.
Die Datenquelle kann eine Steuerdatei oder eine SQL-Abfrage sein. Der Wert hinter dem Semikolon muss also wie ein Eintrag in der Multisteuerdatei aussehen.
Diese Funktion steht auch zur Verfügung, ohne dass in den an Merge übergebenen Parametern jegliche Steuerdatei oder Multisteuerdatei angegeben wurde.
Das Beispiel definiert dynamisch im Rohtext den Alias SqlDyn als die gesamte Tarife-Tabelle. Anschließend werden daraus bestimmte Felder tabellarisch aufgelistet.
Rohtext:
{ NÄCHSTER “DEF:SqlDyn;SQL:ODBC-Tarifdatenbank;SELECT * FROM Tarife ORDER BY TarifNr” }
|
Tarifnummer |
Name |
{ WENN { DATENSATZ ?SqlDyn } = 1 “
|
{ REF TarifNr \* Zeichenformat } |
{ REF TarifName \*Zeichenformat } |
{ NÄCHSTER SqlDyn }” \*solange }
Einschränkung: Zunächst soll diese Funktion nur zur Verfügung stehen, wenn eine Multisteuerdatei angegeben wurde. Eine spätere Erweiterung auf den Fall ohne jegliche Steuerdatei oder zumindest ohne Multisteuerdatei ist angestrebt.SQL-Abfragen im Feld “REF”
Der Befehl “Nächster” liest üblicherweise die nächste Datenzeile oder stellt die Leseposition vor den Anfang der Datenquelle. Möglich ist aber auch die Neudefinition oder Neuzuweisung eines Alias mit “NÄCHSTER DEF:Alias;Datenquelle”.
Der Alias wird neu bestimmt, wenn er noch nicht existiert. Falls der Alias bereits belegt ist, wird die damit verbundene Datenquelle geschlossen und der Alias neu belegt.
Die Datenquelle kann eine Steuerdatei oder eine SQL-Abfrage sein. Der Wert hinter dem Semikolon muss also wie ein Eintrag in der Multisteuerdatei aussehen.
Diese Funktion steht auch zur Verfügung, ohne dass in den an Merge übergebenen Parametern jegliche Steuerdatei oder Multisteuerdatei angegeben wurde.
Das Beispiel definiert dynamisch im Rohtext den Alias SqlDyn als die gesamte Tarife-Tabelle. Anschließend werden daraus bestimmte Felder tabellarisch aufgelistet.
Rohtext:
{ NÄCHSTER “DEF:SqlDyn;SQL:ODBC-Tarifdatenbank;SELECT * FROM Tarife ORDER BY TarifNr” }
|
Tarifnummer |
Name |
{ WENN { DATENSATZ ?SqlDyn } = 1 “
|
{ REF TarifNr \* Zeichenformat } |
{ REF TarifName \*Zeichenformat } |
{ NÄCHSTER SqlDyn }” \*solange }
Einschränkung: Zunächst soll diese Funktion nur zur Verfügung stehen, wenn eine Multisteuerdatei angegeben wurde. Eine spätere Erweiterung auf den Fall ohne jegliche Steuerdatei oder zumindest ohne Multisteuerdatei ist angestrebt.5. Technische Schnittstellen
Dieses Kapitel gibt einen kurzen Überblick über die verfügbare API und derer Parameter. Allgemein gilt, dass man über die Funktion cibmerge seine gewünschten Parameter in CIB merge setzt.
5.1. Funktionsprinzip
Die Schnittstellenphilosophie der CIB merge Komponente ist aus historischen Gründen noch abweichend von den anderen CIB Modulen gestaltet. Die Funktion zur Ausführung eines Mischlaufes bekommt noch direkt die Aufrufparameter noch direkt gesetzt.
Sehr wenige der Eigenschaften sind dabei zwingend erforderlich (z.B. Eingabedatei(strom)). Viele Parameter sind optional und ermöglichen dem Anwender eine zielgenaue Bestimmung seines Wunschergebnisses (z.B. Arbeitsverzeichnisse, Optimierung, Verschlüsselung, Defaultwerte,..).
5.2. cibmerge
Syntax:
int WINAPI cibmerge(int argc, char *argv[])
Aufrufparameter:
Die Aufrufparameter sind unter Aufrufparameter im Detail einzeln beschrieben.
Returnwert:
0 wenn alles erfolgreich ist
- 1 bei Benutzerabbruch
> 0 bei Fehlerabbruch
Fehlerbehandlung:
Ein Fehlercode größer 0 bedeutet, dass ein Problem aufgetreten ist und der Mischauftrag nicht ordentlich zu Ende geführt wurde. Ein Fehlercode kleiner 0 bedeutet, dass der Benutzer den Mischauftrag bewusst abgebrochen hat. Zusätzlich kann bei einem CIB merge Lauf eine Fehlerprotokolldatei geschrieben werden, die ausführliche Informationen zu dem aufgetretenen Fehler enthält.
Weitere Informationen zu den Fehlercodes und den Fehlerprotokolldateien finden Sie unter Fehlerbehandlung.
5.3. CibMergeVB
Dieser Funktion werden die einzelnen Parameter in einer langen Zeichenkette (=String) übergeben, wobei für das Trennzeichen ein Blank zu setzen ist, z.B.: „-iInput.rtf –oOutput.rtf -@1“
Syntax:
int WINAPI CibMergeVB(char* strParameters)
Returnwert:
Fehlerbehandlung:
Es ist keine besondere Fehlerbehandlung aktiv.
Fallback
Aufrufkonzepte

5.4. CibMergePFile
Dieser Funktion wird ein Parameter-Filename übergeben, z.B.: D:\Test.par.
Syntax:
int WINAPI CibMergePFile(char* szParamFile)
Returnwert:
Fehlerbehandlung:
Es ist keine besondere Fehlerbehandlung aktiv.
5.5. GetMergeVersion
Die Funktion liefert die aktuelle Versionsnummer der CIB merge DLL zurück. Damit können Sie in Ihrer Applikation sicherstellen, dass eine Mindestversion vorliegt, wenn Sie etwa spezielle Programmeigenschaften benutzen, die erst ab einem bestimmten Release zur Verfügung gestellt wurden.
Syntax:
unsigned long WINAPI GetMergeVersion()
Returnwert:
Der Returnwert liefert die aktuelle Versionsnummer der CIB merge DLL zurück. Der long-Wert liefert die Information in zwei Bereichen. Die ersten zwei Bytes enthalten den Versionszähler des Hauptreleases. Die Bytes 3 und 4 enthalten den zugehörigen aktuellen Releasezähler. Je nach Programmiersprache sind die Hi- und Lowbereiche entsprechend zu beachten (siehe Codebeispiele unten).
Fehlerbehandlung:
Es ist keine besondere Fehlerbehandlung aktiv.
6. Aufrufparameter im Detail
Im nachfolgenden Kapitel werden alle verfügbaren Aufrufparameter in alphabetischer Reihenfolge beschrieben. Viele der verfügbaren Parameter sind optional möglich und nicht zwingend zu setzen.
Parameter können sowohl als Einzelbuchstaben übergeben werden, wie z.B. -IEingabe.rtf. Es besteht aber ebenso die Möglichkeit ausgeschriebene Parameter zu übergeben, wie z.B. --inputfile=Eingabe.rtf.
Formal kann CIB merge Parameter in der Form (‚-’| ‚/’) ((«Buchstabe» | («Eigenschaft» ‚=’)) «Wert») | «Eigenschaft» aus der Kommandozeile entgegennehmen.
6.1. Allgemeine Hinweise
- Die Groß- und Kleinschreibung der Parameter spielt keine Rolle.
- Alle per Buchstaben versorgten Werte existieren auch als Langversion.
- Als Startzeichen für Parameter, die als Buchstabe übergeben werden, muss „-“ oder „/“ verwendet werden. Für ausgeschriebene Parameter lautet das Startzeichen „--“.
- Die ersten Parameter, die ohne Startzeichen übergeben werden, bekommen der Reihe nach die Parameterzeichen aus "IODH" zugewiesen (Input, Output, Daten).
- Nach Auswertung aller Parameter wird automatisch "/@" ausgeführt.
- «Eigenschaft» darf jedes beliebige Zeichen enthalten außer ‚=‘.
- Die Großschreibung der Eigenschaft spielt keine Rolle.
- Andere Zeichen als a-z, A-Z oder 0-9 werden wie ein ‚-‘ behandelt.
- Die Eingabe von
- (‚-‘ | ‚/‘) «Eigenschaft»
- steht für
- (‚-‘ | ‚/‘) «Eigenschaft» ‚=‘ «Wert»
- mit der leeren Zeichenfolge als Wert.
- Ein „+“ nach einem Dateinamen hängt an die bereits vorhandene Datei an
- ein „!“ nach einem Dateinamen überschreibt eine bereits vorhandene Datei (gilt für Parameter -o Ausgabedatei und Parameter –l Logdatei)
6.2. Hinweis Aufrufbeispiele
Die Parameterbeschreibung enthält jeweils Kurzhinweise zur Nutzung des Parameters aus einer bestimmten Umgebung.
Eine ausführlichere Beschreibung anhand von Anwendungsfällen finden sie im Kapitel „Anwendungsbeispiele“ Ausführliche Codebeispiele, für verschiedene Programmiersprachen, finden Sie im Kapitel „Schneller Einstieg“.
6.3. Übersicht der Abkürzungen für Aufrufparameter
|
Aufrufparameter |
Bedeutung |
Typ |
||
|
|
Deutsch |
Englisch |
||
|
: |
Setze |
--set |
Zuweisung von Variablenwerten |
Zeichenkette |
|
? |
Hilfe |
--help |
Hilfe (kurze Nutzungsanleitung) |
|
|
@ |
Mischen |
--merge |
Mischen |
Aufzählung |
|
@* |
Parameter[datei] |
--parameter[file] |
Parameterdatei |
Eingabedatei |
|
2 |
Word2 |
--word2 |
Kompatibilität zu WinWord 6 aus |
Ja/Nein |
|
6 |
Word6 |
--word6 |
Kompatibilität zu WinWord 6 ein |
Ja/Nein |
|
A |
Quellenverzeichnis |
--source-directory |
Verzeichnis zum Einfügen (Quellen) |
Zeichenkette |
|
B |
Abbruch |
--break |
Abbruchniveau (break-level) |
Aufzählung |
|
C |
(Meta|Multi)[steuerdatei] |
--(Meta|Multi)[datafile] |
Metasteuerdatei |
Ja/Nein |
|
D |
Daten|Steuerdatei |
--data[file] |
Steuerdatei |
Eingabedatei |
|
F |
Filtern |
--filter |
Filtern |
Aufzählung |
|
H |
Kopfsatz[datei] |
--header[file] |
Kopfsatzdatei |
Eingabedatei |
|
I |
Eingabe[datei] |
Input[file] |
Eingabedatei |
Eingabedatei |
|
K |
Felder-ausgeben |
--keep-fields |
Feldanweisungen ausgeben (keep fields) |
|
|
L |
Meldung(en|sdatei) |
Log[file] |
Datei für Meldungen |
Ausgabedatei |
|
M |
Meldung |
--message |
Meldung (Text ausgeben) |
Zeichenkette |
|
O |
Ausgabe[datei] |
Output[file] |
Ausgabedatei (RTF) |
Ausgabedatei |
|
P |
Zeichensatz |
--codepage |
Zeichensatz (codePage) |
Aufzählung |
|
Q |
Ausgabeverzeichnis |
--target-directory |
Arbeitsverzeichnis für Ausgabedateien |
Zeichenkette |
|
R |
Feldergebnisse |
--field-results |
Ergebnisse nicht schreiben (results) |
Aufzählung |
|
RTA |
Kurze-Token |
--short-tokens |
Kurze RTF-Token für Formatter (schneller) |
|
|
S |
HTML-Schalter |
--HTML-switches |
Schalter für HTML-Konvertierung |
|
|
T |
Trennzeichen |
--delimiter |
Trennzeichen für Steuerdateien |
Zeichenkette |
|
V |
Version |
--version |
Version |
|
|
W |
Window-handle |
--window-handle |
Ziel für Windowsmessages |
Zeichenkette |
|
X |
Dialog |
--dialog |
Abbruchdialog mit Fortschrittsanzeige |
|
|
Y |
Verschluesseln |
--encrypt |
Verschlüsselung |
Ja/Nein |
|
Z |
Komprimieren |
--compress |
Komprimierung |
Aufzählung |
6.4. Parameter --analyse
Der Parameter --analyse spielt nur für das Reportingtool „CIB report&analyse“ eine Rolle. Er bestimmt die statische Feldstruktur.
Syntax
--analyse=<Dateiname>
Beschreibung
Die Struktur, die mithilfe von --analyse bestimmt wird, kann zur weiteren Analyse oder Darstellung dienen. Die Meldung erfolgt in eine gesonderte Datei im Csv-Format. Es werden zunächst nur Ref, Mergerec, Next und Includetext (Ref, Datensatz, Nächster und Einfügentext) Felder bestimmt. Sie haben nur einen Parameter, der auch gemeldet wird. Dieser Parameter ist sinnvoll in dem Zusatzprojekt CIB report&analyse.
Die statische Feldstruktur ist die Reihenfolge der Felder wie aufgeschrieben.
Beispiel für statische Feldstruktur
{If {Mergerec ?Data} <> 0 „{Ref Name}{Next data}” \* Solange} meldet 1. If, 2. Mergerec, 3. Ref und 4. Next
Die dynamische Feldstruktur ist die Reihenfolge der Felder während der Auswertung.
Beispiel für dynamische Feldstruktur
{If {Mergerec ?Data} <> 0 „{Ref Name}{Next data}” \* Solange} meldet 1. If, 2. Mergerec, 3. Ref, 4. Next, 5. Mergerec, 6. Ref, 7. Next, 8. Mergerec, 9. Ref, 10. Next, … und so weiter, bis die Schleife beendet ist.
CSV-Dateien bestehen aus Zeilenschaltungen getrennte Datenzeilen, welche durch Komma, Tabulator oder Semikolon () getrennt sind. Die erste Zeile enthält die Spaltenüberschriften (Feldnamen). Jede Zeile muss die gleiche Anzahl Felder haben. Felder, die Feldtrenner oder Zeilenschaltungen oder Anführungszeichen im Inhalt haben, werden von Anführungszeichen umschlossen. Die inhaltlichen Anführungszeichen werden verdoppelt.
Beispiel: Auszug aus der Parameterdatei:
--logfile=!Felder.csv -mPfad;Feld;Wert --logfile=!cibmerge_Bausteine_analyse.log --source-directory=templates --outputfile=- --analyse=+Felder.csv # für jeden Text --inputfile=Basisbaustein.rtf -m@ --filter --inputfile=Bezug.rtf -m@ --filter ... für jeden RTF-Baustein... --inputfile=wurzelbaustein.rtf -m@ --filter -mdone
Dieses Beispiel besteht aus mehreren RTF-Bausteinen. Mit dem Parameter --analyse wird die Ausgabe „Felder.csv“ erzeugt. Diese Datei besitzt folgenden Aufbau:
Pfad;Feld;Wert
Eine genauere Beschreibung der Ausgabe ist im Anwendungsbeispiel Bausteine zu finden.
Hinweis:
Wegen der statischen Feldreihenfolge werden Felder in Schleifen nur einmal ausgegeben. Aus dem gleichen Grund werden Felder sowohl aus dem Dann- und Sonst-Zweig einer Wenn/If-Anweisung ausgegeben. Weil der Filter- und nicht der Mischvorgang die Ausgabe erzeugt, werden keine Felder berechnet und darum auch keine eingebetteten Texte (Includetext/Einfügentext) aufgelöst oder deren Felder ausgegeben.
Macht man eine zusammengehängte Feldanalyse über eine ganze Menge von Texten und Bausteinen, dann erhält man auch den Aufrufbaum mit den eingefügten Bausteinen. Mehrfach auftretende gleiche Felder werden auch mehrfach gemeldet. (Zum Beispiel zweimal {Ref Name})
6.5. Parameter --break
[-b]
Der Parameter --break verschiebt den Zeitpunkt, an dem CIB merge im Fehlerfall einen Mischvorgang abbricht.
Syntax
--break=<Abbruchniveau>
<Abbruchniveau>: all, loop, doc, par, never oder ok
Beschreibung
CIB merge bricht in verschiedenen Situationen mit Fehlermeldungen die Verarbeitung ab. Insbesondere bei Mischvorgängen kommt das zum Beispiel vor, wenn eine Variable eingesetzt wird, die nicht definiert ist.
In manchen Situationen ist es aber erwünscht, dass CIB merge nicht bei jedem Fehler sofort abbricht, sondern mit der Verarbeitung, wenn möglich, fortfährt. Dafür wurde in der Version 3.7.62 der Parameter B für break eingeführt.
Um die Stelle im Rohtext oder Textbaustein zu finden, gibt CIB merge nach der Fehlerursache auch die Folgefehler oder Folgesituationen mit aus. (Das entspricht einer Art "stack unrolling".) Dabei schreibt CIB merge noch die schließenden Klammern des Rohtexts, soweit das die Situation zulässt, damit der Text von anderen Anwendungen geöffnet werden kann.
<Abbruchniveau> bestimmt die Stelle, bis zu der fortgefahren oder ab der abgebrochen wird. Folgende Werte sind möglich:
|
Abbruchniveau |
Bedeutung |
|
all |
immer abbrechen, nie fortfahren (default) |
|
loop |
fortfahren bis zum Schleifenende, diese abbrechen (Serie und Parameter auch) |
|
doc |
fortfahren bis zum Dokumentenende, Serie abbrechen (Parameter auch) |
|
par |
fortfahren bis zum Ende der Serie (–@), keine weiteren Parameter mehr |
|
never |
fortfahren bis alle Parameter abgearbeitet sind, kein Abbruch, aber Fehlercode zurückgeben |
|
ok |
fortfahren bis alle Parameter abgearbeitet sind, kein Abbruch, OK zurückgeben |
|
CIB merge wird allerdings alle Fehler weiterhin in der Fehlerprotokolldatei ausgeben, nur mit dem Hinweis "==>fahre fort (Parameter "break" mit Niveau "XXX")" nach manchen Fehlern. |
|
Beispiele
--break=loop
Falls sich der Mischlauf gerade in einer Schleife befindet, wird diese ab dem Fehler nur noch bis zum Ende durchlaufen, also nicht wiederholt. Direkt anschließend wird der Mischvorgang abgebrochen.
--break=never
CIB merge führt ungeachtet aller auftretenden Fehler den Mischauftrag bis zum Ende durch und gibt den Fehlercode des ersten aufgetretenen Fehlers zurück.
Die Verwendung des Parameters mit diesen beiden Beispielbelegungen wird im Anwendungsbeispiel Bausteine veranschaulicht.
Hinweis
Unabhängig von --break=<Abbruchniveau> werden alle bis zum Ende oder Abbruch des Mischauftrags auftretenden Fehler in der Logdatei mit protokolliert.
6.6. Parameter --charformat
Mit --charformat kann angegeben werden, auf welche Felder, deren Ergebnisse keine eigene Formatierung liefern, CIB merge den Schalter \* CHARFORMAT anwenden soll.
Syntax
--charformat=<Option>
<Option>: off/none, auto/automatic oder plain-values-only
Beschreibung
Durch den Parameter --charformat wird festgelegt, bei welchen Feldern das Zeichenformat verändert werden soll, also bei welchen Feldern die Formatierung auf den Feldinhalt übertragen werden soll.
Durch den Parameter --charformat können die meisten der \* CHARFORMAT -Schalter entfallen, wodurch der Rohtext kürzer und lesbarer wird.
Wird bei einem Feld gezielt der Schalter \* NOCHARFORMAT gesetzt, so kann dadurch die Anwendung des Parameters --charformat auf dieses Feld verhindert werden (ab CIB merge Version 3.9.156).
Nicht formatbehaftet sind Feldinhalte aus CSV-Datei, aus Paramterdatei, Datum Felder mit Schalter sind formatbehaftet.
Für <Option> können folgende Werte gesetzt werden:
|
Option |
Bedeutung |
|
off oder none |
Das Zeichenformat wird nicht verändert, es sei denn es steht explizit \* CHARFORMAT im Feld. |
|
auto oder automatic |
Default-Einstellung |
|
plain-values-only |
Das Zeichenformat wird für Felder verändert, die Ergebnisse ohne eigene Formatierung liefern, egal ob diese Schalter haben oder nicht. |
Beispiel
--charformat=plain-values-only
Das Ergebnis von
{REF Vorname \* <cib-formfield type="text" info="Vorname" testvalue="Max" />}
erhält bei gesetztem --charformat=plain-values-only die Formatierung des REF Felds (in diesem Fall wird der Text fett geschrieben), obwohl dieses einen Schalter hat.
Die Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
Es gibt zum einen Feldinhalte mit formatbehafteten Werten und zum anderen Feldinhalte mit nicht formatbehafteten Werten.
Formatbehaftete Werte, die als Ergebnisse von Feldern in die Ausgabe kommen, brauchen den Feld-Schalter \* CHARFORMAT nicht, könnten damit aber gleichartig formatiert werden.
Beispiele für Feldinhalte
mit Formatierung sind:
{includetext}, eingefügte RTF-Inhalte, {REF} (wenn die Variable formatbehaftet
ist).
In diesen Fällen ist es normalerweise nicht sinnvoll den Parameter --charformat anzuwenden. Falls gewünscht. wird der \* CHARFORMAT - Schalter manuell gesetzt.
Werte, die CIB merge aus Feldern berechnet, können im
Eingabetext sichtbar vorkommen, völlig neu entstanden sein oder aus der
Steuerdatei stammen.
Beispiele für sichtbare Werte sind IF-Felder, deren Text aus einer der
Alternativen genau so kommt, wie es im Feld steht oder mit SET belegte Werte.
Sichtbare Werte sind formatbehaftet und nicht vom Parameter betroffen.
Durch Anwendung des Schalters \*NOFORMAT im SET-Befehl kann dieser Wert zum
nicht formatbehafteten Wert gemacht werden (ab CIB merge Version 3.9.174).
Nicht formatbehaftete Werte erscheinen standardmäßig in der Standardschriftart (Times Roman, Schriftgröße 10). Sie werden vom Parameter --charformat pauschal formatiert als hätte man jedesmal den Schalter /* CHARFORMAT angegeben.
Beispiele für Feldinhalte ohne Formatierung: {MERGEREC}, {date}, {=…}, Werte aus CSV, {REF} (wenn die Variable nicht formatbehaftet ist),.
In diesen Feldern kann bei gesetztem --charformat auf die \* CHARFORMAT - Schalter verzichtet werden.
Beispiele für erzeugte Werte sind Aktualdat oder die Ausdrucksberechnung mit „=“. Diese Werte sind nicht formatbehaftet und deshalb vom Parameter betroffen, wenn sie in der Ausgabe erscheinen.
Außerdem braucht der Schalter nicht angewendet zu werden, wenn bereits ein anderer Schalter die Formatierung verändert, zum Beispiel \@ „tt.MM.jj“. Hier wird die Formatierung der Maske verwendet und nicht das Zeichenformat. Auch für übergeordnete Felder gilt das. Ein IF-Feld mit \* CHARFORMAT braucht den Inhalt aus dem THEN- oder ELSE-Teil nicht mehr formatiert zu behandeln. Ein in einem der beiden Teile enthaltenes Feld wird sowieso mit dem Zeichenformat formatiert.
6.7. Parameter --chart-…
AllgemeinParameter --chart-output-format
Parameter --chart-source
Parameter --chart-target
Allgemein
Die --chart-Parameter ermöglichen das Erzeugen und Einfügen dynamischer Geschäftsgrafiken. CIB merge kann in diesem Fall die Grafikanweisung im Text belassen oder sie durch die aktualisierte Grafik ersetzen. CIB merge aktualisiert (überschreibt) die ursprüngliche Datei automatisch und entfernt die binären Grafikdaten aus dem Ergebnis, wenn die Grafikanweisung erhalten bleibt. Sonst bleibt die Datei unverändert erhalten und nur das Ergebnis wird anstatt der Anweisung in die RTF-Ausgabe eingebettet.
Außerdem besteht auch die Möglichkeit Grafik-Daten aus Nicht-Chart-Grafiken aus einer Datei ins RTF einzubetten. Dabei werden folgende Bildformate unterstützt: BMP bzw. DIB, EMF (Chart- und Nicht-Chart-Grafiken), PNG, JPG und WMF.
Es stehen
folgende Parameter zur Verfügung:
|
--chart-output-format |
Bestimmt das Ausgabeformat der Grafik (nur für Chart-Grafiken relevant) |
|
--chart-source |
CIB merge nimmt die Grafikbeschreibung aus der angegebenen Quelle |
|
--chart-target |
CIB merge schreibt die aktualisierte Grafik in das angegebene Ziel. |
Parameter --chart-output-format
CIB merge kann alle im CIB chart designer angebotenen Grafikformate als Ergebnis liefern. Soll die Grafikanweisung im Text belassen werden, kann entweder pauschal für alle Felder “--keep-fields” gesetzt werden oder in ausgewählten Grafikanweisungen der Schalter “\* lassen” eingefügt werden.
Der Parameter --chart-output-format bestimmt das Ausgabeformat der Grafik.
Syntax:
--chart-output-format=<Bildformat>
<Bildformat>: ccr (CIB chart resources), emf (Enhanced Metafile), oder emfccr (Enhanced Metafile erweitert um CIB chart resources (eingebettet))
Parameter --chart-source
Mit --chart-source wird angegeben, ob die Grafik aus den eingebetteten Daten, oder, im Falle einer Einfügengrafik-Anweisung, für den Inhalt der angegebenen Datei oder nie berechnet werden soll. ({\pict} nicht berechnen).
Syntax:
--chart-source=<Option>
<Option>:
auto, file/datei, none/ignore/ignorieren/kein/keine oder document/dokument/embed/embedded/einbetten/eingebettet
Für die Grafikquelle sind folgende Einstellungen für <Option> möglich:
|
Option |
Bedeutung |
|
none ignore/ignorieren kein/keine |
Keine {\pict}-Gruppe wird aktualisiert. |
|
file/datei |
CIB merge nimmt die Grafikbeschreibung aus der Datei, die in der {INCLUDEPICTURE} Anweisung angegeben wurde, wenn sich die {\pict}-Gruppe in deren Ergebnis befindet. |
|
document/dokument embed/embedded einbetten/eingebettet |
CIB merge nimmt die eingebetteten Daten als Quelle |
|
auto |
CIB merge nimmt vorranging die Datei. Wenn das nicht funktioniert, werden die eingebetteten Daten verwendet. (Standard und Vorbelegung) |
Parameter --chart-target
Der Parameter --chart-target bestimmt, wohin die Ausgabe der aktualisierten Grafikdaten geschrieben werden soll: in
das Dokument eingebettet oder über den alten Inhalt der angegebenen Datei.
Syntax:
--chart-target=<Option>
<Option>: auto, file/datei, none/ignore/ignorieren/kein/keine oder document/dokument/embed/embedded/einbetten/eingebettet
Beschreibung:
Für das Grafikziel sind folgende Einstellungen für <Option> möglich:
|
Option |
Bedeutung |
|
none ignore/ignorieren kein/keine |
Keine {\pict}-Gruppe wird aktualisiert. |
|
file/datei |
CIB merge schreibt die aktualisierten Grafikdaten in die Datei, die in der {INCLUDEPICTURE} Anweisung angegeben wurde, wenn sich die {\pict} Gruppe in deren Ergebnis befindet. |
|
document/dokument embed/embedded einbetten/eingebettet |
CIB merge bettet die Daten in das Zieldokument ein. |
|
auto |
CIB merge schreibt vorranging die Datei, wenn die {INCLUDEPICTURE} Anweisung mit --keep oder \* lassen in die Ausgabe kommt. Wenn das nicht funktioniert oder die Anweisung entfernt wird, werden die Daten eingebettet. (Standard und Vorbelegung) |
Ist keine Chart-Library verfügbar, werden Chart-Grafiken wie normale Grafiken behandelt.
Durch Setzen des Parameters --chart-target=embed werden, wenn --chart-source nicht „embed“ ist, die Bilddaten von EMF, JPG (JPEG), PNG, WMF und BMP bzw. DIP Grafikdateien in das Ergebnis-RTF eingebettet. Die Art des Dateiformats wird durch den Dateiinhalt, nicht durch den Suffix, bestimmt.
Beispiel:
--chart-source=file
--chart-target=embed
Die Grafikdaten stammen hier aus einer Datei. Alle Grafiken (Chart- und Nicht-Chart-Grafiken) sollen in das Ergebnis-RTF eingebettet werden.
Die Parameter werden im Anwendungsbeispiel Bausteine veranschaulicht.
Eine Übersicht liefert folgende Tabelle:
|
|
|
Nicht Chart |
Chart |
Chart |
Chart ak- |
Chart |
Chart |
|
ignore |
ignore |
– |
– |
– |
– |
– |
– |
|
ignore |
file |
– |
– |
– |
– |
– |
– |
|
ignore |
embed |
+ |
– |
+ |
– |
+ |
– |
|
ignore |
auto |
– |
– |
– |
– |
– |
– |
|
file |
ignore |
– |
– |
– |
– |
– |
– |
|
file |
file |
– |
– |
+ |
+ |
– |
+ |
|
file |
embed |
+ |
– |
+ |
+ |
+ |
– |
|
file |
auto |
– |
– |
+ |
+ |
+ (1) |
+ (2) |
|
embed |
ignore |
– |
– |
– |
– |
– |
– |
|
embed |
file |
– |
+ |
– |
+ |
– |
+ |
|
embed |
embed |
– |
+ |
– |
+ |
+ |
– |
|
embed |
auto |
– |
+ |
– |
+ |
+ (1) |
+ (2) |
|
auto |
ignore |
– |
– |
– |
– |
– |
– |
|
auto |
file |
– |
+ (3) |
+ (4) |
+ |
– |
+ |
|
auto |
embed |
+ |
+ (3) |
+ (4) |
+ |
+ |
– |
|
auto |
auto |
– |
+ (3) |
+ (4) |
+ |
+ (1) |
+ (2) |
(1) „Keep“ - Schalter nicht gesetzt
(2) „Keep“ - Schalter gesetzt
(3) Daten konnten nicht aus der Datei gelesen werden
(4) Daten konnten aus der Datei gelesen werden
6.8. Parameter --codepage
[-p]
Der Parameter --codepage steuert den aktuell benutzten Zeichensatz für die Steuerdatei (Zur Steuerdatei siehe Parameter --datafile bzw. --headerfile).
Syntax
--codepage=<Zeichensatz>
<Zeichensatz>: pca, pc, utf-8 oder ansi
Beschreibung
Wenn der Parameter --codepage nicht angegeben ist und somit kein Zeichensatz für die Steuerdatei definiert ist, gilt als Default die Deklaration in der RTF Eingabedatei (z.B. \rtf1\ansi). Als Zeichensätze sind pca, pc, utf-8 oder ansi zulässig.
Beispiele
--codepage=pca
Hier wird in den CSV-Dateien ein anderer Zeichensatz verwendet (hier pca). Das muss über den Parameter --codepage angegeben werden.
Die Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
Hinweis:
Für die RTF-Bausteine wird immer die in der RTF Eingabedatei spezifizierte Codepage benutzt.
Siehe auch die Hinweise zu UTF-8 codierten Datendateien im Kapitel „Hinweise zu UTF-8 kodierten Daten-CSVs“.
6.9. Parameter --colors
Mit dem Parameter --colors können Optimierungen, die für Farbtabellen im Kopf des RTF-Dokuments durchgeführt werden, wahlweise abgeschaltet werden.
Syntax
--colors=<Option>
<Option>: keep, expand, optimize oder minimal
Beschreibung
Jedes RTF-Dokument enthält im Kopf Farbtabellen. Dafür muss CIB merge Zeit für den Abgleich wegen Einfügungen oder zur Optimierung aufwenden. Dieser Abgleich oder diese Optimierungen interessieren aber nicht jeden Anwender. Daher sind sie wahlweise mit dem Parameter --colors abschaltbar.
Mögliche Werte für <Option> sind:
|
Option |
Bedeutung |
|
keep |
Die Haupt-Farbtabelle bleibt unverändert, auch wenn die eingefügten Textbausteine eigentlich eine Erweiterung fordern oder unbenutzte Farben entfernt werden könnten. |
|
expand |
Die Haupt-Farbtabelle wird um Farben erweitert, wenn die eingefügten Textbausteine eine Erweiterung fordern. Unbenutzte Farben werden nicht entfernt. |
|
optimize |
Die Haupt-Farbtabelle wird um Farben erweitert, wenn die eingefügten Textbausteine eine Erweiterung fordern. Unbenutze Farben werden entfernt wenn sie nicht zu den 17 Standardfarben von MS Word gehören. |
|
minimal |
Die Haupt-Farbtabelle wird um Farben erweitert, wenn die eingefügten Textbausteine eine Erweiterung fordern. Unbenutzte Farben werden entfernt, auch wenn sie zu den 17 Standardfarben einschließlich „automatisch“ gehören. MS Word hat meist die Farbe „automatisch“ an der Stelle null und danach 16 Standardfarben an den Stellen eins bis 16. Anschließend kommen die zusätzlichen Farben. |
Beispiel
--colors=expand
Neue Farben, die in RTF-Bausteinen verwendet werden, werden in die Farbtabelle aufgenommen und unbenutzte Farben werden nicht entfernt. Somit findet keine Optimierung statt.
Die Verwendung des Parameters wird im Anwendungsbeispiel Bausteine veranschaulicht.
6.10. Parameter --compress
[-z]
Ist der Parameter --compress gesetzt, komprimiert CIB merge die Ausgabe-Datei nach zlib-Verfahren.
Syntax
--compress=<Komprimierungsgrad>
<Komprimierungsgrad>: 1-9
Beschreibung
Wird der Parameter --compress zur Komprimierung eingesetzt, müssen die Prioritäten zwischen der Optimierungszeit und dem Ergebnis für den gewünschten Einsatz abgewägt werden. Mit mehr Zeitaufwand entstehen sehr kleine Ergebnisse, eine möglichst schnelle Komprimierung erreicht dagegen ein durchaus kleines, aber nicht das minimale Ergebnis.
Dem Parameter --compress kann deshalb vom Anwender ein ganzzahliger Wert von 1 bis 9 übergeben werden. Der Defaultwert ist 6.
Beispiele
--compress
CIB merge komprimiert mit dem Default-Komprimierungsgrad 6.
--inputfile=Optimierung_in.rtf --outputfile=!Optimierung_out.rtf --compress=9
Die Datei wird so stark wie möglich komprimiert. Daraus ergibt sich eine kleinere Dateigröße, dafür aber eine etwas erhöhte Zeitdauer für diesen Mischvorgang.
Die Verwendung dieses Parameters wird zusammen mit anderen Optimierungs-Parametern im Anwendungsbeispiel Lückentext veranschaulicht.
6.11. Parameter --datafile
[--data/-d]
Mit dem Parameter --datafile wird die Datenquelle angegeben.
Syntax
--datafile=<Dateiname>
Beschreibung
Als Datenquelle kann sowohl eine Datei im CSV- als auch im XML-Format angegeben werden.
Sind die Daten auf mehrere Datendateien verteilt, so ist hier die Multisteuerdatei anzugeben und zusätzlich der Parameter --multidatafile zu setzen.
Beispiele
Single-CSV über Parameterdatei
--datafile=Adresse.csv
Die Daten befinden sich in einer einzigen Datenquelle namens Adresse.csv.
Diese Art der Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
Multi-CSV über Parameterdatei
--datafile=multi.csv --multidatafile
Die Daten sind auf mehrere Datendateien verteilt, die in der Datei multi.csv angegeben werden. Um zu definieren, dass es sich um eine Multi-CSV handelt, muss zusätzlich der Parameter --multidatafile gesetzt werden.
Diese Art der Verwendung des Parameters wird im Anwendungsbeispiel Serienbrief veranschaulicht.
Ist außerdem der Parameter --target-directory gesetzt, werden die multi.csv und alle weiteren Datendateien in diesem Verzeichnis erwartet:
--target-directory=csv
Im Anwendungsbeispiel Bausteine wird --datafile zusammen mit --target-directory verwendet.
Multi-XML über Parameterdatei
--headerfile=XML:Daten_mitAlias.xml --datafile=/root/multi --multidatafile
Der Parameter --datafile gibt hier den XPath zu den Multiknoten an.
Dieser Zusammenhang wird im Anwendungsbeispiel Serienbrief verdeutlicht.
Hinweis:
Die erste Zeile der Datensatzquelle beinhaltet den sog. Steuersatz, der aus durch ";" getrennten Feldnamen besteht. Dieser Steuersatz kann auch in einer getrennten Steuersatzquelle bereitgestelt werden, die mit dem Parameter --headerfile gesetzt wird.
6.12. Parameter --default-mode
[--defaultmodus/--default-modus]
Der Parameter --default-mode stellt einen Mechanismus bereit, um für jede Variable einen Ersatzwert (Default) zu bestimmen, falls die Variable undefiniert bzw. leer ist.
Syntax
--default -mode=<Value>
<Value>: -/off/aus/no/none/kein/keiner/nein, undefiniert/undefined/+, leer/empty oder beides/alles/both/all/voll/full
Beschreibung
Der Parameter --default-mode ist nur in Kombination mit dem Parameter --default-prefix zu verwenden. Dieser definiert den Prefix, der vor einen Variablennamen gestellt wird. Beim Auswerten des REF-Feldes wird festgestellt, ob der Wert ein Kandidat für das Default-Verhalten ist, sonst wird der Wert oder ein Fehler ausgegeben. Das Default-Verhalten tritt bei folgenden Bedingungen ein:
- „Variable ist undefiniert und Verhalten entsprechend gewählt“ oder „Variable ist definiert und leer und Verhalten entsprechend gewählt“. Trifft eine der Bedingungen zu, so setzt sich der Variablenname aus dem Default-Präfix und dem alten Namen zusammen. Ist so ein Default wiederum nicht gesetzt, gibt es noch einen für alle gemeinsam. Erst wenn auch der nicht existiert, wird der übliche Fehler gemeldet, dass eine Variable nicht definiert ist. Es ist möglich zwischen 'kein Default', 'Default für Leer', 'Default für undefiniert' und 'Default für beides' zu wählen. Der Standard ist „kein Default“.
Mögliche Werte für <Value> sind:
|
Option |
Bedeutung |
|
-/off/aus/no/none/kein/keiner/nein |
Standard, kein Default |
|
undefiniert/undefined/+ |
Default bei undefinierten Variablen |
|
leer/empty |
Default bei leeren Variablen |
|
beides/alles/both/all/voll/full |
Default in beiden Fällen |
Beispiel
--default-mode=all
Es wird nach einem passenden Default-Wert gesucht, wenn eine Variable leer oder undefiniert ist.
Die Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
6.13. Parameter --default-prefix
Der Parameter definiert ein Präfix für Variablen, d.h. er stellt dem Variablennamen ein Präfix voran.
Syntax
--default-prefix=<prefix>
Beschreibung:
Mit dem Parameter --default-prefix kann somit einer Variablen ein Ersatzwert (Default) zugewiesen werden. Als gemeinsamer Default gilt die Variable, die genau so heißt wie das Default-Präfix. Die Standardvorbelegung ist „Default.“. Dieser Parameter ist in Kombination mit dem Parameter --default-mode anzugeben.
Beispiel 1
--default-mode=all --default-prefix=Default.
Hier wird nach einem Default-Wert gesucht, wenn eine Variable nicht durch die Datenversorgung gefüllt werden kann, weil die Variable nicht existiert oder leer ist. Um den Default-Wert zu ermitteln, wird der Variablen das Präfix „Default.“ vorangestellt.
Die Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
Beispiel 2
--default-mode=undefined --default-prefix=Default.
Variablen-Belegung: A=Anton, B=Berta, C=, Default.B=Bruno, Default.C=Cäsar, Default.D=Dora, Default.=Mama
Der Default-Modus definiert für undefinierte Variablen das Präfix „Default.“. Die Variablen liefern folgende Werte:
REF A liefert Anton
REF B liefert Berta
REF C liefert „“
REF D liefert Dora
REF E liefert Mama, weil Default.E nicht definiert ist. Wäre„Default.“ nicht belegt, gäbe es hier einen Fehler mit der Meldung, dass E nicht belegt ist).
Ist der Default-Modus auf all oder empty gesetzt (--default-mode=all/--default-mode=empty) so liefert die Auswertung für REF C Cäsar.
REF D liefert mit einem Default-Mode off (--default-mode=off) oder empty (--default-mode=empty) einen Fehler.
6.14. Parameter --delimiter
[-t]
Der Parameter --delimiter definiert ein anderes Trennzeichen für die Steuerdateien. Das Standardtrennzeichen für die Steuerdateien ist ";".
Syntax
--delimiter=<Trennzeichen>Beispiel
--delimiter=,
CIB merge interpretiert jetzt das Komma-Zeichen statt dem Semikolon als Trennzeichen.
Die Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
6.15. Parameter --destination-colorschememapping
(ab CIB merge Version 3.12.2)
Über diesen Parameter kann gesteuert werden, ob das \*\colorschememapping in die Ausgabedatei übernommen wird.
Syntax
--destination-colorschememapping=<Option>
<Option>: keep, remove oder merge
Beschreibung
Als <Option> sind folgende Werte möglich:
|
Option |
Bedeutung |
|
keep |
Alle im Ursprungs-RTF gefundenen colorschememapping Informationen
werden unverändert in das Ausgabe-RTF übernommen. |
|
remove |
Keine colorschememapping
Informationen werden in das Ausgabe-RTF übernommen. |
|
merge |
Dieser Parameterwird derzeit wie keep behandelt. |
6.16. Parameter --destination-datastore
(ab CIB merge Version 3.12.2)
Über diesen Parameter kann gesteuert werden, ob das \*\datastore in die Ausgabedatei übernommen wird.
Syntax
--destination-datastore=<Option>
<Option>: keep, remove oder merge
Beschreibung
Als <Option> sind folgende Werte möglich:
|
Option |
Bedeutung |
|
Keep |
Alle im Ursprungs-RTF gefundenen datastore Informationen
werden unverändert in das Ausgabe-RTF übernommen. |
|
remove |
Keine datastore Informationen werden in das Ausgabe-RTF
übernommen. |
|
merge |
Dieser Parameterwird derzeit wie keep behandelt. |
6.17. Parameter --destination-themedata
(ab CIB merge Version 3.12.2)
Über diesen Parameter kann gesteuert werden, ob das \*\themedata in die Ausgabedatei übernommen wird.
Syntax
--destination-themedata=<Option>
<Option>: keep, remove oder merge
Beschreibung
Als <Option> sind folgende Werte möglich:
|
Option |
Bedeutung |
|
Keep |
Alle im Ursprungs-RTF gefundenen themedata Informationen werden unverändert in das Ausgabe-RTF
übernommen. |
|
remove |
Keine themedata Informationen werden
in das Ausgabe-RTF übernommen. Mögliche Referenzen auf die themedata Informationen
aus der Fonttabelle werden dabei nicht entfernt. |
|
merge |
Dieser Parameterwird derzeit wie keep behandelt. |
6.18. Parameter --dialog
[-x]
Der Parameter --dialog zeigt während des Mischvorganges einen Prozentbalken am Bildschirm an (nichtmodale Dialogmaske). Über diese Maske kann mit Hilfe des Abbrechen-Buttons der Mischlauf gestoppt werden.
In Ausnahmefällen wird die Fortschrittsanzeige vom System nicht im Vordergrund gestartet. Mit dem Schalter top setzt sich die Fortschrittsanzeige beim Start explizit in den Vordergrund.
Syntax
--dialog
Beispiel
--dialog=top
Die Fortschrittsanzeige setzt sich beim Start des Mischvorgangs in den Vordergrund.

Im Anwendungsbeispiel Serienbrief wird die Fortschrittsanzeige verwendet, um eine Endlosschleife abzubrechen.
6.19. Parameter --directory-…
Die directory-Parameter ermöglichen eine dateilose Dateneingabe. Dies geschieht über Einträge (virtuelle Dateien) in virtuellen Verzeichnissen.
Es stehen folgende Parameter zur Verfügung:
|
--directory-log |
schreibt den Inhalt einer virtuellen Datei mit Beginn- und Endezeile in die Fehlerausgabe |
|
--directory-read |
legt im virtuellen Verzeichnis den Inhalt einer Datei ab |
|
--directory-remove |
entfernt den angegebenen Eintrag aus dem virtuellen Verzeichnis, |
|
--directory-set |
definiert eine virtuelle Datei |
|
--directory-set-inline |
dateilose Dateneingabe mit der Parameterdatei |
|
--directory-write |
schreibt den Inhalt aus einem virtuellen Verzeichnis in eine Datei |
6.20. Parameter --directory-set-inline
Der Parameter --directory-set-inline ermöglicht eine dateilose Dateneingabe mit der Parameterdatei.
Syntax
--directory-set-inline=<virtueller Dateiname> VAR1;VAR2 VALUE1;VALUE2 VALUE3;VALUE4 … end-of-file
Beschreibung
Der Parameter --directory-set-inline liest die Zeilen der Parameterdatei bis zur Endezeile (end-of-file). Das heisst, alle Zeilen, die zwischen --directory-set-inline und end-of-file stehen werden als Inhalt von <virtueller Dateiname> interpretiert. Der Inhalt wird im virtuellen Verzeichnis unter <virtueller Dateiname> eingetragen. Existiert bereits ein Inhalt, so wird dieser überschrieben.
Beispiel
Ausschnitt aus einer Parameterdatei mit dateiloser Dateneingabe:
--datafile=daten.csv --directory-set-inline=daten.csv Var1;Var2;Var3 Wert1.1;Wert1.2;Wert1.3 Wert2.1;Wert2.2;Wert2.3 end-of-file
Der Parameter --directory-set-inline=daten.csv zeigt die dateilose Dateneingabe an. Die folgenden Zeilen werden eingelesen bis zur Zeile „end-of-file“ und bilden somit den Inhalt der virtuellen Datei mit dem Namen daten.csv.
6.21. Parameter --directory-log
Der Parameter --directory-log schreibt den Inhalt einer virtuellen Datei mit der Beginn- und Endezeile in die Fehlerausgabe.
Die Beginnzeile ist --directory-set-inline.
Die Endezeile ist „end-of-file“.
Syntax
--directory-log=<virtueller Dateiname>
Beispiel
--logfile=!merge.log --datafile=daten.csv --directory-set-inline=daten.csv var1;var2;var3 1.1;1.2;1.3 2.1;2.2;2.3 3.1;3.2;3.3 end-of-file --inputfile=directory-set-inline.rtf --directory-log=daten.csv
Der Inhalt sowie die Beginn- und Endzeile werden in das Logfile geschrieben. Der Inhalt der Logdatei merge.log sieht wie folgt aus:
--directory-set-inline=daten.csv
var1;var2;var3
1.1;1.2;1.3
2.1;2.2;2.3
3.1;3.2;3.3
end-of-file
6.22. Parameter --directory-read
Der
Parameter --directory-read legt im virtuellen Verzeichnis den Inhalt einer
Datei ab. Dabei wird ggfs. der bereits existierende Inhalt überschrieben.
Dieser Parameter wird auch für den Merge-Recombine verwendet. (ab CIB merge Version 3.9.181)
Syntax
--directory-read=<Dateiname>
oder
--directory-read=<virtueller Dateiname>=<Dateiname>
oder (ab CIB merge Version 3.9.181)
--directory-read=cibrec-snippetN.rtf=<Dateiname>
N=0,1,2….
Beschreibung
Für <Dateiname> sind alle Angaben möglich, die auch mit dem Parameter --inputfile erlaubt sind. Die Kurzschreibweise für den Parameter lautet --directory-read=<Dateiname>, wobei der <Dateiname> auch als <virtueller Dateiname> verwendet wird.
Hinweis: Enthält der <Dateiname> die Zeichen „+“ „-“ „!“, so werden diese als Schalter interpretiert und nicht als Bestandteil des Dateinamens angesehen.
Etwa
angegebene Schalter +/-/! usw. werden nicht in den Namen übernommen.
Merge-Recombine (ab CIB merge Version 3.9.181):
Die CIB viewer (CIB view&rec und CIB jview&rec2) bieten die
Möglichkeit, in CIB REC-Feldern Textpassagen zu erfassen bzw. zu editieren.
Diese Textpassagen werden von den CIB viewern in sogenannten
RTF-Snippet-Dateien abgelegt. Nach Abschluss des Editiervorgangs eines
Dokuments werden durch den CIB merge die RTF-Snippets in das Dokument eingemischt
und als neues Ausgabe-RTF gespeichert.
Die Übergabe der Snippet-Dateien an den CIB merge erfolgt durch den Parameter
„--directory-read=cibrec-snippetN.rtf=<Dateiname>“, falls sich die Dateien auf
Platte befinden.
Beispiel
--directory-read=inNeu.log=in.log --directory-write=inNeu.log=!out.log
Der Parameter --directory-read legt den Inhalt der Datei in.log in die virtuelle Datei inNeu.log ab. Im nächsten Schritt wird die virtuelle Datei mit dem Namen inNeu.log genommen und der Inhalt in out.log geschrieben.
6.23. Parameter --directory-remove
Der Parameter --directory-remove entfernt den angegebenen Eintrag aus dem virtuellen Verzeichnis, oder alle Einträge, wenn kein Name angegeben wird.
Syntax
--directory-remove
oder
--directory-remove=<virtueller Dateiname>
Beispiel
--directory-remove=name
Der Eintrag „name” wird aus dem Verzeichnis entfernt.
--directory-remove
Alle Einträge werden aus dem Verzeichnis entfernt.
6.24. Parameter --directory-set
Der
Befehl --directory-set=<virtueller Dateiname> definiert eine virtuelle
Datei unter <virtueller Dateiname> und ist im Arbeitsspeicher von
CIB merge abgelegt. Eine sinnvolle Anwendung ist zum Beispiel CSV-Daten
dateilos zu übergeben. Für eine Übergabe in einer Parameterdatei ist der Aufrufparameter
--directory-set-inline.zu verwenden.
Dieser Parameter wird auch für den Merge-Recombine verwendet. (ab CIB merge Version 3.9.181)
Syntax
--directory-set=<virtueller Dateiname>
oder (ab CIB merge Version 3.9.181)
--directory-set=cibrec-snippetN.rtf={\rtf1 ...}
N=0,1,2….
Beschreibung
Merge-Recombine (ab CIB merge Version 3.9.181):
Die CIB viewer (CIB view&rec und CIB jview&rec2) bieten die
Möglichkeit, in CIB REC-Feldern Textpassagen zu erfassen bzw. zu editieren.
Diese Textpassagen werden von den CIB viewern in sogenannten RTF-Snippets
abgelegt. Nach Abschluss des Editiervorgangs eines Dokuments werden durch den
CIB merge die RTF-Snippets in das Dokument eingemischt und als neues Ausgabe-RTF
gespeichert.
Die Übergabe der Snippet-Dateien an den CIB merge erfolgt durch den Parameter
„--directory-set=cibrec-snippetN.rtf={\rtf1
...}“, falls
die Übergabe im Speicher erfolgt.
6.25. Parameter --directory-write
Der Befehl --directory-write=<virtueller Dateiname>=<Dateiname> schreibt den Inhalt von <virtueller Dateiname> aus dem virtuellen Verzeichnis in die Datei <Dateiname>. Etwa angegebene Schalter +/-/! usw. werden nicht in den Namen übernommen.
Syntax
--directory-write=<virtueller Dateiname>=<Dateiname>
Beispiele
--directory-set=out=out.log --directory-write=out.log=!out.log
Die virtuelle Datei mit dem Namen out.log wird genommen und der Inhalt in out.log geschrieben
- Gegenüberstellung: dateibehaftete und dateilose
Dateneingabe
Ausgehend von einem klassischen dateibehafteten Beispiel werden Alternativen mit den eben genannten Mitteln vorgestellt.
Die Ausgabe des RTF kann dateilos mit in anderen Dokumenten beschriebenen Mitteln erfolgen und wird hier nicht erwähnt!
- Java Mischauftrag (Merge-Job) und Abholung des
Fehlertextes und der Fehlernummer
Dateneingabe mit Datei:
Die daten.csv soll in die Eingabe input.rtf gemischt werden. Die Ausgabe heißt output.rtf. Fehler kommen in merge.log. Alle Dateien befinden sich im Dateisystem unter Verzeichnis test.
JCibMergeJob t_Job = new JCibMergeJob();
t_Job.initialize();
t_Job.setProperty(ICibMergeJob.PROPERTY_WORKSPACE, "test\\");
t_Job.setProperty(ICibMergeJob.PROPERTY_ERRORFILE, "merge.log");
t_Job.setProperty(ICibMergeJob.PROPERTY_DATAFILE, "daten.csv");
t_Job.setProperty(ICibMergeJob.PROPERTY_INPUTFILE, "input.rtf");
t_Job.setProperty(ICibMergeJob.PROPERTY_OUTPUTFILE, "output.rtf");
t_Job.execute();
int error =
((Integer)t_Job.getProperty(ICibMergeJob.PROPERTY_ERROR)).intValue();
if(error > 0)
{
String errortext = (String)t_Job.getProperty(ICibMergeJob.PROPERTY_ERRORTEXT);
}
Dateneingabe ohne Datei:
Nur daten.csv soll im ersten Schritt dateilos übergeben werden. Der Inhalt sei in der String Variable csv_data. Hierfür wird folgende zusätzliche Property gesetzt. (Der Rest bleibt unverändert)
t_Job.setProperty(ICibMergeJob.PROPERTY_DICTIONARY_SET, "daten.csv=" + csv_data);
- Mischauftrag über Parameterdatei (Java, C++ oder
COModSuite)
Dateneingabe mit Datei:
Inhalt der Datei merge.par:
-L!merge.log -V -Ddaten.csv -Iinput.rtf -O!output.rtf -M@ -@1 -MEnde
Logdatei bestimmen
Version melden
Daten-, Ein- und Ausgabedateien bestimmen
Dateinamen melden
Einzeldokument mischen
Rufen Sie „cibmrg32.exe -@merge.par“ auf, um den Auftrag zu starten.
Dateneingabe ohne Datei:
Analog zum Fall in Java ist das in der Parameterdatei auch möglich:
Die Parameterdatei merge.par muss um folgende Angabe ergänzt werden (Rest bleibt unverändert)
--dictionary-set-inline=daten.csv Var1;Var2;Var3…
Wert1.1;Wert1.2;Wert1.3… Wert2.1;Wert2.2;Wert2.3… … end-of-file
- Auftrag aus C++
Dateneingabe mit Datei:
const char *const arguments[]= { „cibmerge“, „-L!merge.log“, „-Ddaten.csv“, „-Iinput.rtf“, „-O!output.rtf“, 0 }; cibmerge(sizeof(arguments)/sizeof(*arguments) – 1, arguments);
Dateneingabe ohne Datei:
Hier werden die Daten in Stringkonstanten übergeben. Eine bessere Möglichkeit wäre es, sie über stringstreams der STL dynamisch zusammenzustellen:
Die Argumente müssen um folgende Angabe erweitert werden (Rest bleibt unverändert):
„--dictionary-set=daten.csv\n“ „Var1;Var2;Var3…\n“ „Wert1.1;Wert1.2;Wert1.3…\n“ „Wert2.1;Wert2.2;Wert2.3…\n“ „…\n“
6.26. Parameter --docproperty
(ab CIB merge Version 3.9.181)
Durch diesen Parameter können Dokument-Eigenschaften gesetzt und eingemischt werden.
Syntax
-- docproperty=[key]=[value]
Beschreibung
Durch den Parameter--docproperty ist es dem Anwender möglich, die Dokument-Eigenschaften des Ausgabedokumentes zu definieren.
Es werden sowohl die vordefinierten Werte (Autor, Titel, usw.), als auch selbstdefinierte Dokument-Eigenschaften unterstützt.
Die Einsatzmöglichkeiten sind z.B.:
- Einfache und zentrale Sicherstellung der Dokumenteigenschaften der Ausgabedokumente, bevor diese in das Kundenumfeld gelangen (einheitlicher Autor für alle ausgehenden Dokumente).
- Nutzung der Dokumenteigenschaften zum Transport von Zusatzinformationen
6.27. Parameter --encrypt
[-y]
Der Parameter --encrypt erzeugt ein kryptisiertes Ausgabeformat, das von weiteren CIB-Komponenten (beispielsweise CIB format/output) weiterverarbeitet werden kann.
Syntax
--encrypt
Beschreibung
Die Verschlüsselung, die der Parameter --encrypt anwendet, basiert auf einem CIB-eigenen CC9-Algorithmus. Dieser soll „Unlesbarkeit“ der Bausteine bzw. Zwischenergebnisse ermöglichen und somit eine „unmittelbare“ inhaltliche Manipulation verhindern.
Die verschlüsselte Datei kann mit MS-Office Versionen nicht geöffnet werden.
Beispiel
--encrypt
Die Ausgabedatei liegt hier verschlüsselt vor.
Der Parameter wird im Anwendungsbeispiel Lückentext verwendet
6.28. Parameter --field-nesting-level-limit
(ab CIB merge 3.12.10)
Über den Parameter --field-nesting-level-limit kann die Schachtelungstiefe von Feldbefehlen beschränkt werden.
Syntax
--field-nesting-level-limit=number
number=Zahl zwischen 0 und n
Beschreibung
Über den Parameter --field-nesting-level-limit kann die Schachtelungstiefe von Feldbefehlen beschränkt werden.
Default-Wert ist „0“, d.h. die Schachtelungstiefe ist nicht beschränkt.
Bei Werten größer 0 bricht der CIB merge mit Fehler 810 ab, wenn diese Schachtelungstiefe erreicht ist.
Achtung: Der Parameter ist nur beim Merge-Template-Combine wirksam!
Beispiel
--field-nesting-level-limit=10
CIB merge bricht mit Fehler 810 ab, wenn eine Schachtelungstiefe von 10 erreicht ist.
6.29. Parameter --field-results
[-r / -rp]
Über den Parameter --field-results kann gesteuert werden, ob im Rich Text Format alle Field-Results entfernt und damit die Größe der Ausgabedatei reduziert wird.
Syntax
--field-results
oder
--field-results=p
Oder (ab CIB merge 3.9.183)
--field-results= Keepswitch
Beschreibung
MS Word erzeugt Field-Results im RTF. Diese Einträge werden von den CIB office Modulen in den meisten Fällen nicht benötigt. Der Parameter --field-results entfernt diese Einträge.
Für bestimmte Grafikobjekte benötigt CIB format in Einzelfällen (z.B. Grafik über Text positionieren) bestimmte Teile der Field-Results zur Positionierung und Skalierung. Der Schalter p "print" (kurz: -rp) veranlasst CIB merge, diese Daten zu erhalten. Zusätzlich werden weitere Einträge aus dem RTF entfernt, die im Falle einer Weiterverarbeitung mit CIB format nicht benötigt werden. Im Zweifelsfall sollte --field-results=p eingesetzt werden, da die Ausgabedateigröße gegenüber --field-results nur geringfügig steigt und CIB format sicher alle benötigten Informationen zur Verfügung stehen.
--field-results wird im Regelfall zur Optimierung der Dateigröße eines RTF-Projekts vor Test und Auslieferung eingesetzt. Vom CIB Support erhalten Sie auf Anfrage ausführliche Informationen zur Optimierung von RTF-Projekten.
Keepswitch (ab CIB merge 3.9.183):
Es gibt Anwendungsfälle,
bei denen die Datenversorgung eines Dokuments über mehrere Mischläufe erfolgen
muss, weil zum Zeitpunkt des ersten Laufs noch nicht alle Informationen
vorhanden sind. Dann müssen die Feldinhalte der vorhergehenden Mischläufe für
die nachfolgenden erhalten bleiben.
Der Parameter „keepswitch“ greift bei Variablen (REF-Felder) im
Eingabe-Dokument des CIB merge, die mit einem KEEP/LASSEN-Schalter versehen
sind. Gibt es für diese Variablen keine Datenversorgung, so wird bei Ihnen ein
vorhandenes Feldergebnis beibehalten.
Beispiel
--inputfile=wurzelbaustein.rtf --outputfile=!..\result\wurzelbaustein_FieldResults.rtf --field-results=p --filter=f
CIB merge mischt keine Feldinhalte ein (--filter=f), entfernt alle Field-Results, die für CIB format keine Bedeutung haben (--field-results=p) und schreibt entsprechend die Ausgabedatei.
Die Verwendung dieses Parameters wird im Anwendungsbeispiel Bausteine veranschaulicht.
Hinweis:
Mit --field-results erzeugte RTF-Dateien sollten nicht mehr mit MS Word bearbeitet werden. Dokumente mit skalierten oder über den Text positionierten Grafiken können in MS Word nicht mehr korrekt angezeigt und bearbeitet werden. Beim Speichern mit MS Word geht außerdem der Vorteil der verkleinerten Dateigröße wieder verloren.
Die Dateigröße der Ausgabedatei kann durch die CIBrtf-Ausgabe mit --short-tokens und eine komprimierte Ausgabe mit --compress zusätzlich verringert werden.
6.30. Parameter --filter
[-f / -ff]
Mit dem Parameter --filter wertet CIB merge die Feldinhalte nicht aus, sondern liest nur die Eingabedatei und schreibt nach den gesetzten Parametern die Ausgabedatei.
Syntax
--filter
oder
--filter=f
Beschreibung
Mit --filter werden die Feldinhalte nicht ausgewertet, aber geparst und übersetzt. Dies kann mit dem Schalter f = "fast" verhindert werden. --filter=f filtert also schneller (ohne Syntaxprüfung des RTF-Stromes), --filter kann dafür Fehler in den Feldern eher entdecken.
--filter=f (oder auch –ff) wird meistens zur Optimierung oder Verschlüsselung von RTF-Projekten vor Test und Auslieferung eingesetzt, siehe Kapitel Übersicht: Optimierung, Verschlüsselung und Komprimierung und Parameter --field-results.
Beispiel
--inputfile=Optimierung_in.rtf --outputfile=!Optimierung_out.rtf --optimize --short-tokens --compress=9 --filter=f
Hier werden einige Optimierungen (siehe jeweiliger Parameter) durchgeführt und dabei keine Feldinhalte eingemischt.
Die Verwendung dieses Parameters zusammen mit Optimierungs-Parametern wird im Anwendungsbeispiel Lückentext veranschaulicht.
Im Anwendungsbeispiel Bausteine wird der Parameter zusammen mit --field-results verwendet.
6.31. Parameter --fonts
Mit dem Parameter --fonts können Optimierungen, die für Schriftartentabellen im Kopf des RTF-Dokuments durchgeführt werden, wahlweise abgeschaltet werden.
Syntax
--fonts=<Option>
<Option>: keep, optimize, expand oder adjust
Beschreibung
Jedes RTF-Dokument enthält im Kopf Schriftartentabellen. Dafür muss CIB merge Zeit für den Abgleich wegen Einfügungen oder zur Optimierung aufwenden. Mit dem Parameter --fonts können diese Optimierungen wahlweise abgeschaltet werden. Der Standard ist adjust. Das bezieht sich auch auf den gesamten Kopf.
Für <Option> sind folgende Werte möglich:
|
Option |
Bedeutung |
|
keep |
Die Haupt-Schriftartentabelle bleibt unverändert, obwohl eingefügte Textbausteine zusätzliche Schriftarten enthalten. Unbenutzte Schriftarten werden nicht entfernt. |
|
optimize |
Die Haupt-Schriftartentabelle wird nicht erweitert. Unbenutzte Schriftarten werden entfernt. |
|
expand |
Die Haupt-Schriftartentabelle wird um die Schriften erweitert, die in eingefügten Textbausteinen verwendet werden. Unbenutzte Schriftarten werden nicht entfernt. |
|
adjust |
Standardeinstellung. Die Haupt-Schriftartentabelle wird um die Schriften erweitert, die in eingefügten Textbausteinen verwendet werden. Unbenutzte Schriftarten werden entfernt. |
Beispiel
--fonts=keep
Obwohl eingefügte Textbausteine zusätzliche Schriften enthalten, werden diese nicht in die Haupt-Schriftartentabelle aufgenommen. Unbenutzte Schriftarten werden nicht entfernt. Dies ist zum Beispiel dann sinnvoll, wenn ein Dokument gedruckt werden soll, der Drucker aber nicht alle verwendeten Schriftarten kennt.
Die Verwendung des Parameters wird im Anwendungsbeispiel Bausteine veranschaulicht.
6.32. Parameter --headerfile
[--header/-h]
Der Parameter --headerfile kann bei der Datenversorgung mit XML eingesetzt werden. Er zeigt auf die gesetzte Datendatei.
Syntax
--headerfile=<Kopfsatzdatenquelle>
Beschreibung
Wird --headerfile in Kombination mit dem Parameter --multidatafile verwendet, so gibt --datafile den XPath zu den Multiknoten an. Eine Verwendung des Parameters mit einer CSV-Datenversorgung wird nicht empfohlen.
Beispiel Multisteuerdaten aus XML
--headerfile=XML:Daten_mitAlias.xml --datafile=/root/multi --multidatafile
XML-Datei:
<root>
<multi>
<Kunden>XML:$(this);/root/data/Kunden/Kunde</Kunden>
<Einzelposten>XML:$(this);/root/data/Posten/Einzelposten</Einzelposten>
</multi>
<data>
<Kunden> <Kunde>
<Vorname>Franz</Vorname> <Name>Meier</Name>
<Strasse>Teststr. 4</Strasse>
<PLZ>12345</PLZ> <Ort>Musterdorf</Ort>
<Geschlecht>M</Geschlecht>
<KundenNr>9898989</KundenNr> <AuftragsNr>111111-2</AuftragsNr>
<Betrag>999</Betrag>
</Kunde>
weitere Kunden ......
</Kunden>
<Posten>
<Einzelposten>
<KundeAuftragsNr>111111-2</KundeAuftragsNr> <Bezeichnung>Artikel1</Bezeichnung>
<Betrag>999</Betrag> </Einzelposten>
weitere Einzelposten....
</Posten>
</data>
</root>
Die Multi-Knoten befinden sich in der Datei Daten_mitAlias.xml. Die Aliasnamen ergeben sich aus dem Knotennamen(Kunden, Einzelposten), die mit dem angegebenden XPath definiert sind. Die Aliasdefinitionen sind die Knoteninhalte (XML:$(this);/root/data/Kunden/Kunde, XML:$(this);/root/data/Posten/Einzelposten). Der Spezialdateiname XML:$(this) zeigt auf die aktuelle Datei.
Die Verwendung des Parameters wird im Anwendungsbeispiel Serienbrief veranschaulicht.
6.33. Parameter --help
[-?]
Der Parameter --help zeigt die Hilfe-Seite (z.B. in Logdatei).
Syntax
--help
Beschreibung
Mit diesem Parameter gibt man die automatische Programmhilfe aus. Es handelt sich dabei um eine aktuelle Kurzübersicht über alle in der verwendeten Version verfügbaren Aufrufparameter.
Durch die zusätzliche Angabe des Logdateiparameters wird die Hilfe in eine Datei umgeleitet. Eine Ausgabe auf der Konsole ist unter Windows nicht möglich.
Beispiel: CIB merge als Programm
cibmrg32 --logfile=!hilfe.txt --help
Die Hilfe wird in die Datei hilfe.txt umgeleitet. Ein Auszug aus dieser Hilfeausgabe ist im Anwendungsbeispiel Lückentext zu finden.
6.34. Parameter --inline-is-not-this
[--inline-is-not-this]
(Ab CIB merge 3.9.190)
Durch Verwendung des Parameters „--inline-is-not-this“ kann das Verhalten von CIB merge Versionen älter als 3.9.166 betreffend $(inline) wieder hergestellt werden.
Syntax
--inline-is-not-this
Beschreibung
Bis CIB merge Version 3.9.165 wurde intern auf dem Bezeichner $(inline) gearbeitet, d.h. es wurde ein Kontext erzeugt. Ab CIB merge Version 3.9.166 wird das $(inline) durch den tatsächlichen Dateinamen ersetzt.
Damit funktionieren Konstrukte mit "--directory-read=inline=<Dateiname>" ($(inline) wird auf eine Datei umgeleitet) und gleichzeitig „REF "DAT:XML:$(inline);relativ/Pfad” ” nicht mehr, da für relative XPATH-Ausdrucke kein Kontext mehr vorhanden ist. Es müsste mit absoluten XPATH-Befehlen gearbeitet werden.
Durch Verwendung des Parameters „--inline-is-not-this“ wird intern ein Kontext erzeugt und damit die Verwendung relativer XPATH-Befehle ermöglicht.
6.35. Parameter --html-switches
[--html/-s]
Mit dem Parameter --html-switches versteht CIB merge auch erweiterte REF-Anweisungen, die Zusatzschalter für die Ausgabe von Formularen mit CIB format/html enthalten.
Syntax
--html-switches
Beschreibung
CIB Merge versteht standardmäßig nur die in MS Word definierten Schalter. Mit dem Parameter --html-switches werden auch die Zusatzschalter für die Ausgabe von Formularen interpretiert. Eine Spezifikation dieser Zusatzschalter finden Sie in der CIB format Hilfe, die Sie von den Kontaktadressen oder unter http://www.cib.de unter Support | Dokumentation erhalten.
Beispiel
--html-switches
Der Parameter bewirkt, dass CIB merge beispielsweise folgenden Zusatzschalter versteht.
{REF \* <cib-formfield type="text" info="Vorname" testvalue="Max" />}
Dies ergibt mit CIB format/html ein einzeiliges Textfeld.
Die Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
6.36. Parameter --inputfile
[--input/-i]
Mit dem Parameter--inputfile wird die Eingabedatei angegeben, bei mehreren Bausteinen muss dort der Wurzelbaustein angegeben werden.
Syntax
--inputfile=<Inputfile>
Beispiel
--inputfile=Anschreiben_in.rtf
Die Eingabedatei Anschreiben_in.rtf wird im aktuellen Verzeichnis gesucht.
Die Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
Hinweis
Geben Sie den Pfad für den Wurzelbaustein nicht bei --inputfile, sondern getrennt mit --source-directory an. So werden auch die inkludierten Bausteine in diesem Verzeichnis automatisch gefunden, absolute Pfadangaben sind für die RTF-Bausteine nicht mehr nötig.
Dies wird im Anwendungsbeispiel Bausteine verdeutlicht.
6.37. Parameter --input-language
Der Parameter --input-language bestimmt für den Schalter „numerisches Format“ (\#) die Ländereinstellung.
Syntax
--input-language=<Sprache>
<Sprache>: englisch/english oder german/deutsch
Beschreibung
Derzeit gültige Werte sind „english“/“englisch“ und „german“/“deutsch“. Die Standardeinstellung ist „german“. Ist der Wert auf „german“ eingestellt, so interpretiert CIB merge Punkte in der Zahlenformatangabe als Anweisung, die auszugebende Zahl mit Tausenderpunkten zu gliedern oder mit Ersatzzeichen der eingestellten Ausgabesprache. Kommata werden als Unterteilung zwischen Vor- und Nachkommastellen gewertet. Auch hier wird das Zeichen ausgegeben, dass zur eingestellten Ausgabesprache passt. Ist der Wert auf „english“ eingestellt, so werden Punkte und Kommata umgekehrt interpretiert. Die Ausgabe erfolgt dennoch unabhängig davon in der Ausgabesprache.
Die Zahlen müssen in der CSV-Datei deutsch angegeben werden. Sie werden in {=...} Feldern auch nur auf Deutsch verstanden. Ebenso erwartet der Parser des Schalters \#, dass das Feldergebnis vor Anwendung des Schalters die Zahl auf Deutsch enthält.
Beispiele
- Englisches RTF mit englischen Formatierungen
--input-language=english
Das Anschreiben ist auf Englisch verfasst und somit auch die Angabe des Zahlenformats. Diese Tatsache wird über den Parameter --input-language angegeben.
Dies wird im Anwendungsbeispiel Lückentext veranschaulicht.
- Rechenbeispiele
--input-language=german
Sei nun in einem RTF-Dokument folgende Anweisung vorhanden:
{=1234 + 1 \# #.####0,00€}
Ergebnis: 1.235,00€
Die Anweisung
{=12,34 + 1 \# #.####0,00€}
liefert das Ergebnis: 13,34€
--input-language=english
Sei nun in einem RTF- Dokument folgende Anweisung vorhanden:
{=1234 + 1 \# #,####0.00€}
Ergebnis: 1.235,00€
Die Anweisung
{=12,34 + 1 \# #,####0.00€}
liefert das Ergebnis: 1.334,00€
Der
Grund für das vom Deutschen abweichende Ergebnis liegt in der Interpretation
der Trennzeichen im Englischen:
Tausender-Komma und Dezimal-Punkt
6.38. Parameter --intermediatefile
[--intermediate]
Der Parameter --intermediatefile ermöglicht das Speichern von Zwischenergebnissen in einer Datei oder im Speicher.
Syntax
--intermediatefile=<String>
<String>: RAM, - oder <Dateiname>
Beschreibung
Durch Angabe von RAM als Zwischenergebnisdatei, wird keine Datei auf dem Dateisystem erzeugt. Dies ist nützlich, wenn auf einem System kein (schreibender) Zugriff auf das Dateisystem möglich ist. Das Schreiben einer Zwischendatei benötigt unter Umständen viel Zeit, die so eingespart werden kann.
Mögliche Werte für <String> sind folgende:
|
String |
Bedeutung |
|
RAM |
Schreibt Zwischenergebnisse in den Speicher. Es werden keine Zwischenergebnisse in einer Datei auf dem Dateisystem geschrieben. |
|
<Dateiname> |
Schreibt Zwischenergebnisse in die Datei „<Dateiname>.rtf“. |
|
- |
Deaktiviert explizit per Parameter die Zwischenergebnisse. |
Beispiel
--intermediatefile=Zwischenergebnis
Der Parameter --intermediatefile schreibt das Zwischenergebnis in die Datei Zwischenergebnis.rtf .
Hinweis
Die Angabe der Datei für die Zwischenergebnisse kann alternativ auch über die Umgebungsvariable “CIB_MRGINTERMEDIATE” erfolgen.
Der Parameter kann über die "AUTOSTART" – Funktionalität (ab Merge 3.9.104 und 3.8.130) für alle Mischläufe gesetzt werden. Dazu kann die "AUTOSTART" – Parameterdatei per Hex-Editor direkt in die Binär-Datei gepatcht werden oder die Umgebungsvariable "CIB_MRGAUTOSTART" mit dem Parameterdateinamen gesetzt werden.
6.39. Parameter --keep-fields
[-k]
Der Parameter --keep-fields führt den Mischvorgang fort, auch wenn nicht alle Felder über die Datenversorgung gefüllt werden können.
Syntax
--keep-fields=<Option>
<Option>: unresolved-ref, unresolved-ref-as-formfield, all oder none
Beschreibung
Wenn während der Datenversorgung nicht alle Felder gefüllt werden können (Informationen liegen noch nicht vor), dann ist es möglich CIB merge mittels des Parameters --keep-fields dazu zu veranlassen, diese Felder zu übergehen, ohne den Mischvorgang abzubrechen.
Für <Option> sind folgende Werte möglich:
|
Option |
Bedeutung |
|
unresolved-ref |
alle nicht versorgten Ref-Felder bleiben in der Ausgabedatei erhalten |
|
unresolved-ref-as-formfield |
alle nicht versorgten Ref-Felder werden durch {\rtf...formtext...} ersetzt |
|
all |
Alle Felder werden in der Ausgabedatei behalten, bei mit Daten versorgten Feldern wird das Ergebnis entsprechend befüllt. |
|
none |
Defaultwert. Parameter --keep-fields findet keine Anwendung. |
Beispiel
--logfile=!cibmerge_Bausteine_KeepFields.log --target-directory=csv --source-directory=..\templates --inputfile=wurzelbaustein.rtf --outputfile=!..\result\KeepFields_out.rtf --datafile=multi_undef.csv --multidatafile --charformat --keep-fields=unresolved-ref
Hier wird in einem der RTF-Bausteine die Variable kont_kontoart verwendet. Für diese Variable erfolgt jedoch keine Versorgung aus den Datenquellen. Durch den Parameter --keep-fields=unresolved-ref wird der Mischvorgang fortgeführt, das REF-Feld für kont_kontoart bleibt in der Ausgabedatei KeepFields_out.rtf erhalten.
Die Verwendung des Parameters wird im Anwendungsbeispiel Bausteine verdeutlicht.
Hinweis:
Wenn CIB merge wegen des Parameters keep bzw. wegen des Schalters \* LASSEN ein Feld als solches schreibt (ohne die Daten einzumischen), erscheint eine textuelle Fehlermeldung im Logfile. Diese Aktion wird nicht als Fehler gewertet und erzeugt daher keinen Fehlerrückgabewert.
(Ab CIB merge Version 3.9.181)
Bei Steuerung über Feldschalter gibt es außer \* LASSEN noch die Möglichkeiten:
\*keepalways: Diese Feldanweisung bleibt immer im Ausgabedokument stehen.
\*keepuntilresolved: Diese Feldanweisung bleibt solange im Ausgabedokument bestehen, bis sie versorgt ist.
Tipp:
Dieser Parameter eignet sich als --keep-fields=unresolved-ref hervorragend zur Realisierung einer Restdatenerfassung mit den CIB office Modulen. Fragen Sie den CIB Support nach weiteren Informationen für Ihren Anwendungsfall.
6.40. Parameter --keep-refs-if-in-list
(ab CIB merge Version 3.9.186)
Über den Parameter --keep-refs-if-in-list kann der Keep-Schalter von außen für die angegebenen Felder gesetzt werden.
Syntax
--keep-refs-if-in-list=<Variable>|<Variable-List>
<Variable-List>=<Varable>;<Varable>;…
Beschreibung
Über den Parameter --keep-refs-if-in-list kann dem CIB merge ein einzelnes oder auch eine Liste von Feldern übergeben werden, für die ein Keep-Schalter zu setzen ist. Diese REF-Felder werden im gemischten Dokument belassen, ein eventueller Variablenwert wird im Fieldresult gespeichert. Kommt ein REF-Feld in einem RTF mehrfach vor, bleiben alle in der Ausgabe erhalten.
Bereits im RTF enthaltene Keep-Schalter zu diesen Feldern bleiben davon unberührt und haben Vorrang.
6.41. Parameter --LicenseCompany
Name des Lizenznehmers für den in Verbindung mit dem Parameter LicenseKey lizenzpflichtige Funktion(en) des CIB merge freigeschalten werden.
Syntax
--LicenseCompany"=<Name>6.42. Parameter --LicenseKey
Lizenzschlüssel, welcher in Verbindung mit dem richtigen Lizenznehmer lizenzpflichtige Funktion(en) freischaltet..
Syntax
--LicenseKey=4e4e-c1c1-123456786.43. Parameter --lists
Mit dem Parameter --lists können Optimierungen, die für Listentabellen im Kopf des RTF-Dokuments durchgeführt werden, wahlweise abgeschaltet werden.
Syntax
--lists=<Option>
<Option>: keep, optimize, expand oder adjust
Beschreibung
Jedes RTF-Dokument enthält im Kopf Listentabellen
(\listtable, \listoverridetable). Bei der Verarbeitung dieser Tabellen muss
CIB merge Zeit für den Abgleich von Einfügungen und zur Optimierung
aufwenden.
Über den Parameter --lists können diese Optimierungen wahlweise abgeschaltet
werden.
Für <Option> sind folgende Werte möglich:
|
Option |
Bedeutung |
|
keep |
Die Listentabelle des Wurzel-Dokuments wird unverändert in die Ausgabe übernommen, auch wenn eingefügte Textbausteine zusätzliche Listen enthalten. Unbenutzte Listen werden nicht entfernt. |
|
optimize |
Die Listentabelle des Wurzel-Dokuments wird nicht um Listentabellen aus eingefügten Textbausteinen erweitert. Unbenutzte Listen werden entfernt. |
|
expand |
Die Listentabelle des Wurzel-Dokuments wird um Listentabellen aus eingefügten Textbausteinen erweitert. Unbenutzte Listen werden nicht entfernt. |
|
adjust |
Die Listentabelle des
Wurzel-Dokuments wird um Listentabellen aus eingefügten Textbausteinen
erweitert. Unbenutzte Listen werden entfernt. |
|
NEWLISTID |
Die Listentabelle enthält im eingebundenen Dokument neue Listen-IDs im Ergebnisdokument. Es ermöglicht unabhängige und nicht fortlaufende Listen zu erstellen, wenn mehrere Includes einer Datei vorhanden sind. |
„Wichtiger Hinweis“
Es handelt sich bei NEWLISTID um einen Feldschalter und dies wird verwendet, wenn bei mehrere Ausfertigungen die gleiche Datei includiert wird.
Beispiel: {INCLUDETEXT “neu1.rtf” \* NEWLISTID}
Version 3.13
Achtung:
Dieser Parameter steht in Abhängigkeit des Parameters "--replace-header".
"replace-header=never"
Keine Steuerungs-Möglichkeit der Behandlung der Listentabellen. Das Verhalten
ist wie bei "lists=keep".
"replace-header=always"
(default value) Hier findet grundsätzlich
eine Erweiterung des Wurzel-Dokuments um
Listentabellen aus eingefügten Textbausteinen statt. Es wird nur zwischen
Optimierung und Nicht-Optimierung unterschieden.
Das bedeutet, dass "lists=keep" wie "lists=expand" (keine
Optimierung) und "lists=optimize" wie "lists=adjust" (Optimierung)
behandelt werden.
"--replace-header=auto"
Nur in dieser Einstellung werden alle 4 Varianten des “—lists“-Parameters wie
oben beschrieben ausgeführt.
Beispiele
--lists=adjust
Hier soll die Listentabelle um die Listen erweitert werden, die in den Textbausteinen verwendet werden. Unbenutzte Listen sollen entfernt werden. Dadurch stehen die verwendeten Listen auch bei einer späteren Bearbeitung in MS Word wieder zur Verfügung.
Dieser Parameter wird im Anwendungsbeispiel Bausteine veranschaulicht.
6.44. Parameter --logfile
[--log/-l]
Der Parameter --logfile setzt den Dateinamen und Pfad für die Fehlerprotokolldatei, die CIB merge für jeden Mischlauf schreibt.
Syntax
--logfile=<Fehlerprotokolldatei>
Beschreibung
Mit --logfile=!<Fehlerprotokolldatei> wird eine bereits vorhandene Fehlerprotokolldatei überschrieben, mit --logfile=+<Fehlerprotokolldatei> werden die aktuellen Einträge einfach an die Datei angehängt. Tritt kein Fehler auf, so wird eine leere Fehlerdatei geschrieben.
Beispiel
--logfile=!Komma_log.log
Eine evtl. bereits vorhandene Datei Komma_log.log im aktuellen Verzeichnis wird überschrieben.
Die Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
Hinweis
Es empfiehlt sich, den Parameter --logfile in die erste Zeile der Parameterdatei zu schreiben. Dadurch werden bereits Fehler in der Parameterdatei protokolliert.
Ab der CIB merge Version 3.9.x kann --logfile zusätzlich mit --verbose skaliert werden. Zu den Details von --logfile und --verbose siehe Kapitel Fehlerprotokolldatei. Beachten Sie auch die weiterührenden Informationen zu Trace-Möglichkeiten und Programmrückgabewerten im Buch "CIB merge Fehlerbehandlung".
6.45. Parameter -m
Der Parameter -m<Text> weist CIB merge an, einen angegebenen <Text> in der Meldung/Fehlerprotokolldatei auszugeben.
Syntax
-m<Text>
Beschreibung
Der Parameter -m<Text> ermöglicht das Einfügen von selbst definierten Texten in die Meldungsdatei. Mit -m@ gibt CIB merge automatisch die gesetzten Parameter für Eingabe- und Ausgabedateinamen aus.
Beispiel
--logfile=!Komma_log.log --inputfile=Anschreiben_in.rtf --outputfile=!Komma_out.rtf --datafile=Adresse_Komma.csv -m -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@
Der hinter -m angegebene Text wird in die Logdatei geschrieben. Durch -m@ werden die Namen der Eingabe- und Ausgabedateien ausgegeben.
Ein Auszug aus der Logdatei ist im Anwendungsbeispiel Lückentext zu finden.
Hinweis
Treten Fehler im Mischlauf auf, so werden diese nach den Meldungen aus -m ausgegeben.
Die Ausgabe der Programmversion von CIB merge wird mit dem Parameter --version gesteuert
6.46. Parameter -- max-executiontime
(ab CIB merge Version 3.10.3)
Dieser Parameter beschränkt die maximale Ausführungszeit.
Syntax
-- max-executiontime=[#milliseconds]
Beschreibung
Dieser Parameter legt die maximale Ausführungszeit in Millisekunden fest. Sobald dieser Wert überschritten wird, hält CIB merge mit Fehler 821 an.
Wenn dieser Wert 0 (Null) ist oder nicht gesetzt wurde, ist die Ausführungszeit unbegrenzt.
Dieser Parameter dient dazu Risiken, die durch Endlosschleifen entstehen können, zu vermeiden. Die folgende Feldkombination ist ein Beispiel für eine solche Schleife:
{ IF {MERGEREC \* keepalways} <> "{REF value}" \* SOLANGE}6.47. Parameter --maxOutputSize
(ab CIB merge Version 3.9.174)
Der Parameter maxOutputSize setzt die maximal zulässige Größe für den gesamten Serienbrief im „serialletter“ Fall.
Syntax
--maxOutputSize=[#bytes]
Beschreibung
Bei diesem Parameter handelt es sich um ein Abbruchkriterium für Serienbriefe, die mit CIB merge erstellt werden. Wird der Serienbrief größer als die eingestellte maximale Größe, dann quittiert CIB merge dies mit einem Returncode 818.
Damit kann der Anwender sicherstellen, dass die Erzeugung (die in der Regel automatisiert und ohne menschliche Kontrolle passiert) abgebrochen wird, wenn es zu einem ungewollten Verhalten im Bereich der Dateigröße kommt.
6.48. Parameter --maxSingleSize
(ab CIB merge Version 3.9.174)
Der Parameter maxSingleSize setzt die maximal zulässige Größe für ein einzelnes Dokument im „serialletter“ Fall.
Syntax
--maxSingleSize=[#bytes]
Beschreibung
Bei diesem Parameter handelt es sich um ein Abbruchkriterium für Seriernbriefe, die mit CIB merge erstellt werden. Wird ein einzelnes Dokument eines Serienbriefes größer als die eingestellte maximale Größe, dann quittiert CIB merge dies mit einem Returncode 817.
Damit kann der Anwender sicherstellen, dass die Erzeugung (die in der Regel automatisiert und ohne menschliche Kontrolle passiert) abgebrochen wird, wenn es zu einem ungewollten Verhalten im Bereich der Dateigröße kommt.
6.49. Parameter --merge
[-@[<Ziffer>]]
Ein einfaches --merge einzelner -@ als Argument sorgt dafür, dass CIB merge sofort zu mischen beginnt und alle vorher belegten Argumente dafür benutzt.
Syntax
--merge
oder
--merge=<Ziffer>
Beschreibung
Mit diesem Aufrufparameter können in einer Parameterdatei mehrere Aufträge hintereinander stehen, die jeweils getrennt voneinander bearbeitet werden.
Hinweis:
Ein bereits gesetzter Parameter ist so lange gültig, bis diesem ein neuer Wert zugeordnet wird.
Sollten in den beteiligten Datendateien nicht alle Datensätze/Variablen abgearbeitet sein, dann interpretiert CIB merge den Mischlauf als Seriendruck, fügt einen Abschnittswechsel in das Zieldokument ein und mischt beginnend vom Wurzeldokument weiter.
Ein --merge=1 wird dazu im Gegensatz als Einzelmischlauf ausgeführt und endet am Ende der RTF-Textbausteine, egal wie viele versorgte Daten noch unberührt sind. Die Ziffer gibt an, wie viele Datensätze durchlaufen werden und begrenzt somit den Seriendruck auf eine bestimmte Anzahl von Datensätzen.
Beispiele
--merge=1
Hier wird ein Einzelmischlauf ausgeführt, d.h. das Ergebnis-RTF enthält lediglich die Daten vom ersten Datensatz.
--merge=3
Das Ergebnis ist ein RTF-Dokument mit den ersten drei Datensätzen, auch wenn die Datenquellen mehr als drei Datensätze beinhalten.
Die Verwendung des Parameters wird im Anwendungsbeispiel Serienbrief veranschaulicht.
Hinweis:
Erfolgt die Übergabe der Parameter an CIB merge in einer Parameterdatei, so werden nur die Parameter ausgewertet, die vor dem Parameter --merge stehen.
6.50. Parameter --multidatafile
[--meta/--metadatafile/--multi/-c]
Wird eine Multisteuerdatei/Multi-CSV-Datei als Datenquelle verwendet, so muss zusätzlich der Parameter --multidatafile gesetzt werden.
Syntax
--multidatafile
Beschreibung
Der Parameter --multidatafile kennzeichnet, dass die mit dem Parameter --datafile angegebene Datendatei weitere Datendateien beinhaltet.
Beispiele
- Paramterdatei mit Multisteuerdaten aus Multi-CSV-Datei:
--datafile=multi.csv --multidatafile
Der Parameter --datafile definiert eine Multi-CSV-Datei. Die Aliase sind in der ersten Zeile der CSV-Datei definiert, alle weiteren Zeilen sind die Aliasdefinitionen.
Die Verwendung des Parameters im Zusammenhang mit CSV-Dateien wird im Anwendungsbeispiel Serienbrief veranschaulicht.
Hinweis:
Bei Verwendung von Multi-CSV-Dateien wird der Parameter --headerfile nicht eingesetzt.
- Parameterdatei mit Multisteuerdaten aus zwei getrennten CSV-Dateien
--datafile=Daten.csv
--multidatafile
--headerfile=Alias.csv
Alias-CSV-Datei:
Adresse;Lizenzinformationen
Daten-CSV-Datei:
Adresse.csv;Lizenzinfo.csv
Hinweis:
Die Aliasnamen und Aliasdefinitionen sind in diesem Beispiel in zwei CSV-Dateien getrennt gespeichert. Um die CSV-Datei für die Aliasnamen anzugeben wird der Parameter --headerfile verwendet. Die Aliasdefinitionen befinden sich in der CSV-Datei, die mit dem Parameter --datafile gesetzt wird. Jede Zeile stellt eine neue Definition (Datensatz) dar.
- Parameterdatei mit Multisteuerdaten aus XML:
--headerfile=XML:Daten_mitAlias.xml --datafile=/root/multi --multidatafile
Der Parameter --headerfile definiert die XML-Datei. Die Aliase ergeben sich aus den Knotennamen in der XML-Datei, die mit dem angegebenen XPath definiert sind. Die Aliasdefinitionen sind die Knoteninhalte.
Die Verwendung des Parameters mit Multisteuerdaten aus XML wird im Anwendungsbeispiel Serienbrief veranschaulicht6.51. Parameter --next-mode
[--next-modus/--next]
Der Parameter --next-mode steuert das Verhalten des {NEXT}-Befehls und wirkt auf Variablen, die zwar in einem Datensatz, im nächsten aber nicht mehr vorhanden sind.
Syntax
--next-mode=<Option>
<Option>: delete, empty oder keep
Beschreibung
Variablen, die zwar in dem einen, aber im nächsten Datensatz nicht mehr vorhanden sind, können mithilfe des Parameters --next-mode gelöscht, geleert oder beibehalten werden.
Mögliche Werte für <Option> sind:
|
Option |
Bedeutung |
|
delete |
Die Variablen werden gelöscht und sind somit nicht mehr definiert. |
|
empty |
Die Variablen werden geleert. Diese sind dann noch definiert aber leer wie „“ |
|
keep |
Die Variablen werden beibehalten und die Werte bleiben unverändert. |
Beispiel
--next-mode=delete
Ist eine Variable im nächsten Datensatz nicht mehr vorhanden (z.B. fehlender Knoten im XML), so wird diese Variable gelöscht, was daraufhin zu einem Fehler führt. Dies ist erwünscht, damit der Fehler nicht unerkannt bleibt, indem der fehlende Wert einfach ausgelassen wird.
Dieser Parameter wird im Anwendungsbeispiel Serienbrief veranschaulicht.
6.52. Parameter --old-compare
Mit diesem Parameter kann die neue Interpretation von Bedingungen abgeschaltet werden.
Syntax
--old-compare=<Option>
--alter-Vergleich=<Option>
<Option>: +, - oder „“
Beschreibung
MS-Office hat mit neueren Versionen einen erweiterten Funktionsumfang im automatischen Vergleich von Datentypen bekommen. Dieser hat eine Erneuerung in CIB merge (seit Version 3.8.126) erforderlich gemacht. Kunden die ein älteres (konservatives) Vergleichsverfahren wünschen, können dies über den --old-compare Aufrufparameter erwirken.
Die Abschaltung der neuen Interpretation von Bedingungen kann über den Parameter --old-compare gesteuert werden. Der Parameter kann über die “AUTOSTART” - Funktionalität (ab Merge 3.9.104 und 3.8.130) für alle Mischläufe gesetzt werden. Dazu kann die "AUTOSTART" – Parameterdatei per Hex-Editor direkt in die Binär-Datei gepatcht werden oder die Umgebungsvariable "CIB_MRGAUTOSTART" mit dem Parameterdateiname gesetzt werden.
Spezifikation
Der Parameter heißt „OLD-COMPARE“. Alternativ kann auch „ALTER-VERGLEICH“ angegeben werden. Wie bei allen Merge - Parametern wird die Groß-/Kleinschreibung nicht berücksichtigt.
Für <Option> sind folgende Werte möglich:
|
Option |
Bedeutung |
|
+ |
CIB merge interpretiert die Bedingungen, wie in den vergangenen Versionen (bis 3.9.127 bzw. 3.8.126): Beide Seiten eines Vergleichs (Bedingung) haben einen „Daten-Typ“, passt der Typ nicht zusammen, ist das Ergebnis „false“. Auswertungen werden keine vorgenommen, Wildcards sind nicht zulässig. |
|
- |
Standardeinstellung. CIB merge interpretiert die Bedingungen nach dem aktuellen Vergleichsverfahren: Der auf der linken Seite verwendete Daten-Typ gibt an wie verglichen wird:
|
|
„“ |
gleiche Wirkung wie die Option „+“. |
Beispiel
--old-compare=+
CIB merge interpretiert die Bedingungen nach dem alten Vergleichsverfahren.
|
{compare …} |
Erläuterung |
Auswertung ohne Schalter |
Auswertung mit Schalter --old-compare=+ |
|
1.1.2004 = 01.01.2004 |
Vergleich als Kalenderdatum |
1 |
|
|
„1.1.2004“ = 01.01.2004 |
Vergleich als Text, weil links Anführungszeichen stehen. |
0 |
|
|
1.1.2004 = „01.01.2004“ |
Vergleich als Datum, weil die rechten Anführungszeichen nicht stören. |
1 |
0 |
|
1 = 01 |
Vergleich als Zahl |
1 |
1 |
|
„1“ = 01 |
Vergleich als Text, weil links Anführungszeichen stehen. |
0 |
0 |
|
1 = „01“ |
Vergleich als Zahl, weil die rechten Anführungszeichen nicht stören |
1 |
0 |
|
Betrag < „10.000 €“ |
Vergleich als Text, weil rechts Anführungszeichen stehen |
1 |
1 |
|
Höhe > 3,5m |
Vergleich als Zahl mit 3,5 |
1 |
1 |
|
Betrag < EUR10000 |
Vergleich als Text, weil 10000 nicht am Anfang steht. |
1 |
1 |
|
Betrag < „EUR 10000“ |
Vergleich als Text, weil 10000 nicht am Anfang steht. |
1 |
1 |
|
1.1.2004 = 1 |
Vergleich als Zahl, weil rechts kein Datum erkannt wurde. Wenn rechts kein Datum erkannt wird, wird versucht beide Seiten als Zahl zu interpretieren. |
0 |
0 |
|
1+1 = 2 |
Vergleich als Zahl, wobei der Ausdruck 1+1 nicht ausgewertet wird. (Also: 1 = 2) |
1 |
0 |
|
„Test Wild“ = „*W??d” |
„*“ und „?“ werden als gewöhnliche Zeichen interpretiert (ergibt also 0) |
1 |
0 |
6.53. Parameter --optimize
Der Parameter --optimize entfernt die durch MS Word eingefügten überflüssigen Schalter.
Syntax
--optimize
Beschreibung
MS Word fügt beim Einfügen oder Umformatieren von REF-Feldern teilweise einen Schalter \* FORMATVERBINDEN oder \* MERGEFORMAT ein, der die Rohtexte schlechter lesbar macht und in CIB merge zu Performancenachteilen führt. CIB merge entfernt diese überflüssigen Schalter mit dem Parameter --optimize.
Beispiel
--inputfile=Optimierung_in.rtf --outputfile=!Optimierung_out.rtf --optimize --filter=f
Hier werden alle MERGEFORMAT-Schalter aus dem RTF Optimierung_in.rtf entfernt, ohne Feldergebnisse einzumischen (--filter=f). Das Ergebnis Anschreiben_optimiert enthält keine solchen Schalter mehr.
Die Verwendung dieses Parameters wird zusammen mit anderen Optimierungs-Parametern im Anwendungsbeispiel Lückentext veranschaulicht.
6.54. Parameter --outputfile
[--output/-o]
Der Parameter --outputfile spezifiziert die Ausgabe- oder Ergebnisdatei.
Syntax
--outputfile=<Ausgabedatei>
Beschreibung
Der Aufruf --outputfile=! überschreibt eine bereits vorhandene Ausgabedatei, --outputfile=+ hängt die Ausgabedatei an die bereits vorhandene Datei an und erzeugt so eine MultiRTF-Datei.
Ist keine explizite Pfadangabe vorhanden, so wird die Datei im mit --target-directory angegebenen Arbeitsverzeichnis erzeugt, ohne gesetztes --target-directory wird die Ausgabedatei im aktuellen Verzeichnis abgelegt.
Beispiele
- Erzeugung einer einfachen RTF-Datei
--outputfile=!Anschreiben_out.rtf
Die Datei Anschreiben_out.rtf wird in das aktuelle Verzeichnis geschrieben. Das Ausrufezeichen überschreibt ggfs. eine bereits existierende Datei.
Die Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
--outputfile=!..\result\Kontenuebersicht.rtf
Die Datei Kontenuebersicht.rtf wird in das Verzeichnis result geschrieben. Das Ausrufezeichen überschreibt ggfs. eine existierende Datei.
Die derartige Verwendung des Parameters wird im Anwendungsbeispiel Bausteine veranschaulicht.
- Erzeugung einer Multi-RTF-Datei
--logfile=!multirtf.log --outputfile=!multirtf.rtf --inputfile=input1.rtf -@1 -m@ --outputfile=+multirtf.rtf --inputfile=input2.rtf -@1 -m@ --inputfile=input3.rtf -@1 -mfertig.
Dieses Beispiel erzeugt aus drei RTF-Dateien eine MultiRTF-Datei und gibt die Aufrufparameter jeweils aus. Im ersten Mischlauf wird die multirtf.rtf mit --outputfile=!multirtf.rtf überschrieben, anschließend werden die weiteren Dateien mit --outputfile=+multirtf.rtf angehängt.
6.55. Parameter --output-language
Der Parameter --output-language steuert die sprachabhängige Ausgabeformatierung von Datumsangaben und Zahlen, die über die Feldschalter \# und \@ vorgenommen wurden.
Syntax
--output-language=<Sprache>
oder
--Ausgabesprache=<Sprache>
<Sprache>: english/englisch, french/franzoesisch, german/deutsch, spanish/spanisch, italian/italienisch, swiss/schweizerisch oder dutch/niederlaendisch
Beschreibung
Der Parameter --output-language beeinflusst nur die Ausgaben der Tausender- und Dezimaltrennzeichen sowie die Wochentage und Monatsnamen. Die Versorgung der Zahlen erfolgt derzeit auf Deutsch.
Die
Ausgabe von Feldern ohne \# und \@ wird nicht beeinflusst, wie zum Beispiel
{Aktualdat/Time/Date} oder {=…}.
Für <Sprache> sind folgende Werte möglich:
Die Ausgabe der Tausender- und Dezimaltrennzeichen wirkt sich zum Beispiel für 1234567 mit \# #.###,00 so aus:
|
Sprache |
Ausgabe |
||
|
|
Zahlen |
Datum |
|
|
english |
Englisch |
1,234,567.00 |
07/20/2007 |
|
french |
Französisch |
1 234 567,00 |
20/07/2007 |
|
german |
Deutsch |
1.234.567,00 |
20.07.2007 |
|
spanish |
Spanisch |
1.234.567,00 |
20/07/2007 |
|
italian |
Italienisch |
1.234.567,00 |
20/07/2007 |
|
swiss |
Schweizerisch |
1'234'567.00 |
20.07.2007 |
|
dutch |
Niederländisch |
1.234.567,00 |
20-07-2007 |
Voreingestellt ist die deutsche Ausgabe. Lässt man die Sprachangabe hinter dem Schalter weg, dann wird wieder auf deutsche Ausgabe zurückgesetzt. (initial value is german and default for output-language is german)
Die Einstellung gilt für alle Mischvorgänge (-@/-@1) nach „output-language“, bis die Parameter restlos abgearbeitet wurden oder erneut „output-language“ verändert wird.
Die Ausgabe der Wochentage und Monatsnamen erfolgt entsprechend. Der 28.8.2001 wird beispielsweise mit dem Format \@ „dddd, d. MMMM yyyy“ zum Ergebnis „Dienstag, 28. August 2001“, wenn die Ausgabesprache auf Deutsch eingestellt ist. Für Englisch ergibt es „Tuesday, 28. August 2001“.
(Für ein „echtes“ englisches Datum muss man den Schalter weiter verändern, sodass die Reihenfolge und Füllzeichen der jeweiligen landesüblichen Ausgabe entsprechen.)
Beispiel
--output-language=english
Das Ausgabeformat ist englisch. Die Ausgabe der Datumsangaben und Zahlenformate erfolgt im englischen Format. Der Parameter wird im Anwendungsbeispiel Lückentext veranschaulicht.
6.56. Parameter --parameterfile
[--parameter/-@<Parameterdatei>]
Mit dem Parameter --parameterfile wird der Name der Parameterdatei angegeben. Es wird ein Mischvorgang gestartet, der die gesetzte Parameterdatei verwendet.
Syntax
--parameterfile=<Parameterdatei>
Beschreibung
Der Parameter --parameterfile spezifiziert einen Dateinamen, der als Parameterdatei interpretiert wird. CIB merge erwartet dann in dieser Parameterdatei alle für den Mischlauf relevanten Aufrufparameter. Startet Einzel-Mischvorgang (Merge mischt nicht solange noch Daten in der Datenbank sind). @<Parameterdatei> CIB merge wertet sofort alle Parameter in der angegebenen Parameterdatei aus und ignoriert die restlichen Zeilen.
Beispiel (Aufruf in der Kommandozeile):
cibmrg32.exe --parameterfile=Komma_par.par
Alle für den Mischlauf relevanten Aufrufparameter befinden sich in der Datei Komma_par.par.
Die Verwendung des Parameters wird im Anwendungsbeispiel Lückentext veranschaulicht.
Hinweis
Der Parameter ist nur in Kombination mit dem Aufruf der Merge-EXE über die Kommandozeile anwendbar. Dabei können beliebige Aufrufparameter davor und danach stehen und beliebig viele Parameterdateien an beliebiger Stelle zwischen den anderen Parametern stehen. Es können auch weitere Parameterdateien von Parameterdateien aus aufgerufen werden. Dabei muss jedoch darauf geachtet werden, dass unendliche Rekursionen vermieden werden.
6.57. Parameter --prefix-delimiter
Der Parameter --prefix-delimiter definiert ein Trennzeichen zwischen Alias und Variablennamen und schaltet den Präfix-Mechanismus fest ein.
Syntax
--prefix-delimiter=<Trennzeichen>
Beschreibung
Durch Setzen des Parameters --prefix-delimiter wird das Trennzeichen angegeben, das zusammen mit dem Alias den Variablen im Rohtext vorangestellt wird. Dies ist z.B. sinnvoll beim Einsatz von Multiknoten, um die Variablen eindeutig zu halten. Der Default-Wert ist „.“.
Beispiel
--headerfile=XML:Daten_mitAlias.xml --datafile=/root/multi --multidatafile --prefix-delimiter
XML-Datei:
<root> <multi> <Kunden>XML:$(this);/root/data/Kunden/Kunde</Kunden> <Einzelposten>XML:$(this);/root/data/Posten/Einzelposten</Einzelposten> </multi> <data> <Kunden> <Kunde> <Vorname>Franz</Vorname> <Name>Meier</Name> <Strasse>Teststr. 4</Strasse> <PLZ>12345</PLZ> <Ort>Musterdorf</Ort> <Geschlecht>M</Geschlecht> <KundenNr>9898989</KundenNr> <AuftragsNr>111111-2</AuftragsNr> <Betrag>999</Betrag> </Kunde> weitere Kunden ...... </Kunden> <Posten> <Einzelposten> <KundeAuftragsNr>111111-2</KundeAuftragsNr> <Bezeichnung>Artikel1</Bezeichnung> <Betrag>999</Betrag> </Einzelposten> weitere Einzelposten.... </Posten> </data> </root>
Als Trennzeichen ist ein „.“ definiert (Default). Bei den Rohtexten sind alle Zugriffe auf Variablennamen um den Aliasnamen und das Trennzeichen zu ergänzen. Dadurch ist die Variable Betrag beispielsweise eindeutig. Ausschnitt aus dem Rohtext:
{REF
Kunden.Betrag}
{REF Einzelposten.Betrag}
Im Anwendungsbeispiel Serienbrief wird dieser Parameter verwendet.
6.58. Parameter --remove-hidden-text
Der Parameter –remove-hidden-text entfernt vollständig alle Inhalte aus dem Dokument, die als „Hidden“ markiert sind.
Syntax
--remove-hidden-text
Beschreibung
Durch Setzen des Parameters –remove-hidden-text wird der als „Hidden“ markierter Text entfernt. Andere Inhalte werden, abhängig von anderen Standardparametern, ohne Änderungen verarbeitet
Beispiel
--remove-hidden-text
-iInputfile.rtf
-o!Outputfile.rtf
-ff
6.59. Parameter --replace-header
Der Parameter --replace-header dient dazu, das Neuschreiben des Kopfes der RTF-Ausgabe wahlweise abzuschalten.
Syntax
--replace-header=<Option>
<Option>: always, never oder automatic
Beschreibung
Der Kopf der RTF-Ausgabe wird am Ende neu geschrieben. Wegen der Farb-,Listen- und Schriftartentabellen im Kopf der RTF-Ausgabe, muss CIB merge Zeit für den Abgleich wegen Einfügungen oder zur Optimierung aufwenden. Dieser Abgleich oder diese Optimierungen interessieren aber nicht jeden Anwender. Daher sind sie wahlweise abschaltbar. Das bezieht sich auch auf den gesamten Kopf.
Mögliche Werte für <Option> sind:
|
Option |
Bedeutung |
|
always |
Der Kopf der RTF-Ausgabe wird am Anfang immer reduziert geschrieben und bereits zu Beginn ist bekannt, dass der Kopf am Ende neu geschrieben wird. Würde man den RTF-Kopf aber deswegen am Anfang gar nicht schreiben, ist im Fehlerfall das Dokument unvollständig und nicht mehr mit MS Word lesbar. Dabei werden die Schriftartentabellen sowie der unspezifizierte Teil des Kopfes nicht ausgegeben. Die Listentabellen der Include-Files werden ignoriert. |
|
never |
Der Kopf der RTF-Ausgabe wird nie ersetzt. Wird er am Anfang trotzdem reduziert geschrieben? |
|
automatic |
Der Kopf der RTF-Ausgabe wird ersetzt, wenn eine der folgenden Bedingungen zutrifft:
|
Beispiele
--replace-header=automatic
Dieser Parameter wird zusammen mit --fonts, --colors und --lists im Anwendungsbeispiel Bausteine veranschaulicht.
6.60. Parameter --serialletter
Der Parameter verändert das Verhalten beim Schreiben von Multi-RTF-Dateien.
Syntax
--serialletter=<Option>
<Option>: auto oder multi
Beschreibung
Mögliche Werte für <Option> sind:
|
Option |
Bedeutung |
|
auto |
Defaultwert, hier wird nach jedem Datensatz ein Abschnittswechsel eingefügt und alle Datensätze stehen in einem RTF-Dokument. |
|
multi |
Für jeden Datensatz wird ein vollständiges RTF-Dokument in ein Multi-RTF geschrieben. |
Beispiel
--serialletter=multi --outputfile=!Serialletter_out.rtf
Das Ergebnisdokument Serialletter_out.rtf ist ein Multi-RTF, das alle Datensätze enthält.
Die Verwendung des Parameters wird im Anwendungsbeispiel Serienbrief veranschaulicht.
6.61. Parameter --set
[-:]
Setzt eine Variable, die man in RTF-Textbausteinen verwenden kann. Ist diese Variable auch in der Datenversorgung (CSV, XML) vorhanden, wird vorrangig dieser Wert aus dem zugesteuerten Datenstrom verwendet.
Syntax
--set=Variable=Wert
Beispiel
--set=XmlDateiname=Daten.xml
Die Variable „XmlDateiname“ wird auf den Wert „Daten.xml“ gesetzt. Diese Variable kann in den RTF-Bausteinen abgefragt werden.
Die Verwendung des Parameters wird im Anwendungsbeispiel Serienbrief veranschaulicht.
Hinweis:
Dieser Parameter kann auch mehrfach für einen Mischaufruf benutzt werden
Aufrufbeispiele
- CIB runshell
Cibrsh .....-m–set=Vorname=Hans -m–set=Nachname2=Wurst.......
- CIB merge mit Parameterdatei
...
# setze Vorname auf Hans
--set=Vorname=Hans
# setze Nachname auf Wurst
--set=Nachname=Wurst
...
1.1.3.4 CIB merge aus JAVA
...
t_MergeJob.setProperty("--set=Vorname=", "Hans");
t_MergeJob.setProperty("--set=Nachname=", "Wurst")
...
6.62. Parameter --short-tokens
[--rta/--cibrtf]
Mit diesem Parameter erzeugt CIB merge eine Zieldatei in einem Format mit verkürzten RTF Tokens (CIBrtf).
Syntax
--short-tokens
Beschreibung
Durch die mit dem Parameter --short-tokens erzeugten verkürzten RTF Tokens wird die Dateigröße wesentlich verkleinert. Durch den Einsatz von so optimierten CIBrtf-Dateien, kann die Performance von CIB format und CIB merge optimiert werden.
Eine Weiterverarbeitung dieses Zieldokumentes ist mit CIB format/view und mit CIB merge ab Version 3.8.106 möglich. CIBrtf ist CIB spezifisch und kann von Fremdprodukten nicht verarbeitet werden, CIB merge kann es jedoch einlesen und ohne --short-tokens als RTF wieder ausgeben.
Beispiel
--inputfile=Optimierung_in.rtf --outputfile=!Optimierung_out.rtf --short-tokens --filter=f
CIB merge mischt keine Feldinhalte ein (--filter=f) und schreibt eine Ausgabedatei mit verkürzten CIBrtf-Tokens (CIBRtf). Durch die verkürzten RTF-Befehle in der Ausgabe erhält man eine gegenüber dem RTF verkleinerte Ergebnisdatei.
Die Verwendung dieses Parameters wird zusammen mit anderen Optimierungs-Parametern im Anwendungsbeispiel Lückentext veranschaulicht.
Nachteil:
Das RTF-Format kann nur von der CIB format/output Komponente weiterverarbeitet werden.
6.63. Parameter --source-directory
[--source/-a]
Der Parameter --source-directory setzt ein eigenes Verzeichnis für das RTF-Wurzeldokument und die RTF-Bausteine.
Syntax
--source-directory=<Verzeichnis>
Beschreibung
Der Parameter --source-directory setzt das Verzeichnis, in dem das RTF-Wurzeldokument und die RTF-Bausteine erwartet werden. Es kann auch eine Liste von Arbeitsverzeichnissen angegeben werden. Die einzelnen Angaben werden durch Semikolon getrennt. Für jede verwendete Datei wird eine Suche gestartet und die erste Fundstelle genutzt. Mit dem Parameter --source-directory kann ein Pfad absolut angegeben werden oder relativ zu dem Parameter --target-directory. Der Parameter --target-directory ist daher vor dem Parameter --source-directory zu setzen. Damit können z.B. in Multithreadanwendungen für jeden Thread das gleiche Quellenverzeichnis --source-directory, aber verschiedene Ausgabe/Logverzeichnisse --target-directory angegeben werden. Wird kein Quellenverzeichnis angegeben, dann gilt das Ausgabeverzeichnis auch als Quellenverzeichnis.
Ausnahme:
Haben Dateien eine eigene qualifizierte Pfadangabe im Namen, so werden die Parameter --source-directory und --target-directory für diese Dateien ignoriert.
Beispiel einer optimalen Parameterdatei mit --target-directory und --source-directory:
--target-directory=csv --source-directory=..\templates --inputfile=wurzelbaustein.rtf --outputfile=!..\result\Kontenuebersicht.rtf --datafile=multi.csv
Mit --source-directory wird das Verzeichnis gesetzt, in dem alle RTF-Bausteine zu finden sind. Somit ist eine explizite Pfadangabe bei --inputfile nicht notwendig. --source-directory wird relativ zu --target-directory angegeben.
Die Verwendung des Parameters wird im Anwendungsbeispiel Bausteine veranschaulicht.
6.64. Parameter --statistics
Der Parameter --statistics gibt die Anzahl der erzeugten Dokumente in einer spezifizierten Datei aus.
Syntax
--statistics=<Filename>
Beispiel
--statistics=!count.txt
Die Anzahl der von CIB merge erzeugten Dokumente werden in der Datei count.txt ausgegeben.
Im Anwendungsbeispiel Serienbrief werden beispielsweise 3 Dokumente erzeugt. Die Datei count.txt enthält nach dem Mischlauf folgenden Inhalt:
GeneratedDocumentCount=3
6.65. Parameter --target-directory
[--target/-q]
Der Parameter--target-directory bestimmt das Verzeichnis für die Daten- und Ausgabedateien.setzt das aktuelle Arbeitsverzeichnis, in dem CIB merge die übergebenen Dateien sucht.
Syntax
--target-directory=<Verzeichnis>
Beschreibung
Zusätzlich zum Verzeichnis für die Daten- und Ausgabedateien --target-directory, kann mit dem Parameter --source-directory ein Pfad angegeben werden, in dem der Wurzelbaustein und weitere RTF-Bausteine gesucht werden.
--source-directory ist relativ zu --target-directory, kann aber auch absolut angegeben werden. Damit können für Multithreadanwendungen für jeden Thread das gleiche Inputdirectory --source-directory, aber verschiedene Output/Logdirectories --target-directory angegeben werden.
Beispiele
--target-directory=csv
--datafile=multi.csv
--outputfile=!..\result\Kontenuebersicht.rtf
Hier wird --target-directory verwendet, um das
Verzeichnis für die CSV-Dateien anzugeben, das Ausgabeverzeichnis wird direkt
mit --outputfile gesetzt. Ohne explizite Pfadangabe bei --outputfile, würde das
Ergebnis ebenfalls in das --target-directory geschrieben werden. Das RTF-Wurzeldokument und die RTF-Bausteine liegen in
--source-directory, außer sie haben eigene Pfadangaben im Namen.
Die Verwendung des Parameters wird im Anwendungsbeispiel Bausteine veranschaulicht.
Hinweis:
--target-directory setzt immer auch gleich --source-directory, kommt also --target-directory nach --source-directory, so wird --source-directory überschrieben.
6.66. Parameter --template-combine
(Ab CIB merge Version 3.9.181)
Der Parameter “--template-combine“ führt dazu, dass alle {INCLUDETEXT} Anweisungen aufgelöst werden, alle anderen Feldanweisungen aber unverändert bleiben.
Syntax
--template-combine
Beschreibung
Damit wird dem Mischlauf vorgegeben, dass ausschließlich INCLUDETEXT Anweisungen aufgelöst werden. Alle anderen Feldanweisungen bleiben bestehen. Man generiert damit aus einem Dokumentprojekt mit n Bausteinen ein großes Eingabedokument
6.67. Parameter --verbose
Mit --verbose kann man die Menge/Art der Fehlermeldungen im Logfile bestimmen.
Syntax
--verbose=<verbose-level>
<verbose-level>: 0-9
Beschreibung
<verbose-level> kann Werte zwischen 0 und 9 annehmen. 0 bedeutet, dass keine Fehler angegeben werden, 9 hingegen, dass auch relevante Folgefehler ausgegeben werden.
Die verfügbaren Verbosity-Levels finden Sie hier. Beachten Sie auch die Fehlerkategorien.
Beispiel:
--verbose=9+all+source6.68. Parameter --version
[-v]
Mit dem Parameter --version gibt CIB merge die CIB merge Programmversion in der Meldung/Logdatei aus.
Syntax
--version
Beispiel
--logfile=!Komma_log.log --version
Die Logdatei enthält neben Fehlermeldungen auch eine Ausgabe der CIB merge Programmversion.
Ein Auszug des Inhalts der Logdatei ist im Anwendungsbeispiel Lückentext zu finden.
6.70. Parameter --workingset-size
[--workingsetsize]
Der Parameter --workingsetsize setzt die InitHeap- und Workingset-Größe.
Syntax
--workingset-size=<min-Wert>;<max-Wert>
Beschreibung
Das Setzen der InitHeap- und Workingset-Größe kann auf manchen Servern die Performance von CIB merge verbessern.
Umgebungsvariablen und Parameter
Um die WorkingSet-Size zu definieren kann der Parameter: „--WORKINGSETSIZE“ benutzt werden.
Die alternative Schreibweise „--WORKINGSET-SIZE“ wird ebenfalls erkannt.
Wie bei allen Merge - Parametern wird die Groß-/Kleinschreibung nicht berücksichtigt.
Alternativ kann dies auch über die Umgebungsvariable „CIB_MRGWORKINGSETSIZE“ gesetzt werden. Die Variable „WORKINGSETSIZE“ kann mittels eines HEX- Editors auch direkt in der Binärdatei gepatcht werden. Die WorkingSet-Size definiert die minimale und maximale Größe der Windows Process-WorkingSet-Size. Der minimale und maximale Wert werden durch eine „;“ getrennt. (Beide sind erforderlich)
Mit der Umgebungsvariable „CIB_MRGINITHEAPSIZE” kann die Initiale Thread-Heap-Größe in KByte eingestellt werden.
Die Initialen Heap- Größe kann auch in der Binärdatei gepatcht werden.(„INITHEAPSIZE")
Patchen geht vor Umgebungsvariable.
Die Erweiterung wird in CIB merge 3.9 aufgenommen. (Nur für Windows)
Beispiele
|
Einstellung |
Erläuterung |
|
--Workingset-Size= 504800;1413120 |
Setzt die Windows-Process-Workingset-Größe auf ein Minimum von 504800 und ein Maximum von 1413120 (per Parameter) |
|
CIB_MRGWORKINGSETSIZE=
504800;1413120 |
Setzt die Windows-Process-Workingset-Größe auf ein Minimum von 504800 und ein Maximum von 1413120 (per Umgebungsvariable) |
|
CIB_MRGINITHEAPSIZE=400 |
Setzt
die Init-Thread-Heap-Size auf 400 KByte. |
Setzen der InitHeap- und Workingset-Größe. Das Setzen der InitHeap- und Workingset-Size kann auf manchen Servern die Performance von CIB merge verbessern. Die optimale Konfiguration hängt von vielen Parametern wie Speicher, Netzwerk etc. ab. Deshalb kann nicht die “beste” Einstellung für alle Systeme ermittelt werden. Die für den verwendeten Server kann eine möglicherweise bessere Einstellung durch geeignete Tests ermittelt werden. Der Parameter kann über die "AUTOSTART" – Funktionalität (ab Merge 3.9.104 und 3.8.130) für alle Mischläufe gesetzt werden. Dazu kann die "AUTOSTART" – Parameterdatei per Hex-Editor direkt in die Binär-Datei gepatcht werden oder die Umgebungsvariable "CIB_MRGAUTOSTART" mit dem Parameterdateiname gesetzt werden.
7. Besondere Funktionalitäten: Textcaching
CIB merge kann die Ergebnisdatei nicht nur im RTF Format als Datei auf der Festplatte ausgeben. Es können auch verschiedene Parameter für eine Optimierung, Komprimierung und/oder Verschlüsselung des Ergebnisdatenstromes eingesetzt werden.
- Egal mit welcher Wurzel gemischt wird, der Include-Cache wirkt unabhängig davon über die Aufträge hinweg, die innerhalb eines Merge-Aufrufes abgesetzt werden.
- Die Wurzel ist derzeit noch nicht im Include-Cache enthalten. Der Include-Cache ist wirklich nur für Includes.
Hinweis
zu 2: Allerdings
gibt es für die Wurzel schon immer eine andere Optimierung: Wenn man den
Parameter -I angibt und einmal mischt, dann bleibt die Wurzel im Speicher bis
wieder ein -I angegeben wird.
Mischt man also viele Dateien mit der gleichen Wurzel direkt hintereinander und gibt nur einmal -I an, dann hat man den gleichen Cache-Effekt.
Hinweis zu 1 und 2: Die Optimierung über den Include-Cache ist ein trade-off für Laufzeit auf Kosten Speicher _und_ Funktionalität:
Wenn man mit Wurzel X mischt, dann werden für X die Fonttables, Colortables usw in Bezug auf das jeweilige Include verändert (erweitert). Dagegen werden für die Includes die Font-, Color- usw Schlüssel (\f12, \cf1...) in Bezug auf die aktuelle Wurzel angepasst und so im Cache abgelegt.
Wenn die Wurzeln salopp gesprochen "zusammenpassen", dann stimmen die Farben, Fonts usw. nachher auch. Wenn nicht, dann nicht.
Um absolute Sicherheit zu haben, muss man also die Dokumente mit derselben Wurzel hintereinander mischen, um den Cache-Vorteil zu haben und anschließend den Cache leeren. Danach kann man mit der nächsten Wurzel mischen usw.
Den Cache löscht man indirekt mit einem der Befehle zum Steuern des Verhaltens beim Include in Bezug auf Fonts, Colors, Listtables usw. Es reicht zum Beispiel ein einziges --replace-header um den Cache zu löschen. (Es wird dabei der Standard --replace-header=always eingestellt, aber der dürfte sowieso gelten.)
Wegen des letzten Hinweises oder vielmehr wegen der Arbeitsweise beim Zusammenführen der Tabellen aus dem Header der RTF, ist ein Wurzel-Cache meist nicht sinnvoll und wegen der nötigen Sortierung der Aufträge nach Wurzel auch nicht erforderlich.
8. Besondere Funktionalitäten: Ergebnisoptimierung, Verschlüsselung und Komprimierung
CIB merge kann die Ergebnisdatei nicht nur im RTF Format als Datei auf der Festplatte ausgeben. Es können auch verschiedene Parameter für eine Optimierung, Komprimierung und/oder Verschlüsselung des Ergebnisdatenstromes eingesetzt werden.
Die folgende Tabelle zeigt die Kompatibilität aller möglichen Kombinationen mit den CIB office Modulen und Fremdprodukten.
Zu den Details der Ansteuerung mit CIB merge siehe die entsprechenden Parameter zu Optimierung, Verschlüsselung und Komprimierung
|
Produkt |
CIB merge |
CIB format / view |
Fremdprodukte |
|||
|
Aktion |
Schreiben |
Lesen |
Lesen |
Lesen |
||
|
|
|
MultiRTF |
|
|
|
|
|
CIB RTF-Ausgabe |
Ja |
Ja |
Ja *) |
Ja |
Nein |
|
|
Verschlüsseln |
Ja |
Ja **) |
Ja |
Ja |
Nein |
|
|
Komprimieren |
Ja |
Ja **) |
Ja **) |
Ja |
Ja, wenn ZLIB 1.1.3 Format unterstützt wird |
|
|
Kombination Verschlüsseln + Komprimieren |
Ja **) |
Ja **) |
Ja **) |
Nein (=bald, laut AE) |
Nein |
|
|
Kombination |
Ja |
Ja **) |
Ja *) |
Ja |
Nein |
|
|
Kombination |
Ja |
Ja **) |
Ja **) |
Ja |
Nein |
|
|
Kombination Verschlüsseln + CIB RTF-Ausgabe + Komprimieren |
Ja **) |
Ja **) |
Ja **) |
Nein (=bald, laut AE) |
Nein |
|
*) Ab Version 3.8.106
**) Ab Version 3.9.115
Aus Steuerdateien und Set-Variablen kann weder verschlüsseltes, komprimiertes noch CIB RTF eingelesen werden.
9. Besondere Funktionalitäten: Mischen von Dokumenten-Eigenschaften
Implementiert ab CIB merge Version 3.9.174
In einem RTF können über den Editor (z.B. MS-Word) die Dokumenten-Eigenschaften (Doc-Properties) gesetzt werden. Beispiele dafür sind Autor, Titel, Abteilung, Projekt etc. Des Weiteren gibt es auch noch die sogenannten User-Properties. Der CIB merge behandelt Doc Properties und User-Properties gleich.
Über den Befehl INCLUDETEXT im Roh-RTF kann eine Dokumenten-Hierarchie aufgebaut werden. Jedes dieser RTFs kann eigene Dokumenten-Eigenschaften mitbringen. Der CIB merge mischt diese Dokumenten-Hierarchie zu einem einzigen Ausgabe-RTF.
Die Dokumenten-Eigenschaften des Ausgabe-RTFs bestimmen sich nach folgenden Regeln:
(bis CIB merge Version 3.12.2)
- Beim Zusammenmischen überschreibt das letzte RTF die Angaben der vorhergehenden, d.h. es "gewinnt" das tiefste RTF der Hierarchie.Bereits belegte
- Properties werden nicht durch leere gelöscht.
Beispiel:
Ausgehend von der Aufruf-Hierarchie
WURZEL.rtf -> BAUST1.rtf -> BAUST2.rtf
mit folgenden Dokumenten-Eigenschaften der einzenen Dokumente:
WURZEL.rtf: Titel-W
/ Autor-W / Projekt-W
BAUST1.rtf: Titel-1 /
Projekt-1 / Ablage-1
BAUST2.rtf: Titel-2 / Ablage-2
/ Abteilung-2
erhält das das gemischte Ergebnisdokument folgende
Dokumenten-Eigenschaften:
Titel-2 / Autor-W / Projekt-1 / Ablage-2 / Abteilung-2
(ab CIB merge Version 3.12.3)
- Beim Zusammenmischen werden die Dokumenten-Eigenschaften in der Misch-Reihenfolge „eingesammelt“. Dadurch hat immer die Wurzel Vorrang.
- Bereits belegte Properties werden dabei nicht überschrieben, es werden nur neue Eigenschaften ergänzt.
Beispiel:
Ausgehend von der Aufruf-Hierarchie
WURZEL.rtf -> BAUST1.rtf -> BAUST2.rtf
mit folgenden Dokumenten-Eigenschaften der einzenen Dokumente:
WURZEL.rtf: Titel-W
/ Autor-W / Projekt-W
BAUST1.rtf: Titel-1 /
Projekt-1 / Ablage-1
BAUST2.rtf: Titel-2 /
Ablage-2 / Abteilung-2
erhält das das gemischte Ergebnisdokument folgende Dokumenten-Eigenschaften:
Titel-W / Autor-W / Projekt-W / Ablage-1 / Abteilung-2
10. Anwendungsbeispiele
In diesem Kapitel werden anhand anschaulicher Beispiele die verschiedenen Aufrufparameter erklärt. An den entsprechenden Stellen wird dazu auf die ausführlichen Parameterbeschreibungen verwiesen.
Um die folgenden Beispiele zu testen, müssen die Binaries in einem Verzeichnis abgelegt werden, welches dann der PATH-Umgebungsvariablen hinzugefügt werden sollte. Um die Beispiele über die Kommandozeile auszuführen, müssen Sie sich im jeweiligen Verzeichnis befinden. Für jedes Beispiel gibt es eine ausführbare Batch-Datei.
Zum Zeitpunkt der Entwicklung der Anwendungsbeispiele kamen folgende Versionen zum Einsatz:
cibmrg32.dll, cibmrg32.exe: 3.9.171.0
CibJob32.dll: 1.4.20.0
CibChart.dll: 1.1.4.0
JComod.dll: 2.2.52.1
10.1. Anwendungsbeispiel Lückentext
Das folgende Beispiel befindet sich im Unterverzeichnis Lueckentext. Es verwendet ein Anschreiben, das als RTF vorliegt. Dieses enthält Variablen, die aus einer Datenquelle gefüllt werden sollen. Dabei handelt es sich um eine CSV-Datei mit den Daten des Empfängers. Das Ergebnis des Mischlaufs ist eine Zahlungserinnerung, die die Kundendaten aus der CSV-Datei enthält.
Aufruf der CIB merge HilfeEinfachste Form eines Mischlaufs (IOD)
Aufruf einzelner Parameter über die Kommandozeile
Aufruf einzelner Parameter über JAVA
Aufruf einzelner Parameter über C++
Aufruf der Parameterdatei über Kommandozeile
Aufruf der Parameterdatei über JAVA
Optimierung von Rohtexten vor Auslieferung
Aufruf der CIB merge Hilfe
Die CIB merge Hilfe kann unter Windows nicht auf der Konsole ausgegeben werden, da es sich um eine Fensteranwendung handelt, um einen Fortschrittsdialog während des Mischlaufs anzeigen zu können (siehe Parameter --dialog). Um einen Überblick über alle möglichen Aufrufparameter zu erhalten, kann die Hilfe in einer Datei ausgegeben werden. Dazu ist folgender Aufruf in der Kommandozeile einzugeben, oder die Batch-Datei hilfe.bat auszuführen.
cibmrg32 --logfile=!hilfe.txt --help
Die Hilfe wird in die Datei hilfe.txt umgeleitet und ist wie folgt aufgebaut:
Benutzung von CIB merge:
>CIBMRG32 <Parameter1> <P2> ...
Jeder Parameter sollte mit einem Startzeichen aus "-/" beginnen.
Die ersten Parameter ohne Startzeichen bekommen sonst der Reihe nach die Parameterzeichen aus "IODH" zugewiesen.
Nach Auswertung aller Parameter wird automatisch "/@" ausgeführt.
Parameter : Wirkung
Q<Arbeitsverzeichnis>: setzt Arbeitsverzeichnis (muss zwingend am Anfang sein!)
A<Templateverzeichnis>: setzt Templateverzeichnis
I<Eingabe> : setzt RTF Eingabequelle
? : Hilfeseite anzeigen
weitere Parameter
Einfachste Form eines Mischlaufs (IOD)
Die einfachste Form eines Mischlaufs besteht darin, eine Eingabedatei mit Daten zu füllen und das Ergebnis in eine Ausgabedatei zu schreiben. Das kann über die einzelnen Parameter --inputfile (I), --outputfile (O) und --datafile (D) angegeben werden. Im Folgenden wird beschrieben, wie diese Parameter über die Kommandozeile angegeben werden können. Außerdem werden Varianten zur Ansteuerung aus JAVA und C++ vorgestellt.
Aufruf einzelner Parameter über die Kommandozeile
Um eine Eingabedatei mit Daten zu mischen und in eine Ausgabedatei zu schreiben, reicht ein einfacher Aufruf in der Kommandozeile. Mit Hilfe des Aufrufparameters --inputfile wird die Datei angegeben, die dem Mischlauf als Eingabedatei dient. Der Parameter --datafile gibt den Namen der Datenquelle an und --outputfile legt die Ausgabedatei fest.
Folgender Aufruf versorgt somit die Eingabedatei Anschreiben_in.rtf mit den Daten aus Adresse.csv (die sich im gleichen Verzeichnis befindet) und schreibt das Ergebnis in die Ausgabedatei Anschreiben_out.rtf, wobei eine evtl. bereits vorhandene Datei überschrieben wird.
cibmrg32.exe --inputfile=Anschreiben_in.rtf --outputfile=!Anschreiben_out.rtf --datafile=Adresse.csv
Wird die Reihenfolge IODH (inputfile, outputfile, datafile, headerfile) eingehalten, kann auf die Angabe der Parameter verzichtet werden. Folgender Aufruf führt dann zum gleichen Ergebnis (Anschreiben.bat):
cibmrg32.exe Anschreiben_in.rtf !Anschreiben_out.rtf Adresse.csv
Aufruf einzelner Parameter über JAVA
Statt die Parameter über die Kommandozeile zu setzen, kann die Ansteuerung auch über JAVA erfolgen. Das gleiche Ergebnis wird mit folgendem JAVA-Code (MergeEinzelneParameter.java) erzielt:
Auszug aus MergeEinzelneParameter.java:
…
JCibMergeJob t_Job = new JCibMergeJob();
t_Job.initialize();
if (!t_Job.isInitialized())
{
// Fehler beim Initialisieren
System.err.println("Fehler beim
Initialisieren");
System.exit(1);
}
try
{
// Beteiligte Dateien für den
Mischlauf
t_Job.setProperty(ICibMergeJob.PROPERTY_INPUTFILE,
"Anschreiben_in.rtf");
t_Job.setProperty(ICibMergeJob.PROPERTY_OUTPUTFILE,
"Anschreiben_out.rtf");
t_Job.setProperty(ICibMergeJob.PROPERTY_DATAFILE,
"Adresse.csv");
//Job ausführen
t_Job.execute();
//Fehlerbehandlung
int t_Error =
((Integer)t_Job.getProperty(IComodJob.PROPERTY_ERROR)).intValue();
if (t_Error != 0)
{
// Fehler beim Ausführen des Jobs
String t_Errortext =
(String)t_Job.getProperty(IComodJob.PROPERTY_ERRORTEXT);
System.err.println("Fehler beim
Ausführen: "+t_Error+" "+t_Errortext);
}
}
finally
{
t_Job.terminate();
}
…
Hier wird die Jobklasse zum Ansteuern des CIB merge aus Java verwendet. Mit dem JCibMergeJob kann ein Mischauftrag aus Java heraus an den CIB merge übergeben werden. Die Jobklasse sammelt zunächst die Parameter, die mit setProperty gesetzt werden. Mit execute() wird CIB merge dann aufgerufen.
Aufruf einzelner Parameter über C++
Ist eine Ansteuerung über C++ gewünscht, ist cibmerge(int argc, char *argv[]) zu verwenden. Auf diese Weise können die gewünschten Parameter gesetzt werden. Das Verzeichnis C:\\comod\\, das die CIB Module enthält, muss entsprechend angepasst werden. Für die Initialisierung von CIB merge wird dieses Verzeichnis benötigt.
Auszug aus MergeEinzelneParameter.cpp:
…
extern "C" const char *cibmerge_errormessage;
static char *test_arguments[]={"MergeEinzelneParameter", "--inputfile=Anschreiben_in.rtf", "--outputfile=!Anschreiben_out.rtf", "--datafile=Adresse.csv", 0};
int main(const unsigned int number_of_arguments, char *argument_vector[]) { if(!cibmerge_initialize("C:\\comod\\", 0)) cout << cibmerge_errormessage << endl;
int iReturn=0; iReturn = cibmerge(sizeof(test_arguments)/sizeof(*test_arguments) - 1, test_arguments); cout << "MergeEinzelneParameter Returnwert cibmerge: " << iReturn << endl;
if(!cibmerge_terminate()) cout << cibmerge_errormessage << endl; return 0; }
- Protokollierung und Verwendung eines anderen Trennzeichens in der Datenquelle
Im Folgenden sollen mögliche auftretende Fehler in einer Logdatei protokolliert werden und in dieser Datei auch eigene Meldungen, sowie Informationen zur verwendeten Programmversion ausgegeben werden. Außerdem ist die Datenquelle so aufgebaut, dass statt des Zeichens „;“ ein Komma als Trennzeichen in der CSV-Datei dient.
Um dies zu realisieren, müssen zusätzliche Aufrufparameter beim Mischlauf berücksichtigt werden. Ein Aufruf über die Kommandozeile wird dadurch leicht unübersichtlich. In diesem Fall ist es ratsam, die Parameter in eine Parameterdatei auszulagern. Diese Parameterdatei kann dann über die Kommandozeile aufgerufen werden. Die Varianten, wie die Parameterdatei über JAVA und C++ ausgeführt werden kann, werden im Folgenden ebenfalls erläutert.
Aufruf der Parameterdatei über Kommandozeile
Die Parameter, die für diesen Mischlauf benötigt werden befinden sich alle in der Datei Komma_par.par. Wird CIB merge über die Kommandozeile aufgerufen, wird die Parameterdatei mit Hilfe des Aufrufparameters --parameterfile angegeben ( Komma.bat):
cibmrg32.exe --parameterfile=Komma_par.par
Alle Zeilen, die in der Parameterdatei nicht mit „--„ oder „-„ beginnen, sind Kommentare (auch mit Leerzeichen eingerückte Parameter sind Kommentare).
Inhalt der Parameterdatei Komma_par.par:
Fehler sollen protokolliert werden
--logfile=!Komma_log.log --versionBeteiligte Dateien für den Mischlauf
--inputfile=Anschreiben_in.rtf --outputfile=!Komma_out.rtf --datafile=Adresse_Komma.csvHier gilt das Komma als Trennzeichen in der CSV
--delimiter=, -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@
- Erläuterungen
Neben den bereits beschriebenen Aufrufparametern --help, --inputfile, --datafile und --outputfile, enthält die Parameterdatei weitere Aufrufparameter, die beim Mischlauf berücksichtigt werden.
Der Parameter --logfile erzeugt eine Datei, in die alle während des Mischlaufs auftretenden Fehler geschrieben werden. Die Logdatei wird ohne Pfadangabe in das aktuelle Arbeitsverzeichnis generiert.
Um die Fehlerprotokolldatei übersichtlicher zu gestalten, können mit Hilfe des Parameters -m benutzerdefinierte Meldungen erzeugt werden. In diesem Beispiel enthält die Logdatei Komma_log.log nach dem Mischlauf neben Fehlern und Meldungen noch eine Ausgabe der verwendeten CIB merge Version (Parameter --version).
Nach dem Mischlauf steht somit auch folgender Text in der Logdatei:
CIB merge 3.9.171
CIB software GmbH 1991-2009
Diese Software ist urheberrechtlich sowie nach internationalen Vertraegen
geschuetzt. Unberechtigte Vervielfaeltigung und Verbreitung, unabhaengig
auf welche Art oder Weise oder mit welchen Mitteln, elektronisch oder
mechanisch und unabhaengig zu welchem Zweck,
ob ganz oder auszugsweise, kann schwere
zivil- und strafrechtliche Konsequenzen
nach sich ziehen und wird unter Ausschoepfung der Rechtsmittel geahndet.
Der Mischvorgang verwendet folgende Ein- und Ausgabedateien:
Eingabedatei: Anschreiben_in.rtf
Steuerdatei: Adresse_Komma.csv
Steuersatzdatei:
Ausgabedatei: Komma_out.rtf
Meldungsdatei: Komma_log.log
…
Als Trennzeichen in der CSV-Datei wird mit Hilfe des Parameters --delimiter das Komma-Zeichen definiert. Die CSV-Datei Adresse_Komma.csv sieht also folgendermaßen aus:
Vorname,Name,Strasse,PLZ,Ort,Geschlecht,KundenNr,AuftragsNr,Betrag
Max,Müller,Teststraße 3,99999,Testort,M,0987392,232222-4,123118
Aufruf der Parameterdatei über JAVA
Statt das Parameterfile über die Kommandozeile zu setzen, kann die Ansteuerung auch über JAVA erfolgen. Das gleiche Ergebnis wird mit folgendem JAVA-Code (MergeParameterfile.java) erzielt:
Auszug aus MergeParameterfile.java:
…
JCibMergeJob t_Job = new JCibMergeJob(); t_Job.initialize(); if (!t_Job.isInitialized()) { // Fehler beim Initialisieren System.err.println("Fehler beim Initialisieren"); System.exit(1); } try { // Parameterdatei für den Mischlauf t_Job.setProperty(ICibMergeJob.PROPERTY_PARAMETERFILE, "Komma_par.par"); //Job ausführen t_Job.execute(); //Fehlerbehandlung int t_Error = ((Integer)t_Job.getProperty(IComodJob.PROPERTY_ERROR)).intValue(); if (t_Error != 0) { // Fehler beim Ausführen des Jobs String t_Errortext = (String)t_Job.getProperty(IComodJob.PROPERTY_ERRORTEXT); System.err.println("Fehler beim Ausführen: "+t_Error+" "+t_Errortext); } } finally { t_Job.terminate(); } …
Aufruf der Parameterdatei über C++
Erfolgt die Ansteuerung über C++, kann mit Hilfe von CibMergePFile die entsprechende Parameterdatei ausgeführt werden. Das Verzeichnis C:\\comod\\, in dem die CIB Module liegen, muss entsprechend angepasst werden, da es für die Initialisierung von CIB merge benötigt wird.
Auszug aus MergeParameterfile.cpp:
…
extern "C" const char *cibmerge_errormessage;
int main(const unsigned int number_of_arguments, char *argument_vector[]) { if(!cibmerge_initialize("C:\\comod\\", 0)) cout << cibmerge_errormessage << endl;
int iReturn=0; iReturn = CibMergePFile("Komma_par.par"); cout << "Returnwert CibMergePFile: " << iReturn << endl;
if(!cibmerge_terminate()) cout << cibmerge_errormessage << endl; return 0; }
- Default-Verhalten für undefinierte/leere Variablen festlegen
Jetzt soll im Ergebnis-RTF ein definierter Default-Wert ausgegeben werden, wenn eine Variable nicht durch die Datenversorgung gefüllt werden kann oder diese leer ist. Dazu wird in der RTF-Datei Default_in.rtf einer Variablen namens „Default.“ mithilfe des SET-Feldbefehls der Wert „<unbekannter Wert>“ in roter Schrift zugewiesen.
{ SET Default. „<unbekannter Wert>“ }
Alle leeren oder undefinierten Variablen sollen diesen Wert erhalten. Die CSV-Datei Adresse_Default.csv ist so abgeändert, dass es keinen Wert für die Variable Ort gibt. Um dieses Verhalten zu unterstützen, ist das Setzen weiterer Parameter notwendig.
Folgender Aufruf startet den Mischlauf mit gewünschten Default-Verhalten (Default.bat):
cibmrg32.exe --parameterfile=Default_par.par
Auszug aus der Parameterdatei Default_par.par:
…
Beteiligte Dateien für den Mischlauf
--inputfile=Default_in.rtf --outputfile=!Default_out.rtf --datafile=Adresse_Default.csvDefault-Verhalten festlegen
--default-mode=all --default-prefix=Default. …
- Erläuterungen
Der Parameter --default-mode legt fest, in welchen Fällen das Default-Verhalten, also das Einsetzen eines Ersatzwertes, eingeschaltet werden soll. In diesem Fall, soll ein Default-Wert eingesetzt werden, wenn eine Variable nicht durch die Datenversorgung gefüllt werden kann, weil sie nicht definiert ist, oder weil sie leer ist. Wenn das Verhalten nur für undefinierte Variablen gelten soll, muss an dieser Stelle der default-mode auf „undefined“ (statt „all“) gesetzt werden.
Das Präfix, das unbekannten/leeren Variablen vorangestellt wird, wird mit dem Parameter --default-prefix definiert. Hier ist es das Präfix „Default.“. Für die Variable Ort wurde kein Wert in der Datenquelle gefunden, also wird überprüft, ob ein Wert für Default.Ort definiert ist. Da dies auch nicht der Fall ist, wird der Wert eingesetzt, der für „Default.“ gesetzt wurde, nämlich „<unbekannter Wert>“. Das Ergebnis ist in der Datei Default_out.rtf zu finden.
- Eingabe- und Ausgabesprache für Zahlenformat/Datumsformat festlegen
Das RTF Language_in.rtf enthält nun einen Zahlenformatschalter zur Formatierung des Rechnungsbetrags. Der Betrag soll jetzt mit Tausender-Trennzeichen und 2 Nachkommastellen angezeigt werden. Das Anschreiben ist auf Englisch verfasst. Demnach wird in diesem Fall die Angabe des Zahlenformats im englischen Format gemacht. Die Ausgabe der Zahlen soll ebenfalls im englischen Zahlenformat erfolgen. Im RTF steht also folgender Ausdruck:
{ REF Betrag \# #,####0.00€}
Um eine korrekte Darstellung im Ergebnis-Dokument zu erreichen, muss über die Parameter angegeben werden, dass es sich bei der Eingabe um eine englische Zahlenformatierung handelt (und nicht, wie standardmäßig angenommen, um eine deutsche). Um diese Formatierung auch im Ausgabedokument beizubehalten, muss dies ebenfalls über einen zusätzlichen Parameter gesteuert werden
Folgender Aufruf startet den Mischlauf zur Erzeugung der englischsprachigen Zahlungserinnerung (Language.bat):
cibmrg32.exe --parameterfile=Language_par.par
Auszug aus der Parameterdatei Language_par.par:
…Beteiligte Dateien für den Mischlauf
--inputfile=Language_in.rtf --outputfile=!Language_out.rtf --datafile=Adresse.csvEingabeformat für Zahlen ist auf englisch
--input-language=english
Ausgabeformat für Zahlen und Datum ist auf englisch--output-language=english …
- Erläuterungen
Der Aufrufparameter --input-language=english gibt an, dass die Zahlenformat-Angabe im RTF auf Englisch erfolgt. Um im Ergebnis eine korrekte Darstellung zu erreichen, muss diese Information angegeben werden, da sonst automatisch davon ausgegangen wird, dass es sich um eine deutsche Formatierung handelt, was unter Umständen zu unerwünschten Ergebnissen führen kann.
Um die Zahlen und Datumsangaben im Ergebnisdokument ebenfalls auf Englisch zu erhalten, wird der Aufrufparameter --output-language gesetzt.
Das Feld { DATE \@ "dddd, d.MM.jjjj" } erscheint im Ergebnisdokument z.B. als „Friday, 23.10.2009“. (deutsch: Freitag, 23.10.2009)
Das Feld {REF Betrag \# #,####0.00 } wird bei einem Betrag von 123118 zu „123,118.00“ formatiert. (deutsch: 123.118,00)
Optimierung von Rohtexten vor Auslieferung
Im Folgenden soll demonstriert werden, wie RTF-Bausteine optimiert und deren Dateigröße verringert werden kann. Vor allem in großen Projekten spielt das eine Rolle. Exemplarisch wird die Optimierung an der RTF-Datei Optimierung_in.rtf gezeigt. Diese enthält einige \* MERGEFORMAT Schalter, die MS Word beim Einfügen oder Umformatieren von REF-Feldern teilweise einfügt. Diese Schalter sollen aus dem RTF entfernt werden. Weitere Möglichkeiten, eine Beschleunigung der Verarbeitung in CIB merge und CIB format zu erreichen, besteht darin, Short-Tokens zu verwenden. Die Verwendung von Short-Tokens bietet zusätzlich einen Schutz vor Manipulation, da die Datei nur noch mit CIB-Modulen weiterverarbeitet werden kann. Werden die Dateien zwischen unterschiedlichen Maschinen ausgetauscht kann eine Übertragung beschleunigt werden, indem die Datei vorher komprimiert wird. All diese Schritte sollten durchgeführt werden, ohne dass Feldinhalte eingemischt werden. Welche Kombination von Optimierungen sinnvoll ist, hängt vom jeweiligen Umfeld und Einsatzgebiet ab. Um die Auswirkungen der verschiedenen Parameter zu testen, können die jeweiligen Parameter einkommentiert werden („#“ in der jeweiligen Zeile entfernen).
Folgender Aufruf optimiert die Eingabedatei (Optimierung.bat):
cibmrg32.exe --parameterfile=Optimierung_par.par
Inhalt der Parameterdatei Optimierung_par.par:
Fehler
sollen protokolliert werden
--logfile=!Optimierung_log.logEingabe-Datei--inputfile=Optimierung_in.rtf
Ausgabe explizit in eigenes Verzeichnis--outputfile=!Optimierung_out.rtf
Schalter Mergeformat entfernen--optimizeShort-Tokens
verwenden#--short-tokensKomprimieren#--compress=9Keine
Inhalte einmischen--filter=f- Erläuterungen
Der Parameter --optimize entfernt alle MERGEFORMAT-Schalter im RTF. Dadruch wird die Datei ein wenig kleiner und ist zudem besser lesbar.
Der Parameter --short-tokens erzeugt eine Ausgabedatei mit verkürzten CIBrtf-Tokens (CIBRtf). Durch die verkürzten RTF-Befehle in der Ausgabe erhält man eine gegenüber dem RTF verkleinerte Ergebnisdatei. Dies führt zu einer beschleunigten Verarbeitung in CIB merge und CIB format. Außerdem kann die Datei anschließend nur noch mit CIB-Modulen weiterverarbeitet werden.
Der Parameter --compress erzeugt eine komprimierte Ausgabedatei. Hier wurde die höchste Komprimierungsstufe 9 gewählt. Durch die Komprimierung wird die Dateigröße wesentlich verringert. Zusätzlich --short-tokens zu verwenden, würde keinen weiteren spürbaren Größenvorteil bringen.
Mit dem Parameter --filter werden die Feldinhalte nicht ausgewertet. Die Belegung „f“ (fast) verhindert dabei auch, dass die Feldinhalte geparst und übersetzt werden.
Eine weitere Möglichkeit, nicht benötigte Felder aus dem RTF herauszufiltern, besteht darin, den Parameter --field-results zu verwenden, der alle Field-Results entfernt, die in CIB format keine Rolle spielen. Diese Field-Results kommen vor allem dann im RTF vor, wenn mit {INCLUDETEXT} andere Bausteine angezogen werden. Deshalb wird der Parameter im Anwendungsbeispiel Bausteine vorgestellt.
- Weitere Möglichkeiten für zusätzliche Aufrufparameter
Nun soll eine Nachbearbeitung im CIB dialog über Schalter im RTF gesteuert werden. Die Ausgabe soll verschlüsselt erzeugt werden. Die Daten werden von der Anwendung nun in der Codepage PCA erstellt. Im RTF soll nicht für jedes Feld der „\* CHARFORMAT“-Schalter manuell gesetzt werden müssen.
Die Parameterdatei Zusatz_par.par enthält die notwendigen zusätzlichen Parameter, um diesen Sachverhalt zu unterstützen (Zusatz.bat):
cibmrg32.exe --parameterfile=Zusatz_par.par
Beteiligte
Dateien für den Mischlauf
--inputfile=Zusatz_in.rtf --outputfile=!Zusatz_out.rtf --datafile=Adresse_pca.csvZusatzschalter für HTML-Ausgabe verstehen
--html-switchesFeldformatierung
trotz Schalter übernehmen--charformat=plain-values-onlyCSV mit
PCA-Zeichensatz unterstützen--codepage=pcaAusgabe
verschlüsseln--encrypt- Erläuterungen
Im RTF-Baustein Zusatz_in.rtf sind Felder mit Zusatzschaltern definiert, die bei einer Umwandlung nach HTML eine Rolle spielen. In diesem Beispiel handelt es sich um einzeilige Textfelder, die über CIB dialog ausgefüllt werden können ({ REF Vorname\* <cib-formfield type="text" info="Vorname" testvalue="Max" /> }). Um diese Zusatzschalter zu verstehen, muss der Parameter --html-switches gesetzt werden.
Der Parameter --charformat=plain-values-only bewirkt, dass die Felder, die mit einem solchen Zusatzschalter ausgestattet sind, dennoch die Formatierung des Feldes erhalten. In diesem Fall sind die Felder Vorname und Name fett formatiert. Diese werden nach dem Mischlauf auch fett ausgegeben, obwohl sie Zusatzschalter enthalten.
Die verwendete CSV-Datei (Adresse_pca.csv) benutzt den PCA-Zeichensatz. Um die Daten korrekt darzustellen (beispielsweise Umlaute), muss der Parameter --codepage=pca gesetzt werden.
Durch den Parameter --encrypt ist die Ausgabedatei Zusatz_out.rtf verschlüsselt. Eine Weiterverarbeitung mit CIB-Modulen ist weiterhin möglich.
10.2. Anwendungsbeispiel Serienbrief
AllgemeinEinfacher Mischaufruf über die Kommandozeile
Serienbrief mit 3 Datensätzen als Multi-RTF
Serienbrief mit dynamischer Tabelle und Multi-CSV
Abbrechen des Mischlaufs über Fortschrittsanzeige
Serienbrief mit XML-Datenquelle und Aliasdefinition im RTF
Serienbrief mit XML-Datenquelle, Aliasnamen in XML-Datei, Verwendung von Präfixen
Aufruf eines XML-Jobs über Kommandozeile
Aufruf eines XML-Jobs über Java
Verhalten von NEXT bei fehlenden Variablen festlegen
Allgemein
Soll die Zahlungserinnerung aus vorigem Beispiel nicht nur an einen Kunden verschickt werden, sondern an mehrere, kann dies ohne Änderungen am Anschreiben erfolgen. Nur die CSV-Datei muss um die zusätzlichen Daten der weiteren Kunden ergänzt werden. Die automatische Serienbrieffunktionalität ist am einfachsten so zu verstehen, dass um den Text herum eine gedankliche Schleife existiert, die die Steuerdatei weiterschaltet (implizite Schleife). Im Folgenden wird davon ausgegangen, dass Sie sich im Unterverzeichnis Serienbrief befinden.
Die CSV-Datei Adressen.csv enthält 4 Datensätze:
Vorname;Name;Strasse;PLZ;Ort;Geschlecht;KundenNr;AuftragsNr;Betrag Max;Müller;Teststr. 3;99999;Testort;M;0987392;232222-4;123118 Franz;Meier;Teststr. 4;12345;Musterdorf;M;9898989;111111-2;999 Maria;Huber;Teststr. 5;54321;Testheim;W;1234567;876564-1;500 Franziska;Bauer;Teststr. 6;77777;Neumusterdorf;W;6665554;981234-0;3333 Franziska;Bauer;Teststr. 6;77777;Neumusterdorf;W;6665554;981234-0;3333
Einfacher Mischaufruf über die Kommandozeile
Folgender einfacher Kommandozeilenaufruf erzeugt den gewünschten Serienbrief (Serienbrief.bat):
cibmrg32.exe ..\Lueckentext\Anschreiben_in.rtf !Serienbrief_out.rtf Adressen.csv
Das Anschreiben aus dem Lückentext-Beispiel dient als Eingabe, die Ausgabedatei heißt Serienbrief_out.rtf und als Datenquelle wird die erweiterte CSV-Datei mit 4 Datensätzen verwendet. CIB merge erzeugt in diesem Mischlauf automatisch einen Serienbrief, der für jeden Datensatz aus der CSV-Datei eine Zahlungserinnerung (durch Abschnittswechsel voneinander getrennt) enthält. Änderungen bei den Parametern oder im RTF sind nicht notwendig.
Serienbrief mit 3 Datensätzen als Multi-RTF
Es soll nun ein Serienbrief erzeugt werden, der nicht alle Datensätze enthält, sondern nur die ersten drei. Außerdem soll das Ergebnis ein Multi-RTF sein und nicht, wie bisher, ein durch Abschnittswechsel getrenntes RTF. Desweiteren soll die Information geliefert werden, wie viele Dokumente in diesem Mischlauf erzeugt wurden.
Aufgrund der Übersichtlichkeit, wird der Mischlauf wieder über eine Parameterdatei gesteuert, die neben Eingabe-, Ausgabe- und Datendatei die nötigen Parameter enthält, um das gewünschte Ergebnis zu erhalten (Serialletter.bat):
cibmrg32.exe --parameterfile=Serialletter_par.par
Inhalt der Parameterdatei Serialletter_par.par
Fehler
sollen protokolliert werden
--logfile=!Serialletter_log.logBeteiligte
Dateien für den Mischlauf--inputfile=..\Lueckentext\Anschreiben_in.rtf --outputfile=!Serialletter_out.rtf --datafile=Adressen.csvErzeugung eines Multi-RTF
--serialletter=multiAusgabe
der Anzahl der erzeugten Dokumente--statistics=!count.txt -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@ --merge=3
- Erläuterungen:
Der Parameter --merge=3 startet den Mischlauf und verwendet alle zuvor gesetzten Parameter. Die Ziffer 3 gibt an, dass ein Serienbrief erzeugt werden soll, in dem die ersten drei Datensätze aus der Datenquelle verwendet werden.
Mit --serialletter=multi wird der Serienbrief als Multi-RTF erzeugt und nicht, wie default-mäßig eingestellt, ein Dokument, welches durch Abschnittswechsel die verschiedenen Datensätze beinhaltet.
Durch den Parameter --statistics wird eine weitere Datei erzeugt, die die Anzahl der generierten Dokumente enthält. In diesem Fall hat die Datei count.txt den Inhalt:
GeneratedDocumentCount=3
Serienbrief mit dynamischer Tabelle und Multi-CSV
Die Zahlungserinnerung soll nun um weitere Informationen ergänzt werden. Für jeden Kunden soll eine Übersicht der offenen Einzelposten auf einer separaten Seite aufgeführt werden.
Die Einzelposten müssen in geeigneter Form zur Verfügung gestellt werden. Am einfachsten erfolgt dies über eine zusätzliche CSV-Datei Einzelposten.csv. Um zu bestimmen, welche Einzelposten zu welchem Kunden gehören, enthält diese CSV-Datei für jeden Einzelposten die zugehörige Auftragsnummer des Kunden. Nach diesen Auftragsnummern sind die Zeilen sortiert (sowohl in der Datei Adressen.csv, als auch in der Datei Einzelposten.csv).
Nun muss angegeben werden, dass für diesen Mischlauf mehrere CSV-Dateien geladen werden sollen. Dies geschieht mit Hilfe einer Multi-CSV-Datei (multi.csv). Sie enthält die Namen aller CSV-Dateien, die im aktuellen Mischlauf geladen werden sollen. Über die Felder in der Kopfzeile der Multi-CSV-Datei, erhält jede CSV-Datei einen Alias zugeordnet, über den dann im Dokument auf diese CSV Dateien zugegriffen werden kann.
Auszug aus Adressen.csv:
Vorname;Name;Strasse;PLZ;Ort;Geschlecht;KundenNr;AuftragsNr;Betrag Franz;Meier;Teststr. 4;12345;Musterdorf;M;9898989;111111-2;999 Max;Müller;Teststr. 3;99999;Testort;M;0987392;232222-4;123118 …
Auszug aus Einzelposten.csv:
KundeAuftragsNr;Bezeichnung;EinzelBetrag 111111-2;Artikel1;999 232222-4;Artikel1;18 232222-4;Artikel2;123100 …
multi.csv:
Kunden;Einzelposten Adressen.csv;Einzelposten.csv
Im Anschreiben muss eine dynamische Tabelle eingefügt werden, die die einzelnen Posten auflistet.
Nach dem Text des Anschreibens wird hierfür ein Abschnittswechsel eingefügt. Die neue Seite enthält eine Tabelle mit der Auflistung aller zugehörigen Einzelposten. Dies erfolgt über eine Schleife.
Auszug aus Einzelposten_in.rtf
…
Der Auftrag {REF AuftragsNr } setzt sich aus folgenden Einzelposten zusammen:
|
Bezeichnung |
Betrag |
{ IF { = AND({ MERGEREC ?Einzelposten};{ COMPARE { REF AuftragsNr } = { REF KundeAuftragsNr } })} = 1
|
“{ REF Bezeichnung } |
{REF EinzelBetrag} |
{
NEXT Einzelposten }“ \* SOLANGE }
…
Solange ein Einzelposten vorhanden ist (Prüfung mit { MERGEREC ?Einzelposten}) und die KundeAuftragsNr der AuftragsNr des Kunden entspricht (COMPARE { REF AuftragsNr } = { REF KundeAuftragsNr }), wird die Bezeichnung und der Betrag des Einzelpostens in einer Tabelle ausgegeben und in der Einzelposten.csv zum nächsten Datensatz weitergeschaltet ({ NEXT Einzelposten }). Wären die Daten für den Vergleich rein numerisch, könnte auf das COMPARE verzichtet werden.
Die implizite Schleife bei der automatischen Serienbrieffunktionalität schaltet die Steuerdatei weiter. Wenn nun wie in diesem Fall mehrere Steuerdateien am Mischlauf beteiligt sind, würden alle Steuerdateien weitergeschalten werden. Da die Datei Einzelposten.csv jedoch im RTF selbst mit Hilfe des NEXT-Befehls weitergeschaltet wird, ist dies hier unerwünscht. Um das zu vermeiden wird deshalb eine explizite Schleife um das Anschreiben gesetzt und die Serienbrieffunktion ausgeschaltet.
Auszug aus Einzelposten_in.rtf
{ IF {MERGEREC ?Kunden } = 1“
…Hier folgt das komplette Anschreiben…
{ NEXT Kunden }{ IF {MERGEREC ?Kunden } = 1“… Hier Abschnittswechsel …“}“ \*SOLANGE }
Die Schleife durchläuft alle Kunden aus der Datei Adressen.csv und fügt nach jedem Anschreiben einen Abschnittswechsel ein, wenn es noch einen weiteren Kunden gibt.
Folgender Aufruf erzeugt den gewünschten Serienbrief mit dynamischer Tabelle (Einzelposten.bat):
cibmrg32.exe --parameterfile=Einzelposten_par.par
Fehler
sollen protokolliert werden
--logfile=!Einzelposten_log.logBeteiligte
Dateien für den Mischlauf--inputfile=Einzelposten_in.rtf --outputfile=!Einzelposten_out.rtf --datafile=multi.csvBei der Datendatei handelt es sich um eine Multi-CSV
--multidatafile -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@Serienbrieffunktionalität ausschalten
--merge=1- Erläuterungen:
Als Eingabe dient die RTF-Datei Einzelposten_in.rtf. Diese enthält wie beschrieben zwei Schleifen, mit denen die Steuerdateien weitergeschaltet werden.
Der Parameter --multidatafile gibt an, dass es sich bei der Datei, die mit dem Parameter --datafile angegeben wird, um eine Multi-Steuerdatei handelt.
Wie bereits beschrieben, werden die Steuerdateien im RTF selbst weitergeschaltet. Eine Weiterschaltung, die sich durch die automatische Serienbrief-Funktionaltät ergibt, soll unterdrückt werden. Der Parameter --merge=1 führt den Mischlauf als Einzelmischlauf aus. Der Serienbrief wird hier also rein mit Hilfe von RTF-Feldbefehlen erzeugt.
Abbrechen des Mischlaufs über Fortschrittsanzeige
Die RTF-Datei Endlosschleife_in.rtf enthält durch ein vergessenes NEXT-Feld eine Endlosschleife. Unterläuft dem Textprogrammierer ein solcher Fehler, kann der Mischlauf nur über den Task-Manager abgebrochen werden. Um dies zu vermeiden soll im Folgenden ein Fortschrittsdialog angezeigt werden, über den ein Abbruch des Mischlaufs vorgenommen werden kann.
Folgender Aufruf startet den Endlos-Mischlauf mit Fortschrittsanzeige (Endlosschleife.bat):
cibmrg32.exe --parameterfile=Endlosschleife_par.par
Fehler
sollen protokolliert werden
--logfile=!Endlosschleife_log.logBeteiligte
Dateien für den Mischlauf--inputfile=Endlosschleife_in.rtf --outputfile=!Endlosschleife_out.rtf --datafile=multi.csvBei der Datendatei handelt es sich um eine Multi-CSV
--multidatafile -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@Fortschrittsanzeige anzeigen
--dialog=topSerienbrieffunktionalität
ausschalten--merge=1- Erläuterungen:
Als Eingabe dient die RTF-Datei Endlosschleife_in.rtf. Diese produziert beim Mischlauf eine Endlosschleife.
Der Parameter --dialog=top setzt eine Fortschrittsanzeige in den Vordergrund, die auch einen Button zum Abbrechen des Mischlaufs enthält.
Serienbrief mit XML-Datenquelle und Aliasdefinition im RTF
Im Folgenden sollen die Daten nicht als CSV-Dateien übergeben werden, sondern als XML. Die Daten sollen in einer einzigen Datei Daten.xml stehen. Es soll keine Multi-CSV-Datei mehr verwendet werden.
Folgender Auszug aus der Datei Daten.xml zeigt eine mögliche Umsetzung der Daten von CSV nach XML:
<?xml version="1.0" encoding="ISO-8859-1" ?> <root> <data> <Kunden> <Kunde> <Vorname>Franz</Vorname> <Name>Meier</Name> <Strasse>Teststr. 4</Strasse> <PLZ>12345</PLZ> <Ort>Musterdorf</Ort> <Geschlecht>M</Geschlecht> <KundenNr>9898989</KundenNr> <AuftragsNr>111111-2</AuftragsNr> <Betrag>999</Betrag> </Kunde> weitere Kunden ...... </Kunden> <Posten> <Einzelposten> <KundeAuftragsNr>111111-2</KundeAuftragsNr> <Bezeichnung>Artikel1</Bezeichnung> <EinzelBetrag>999</EinzelBetrag> </Einzelposten> weitere Einzelposten.... </Posten> </data> </root>
Die Aliasdefinitionen werden direkt in der RTF-Eingabedatei NextDef_in.rtf mit Hilfe des Befehls { NEXT ”DEF:Aliasname;<Dateipfad>” } angegeben. Mit dieser besonderen Variante des NEXT Schalters kann im laufenden Dokument einem aktuellen Aliasnamen eine neue Steuerdatei zugewiesen werden. Dieser Befehl lädt gleichzeitig automatisch den ersten Datensatz dieser Datei.
In diesem Fall stehen folgende Aliasdefinitionen im RTF:
{ NEXT ”DEF:Kunden;XML:{ REF XmlDateiname };/root/data/Kunden/Kunde“ }
{ NEXT ”DEF:Einzelposten;XML:{ REF XmlDateiname };/root/data/Posten/Einzelposten“ }
Um den Namen der XML-Datei nicht fest im RTF zu verdrahten wird hier stattdessen eine Variable XmlDateiname verwendet. Diese muss von außen über Parameter gesetzt werden. Hinter dem Dateinamen folgt durch Semikolon getrennt die XPath-Angabe zu den jeweiligen Daten. /root/data/Kunden/Kunde liefert alle <Kunde>-Knoten aus der Datei XmlDateiname.
Folgender Aufruf erzeugt den gewünschten Serienbrief mit XML-Datenversorgung (NextDef.bat):
cibmrg32.exe --parameterfile=NextDef_par.par
Fehler
sollen protokolliert werden
--logfile=!NextDef_log.logBeteiligte
Dateien für den Mischlauf--inputfile=NextDef_in.rtf --outputfile=!NextDef_out.rtfSetzen des Dateinamens für die XML-Datenversorgung
--set=XmlDateiname=Daten.xml -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@Serienbrieffunktionalität ausschalten
--merge=1- Erläuterungen:
Als Eingabe dient die RTF-Datei NextDef_in.rtf. Diese enthält auch die Aliasdefinitionen für die XML-Daten.
Der Parameter --set weist der Variablen XmlDateiname den Wert Daten.xml zu. So kann der Dateiname von außen variabel gesetzt werden.
Durch die Aliasdefinitionen im Rohtext ist keine Multi-Steuerdatei mehr erforderlich. Die Parameter --datafile und --multidatafile können daher entfallen.
Da auch hier die Serie durch explizite Schleifen im Rohtext erzeugt wird, wird mit dem Parameter --merge=1 die Serienbrieffunktion ausgeschaltet.
Serienbrief mit XML-Datenquelle, Aliasnamen in XML-Datei, Verwendung von Präfixen
Jetzt sollen die Aliasdefinitionen nicht mehr im Rohtext stehen, sondern zusammen mit den Daten in der XML-Datei. Außerdem soll durch Verwendung von Präfixen im Rohtext die Eindeutigkeit der Variablen gewährleistet werden. Diese Präfixe sollen mit dem Trennzeichen „.“ dem Variablennamen vorangestellt werden.
Um dies zu realisieren, wird die Datei Daten.xml folgendermaßen erweitert. (Daten_mitAlias.xml)
<multi> <Kunden>XML:$(this);/root/data/Kunden/Kunde</Kunden> <Einzelposten>XML:$(this);/root/data/Posten/Einzelposten</Einzelposten> </multi>
Das Konstrukt XML:$(this) gibt an, dass sich eine Aliasdefinition auf Daten bezieht, die in der selben XML-Datei stehen, in der sich die Aliasdefinition befindet.
Die Eingabedatei muss so erweitert werden, dass allen Variablennamen der jeweilige Alias gefolgt von einem Punkt vorangestellt wird.
Aus { REF Vorname } wird demnach { REF Kunden.Vorname } usw..
Wird die Variable Betrag z.B. sowohl bei Einzelposten, als auch bei Kunden verwendet, ist durch das Präfix die Eindeutigkeit sichergestellt. Die Parameter können wie immer über eine Parameterdatei definiert werden. Eine Alternative dazu wäre, die Parameter und Daten zusammen in einem sogenannten XML-Job bereitzustellen. Dieser kann ebenfalls über Kommandozeile ausgeführt werden. Ausführungsvarianten über Java und C++ werden im Folgenden ebenfalls erläutert.
Folgender Aufruf erzeugt den gewünschten Serienbrief mit XML-Datenversorgung (Prefix.bat):
cibmrg32.exe --parameterfile=Prefix_par.par
Inhalt der Datei Prefix_par.par:
Fehler
sollen protokolliert werden
--logfile=!Prefix_log.logBeteiligte
Dateien für den Mischlauf--inputfile=Prefix_in.rtf --outputfile=!Prefix_out.rtfPfad zur XML-Datei
--headerfile=XML:Daten_mitAlias.xmlXPath
zum Zugriff auf die Aliasdefinitionen--datafile=/root/multi --multidatafileTrennzeichen zwischen Alias und Variablennamen (Punkt ist Default)
--prefix-delimiter -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@Serienbrieffunktionalität ausschalten
--merge=1- Erläuterungen:
Als Eingabe dient die RTF-Datei Prefix_in.rtf, welche wie beschrieben um Aliasnamen bei den Variablen erweitert wurde.
Der Parameter --headerfile gibt die zu verwendende Datenquelle (Daten_mitAlias.xml) an und der Parameter --datafile den XPath zu den Aliasnamen.
Durch Hinzufügen des Aufrufparameters --multidatafile, interpretiert CIB merge dann die Aliasdefinitionen selbständig und stellt die zugehörigen Aliasnamen bereit.
Dadurch können die {next}-DEF-Feldanweisungen im Rohtext entfallen.
Der Parameter --prefix-delimiter definiert den Punkt als Trennzeichen zwischen Alias und Variablennamen. Der Rohtext muss so erweitert werden, dass allen Variablen der entsprechende Alias gefolgt von diesem Trennzeichen vorangestellt wird.
Das Ergebnis wird in die Datei Prefix_out.rtf geschrieben.
Aufruf eines XML-Jobs über Kommandozeile
Liegen die Daten ohnehin als XML vor, ist es möglich, die Parameter ebenfalls in einem XML zu setzen. So lassen sich die Daten und die Parameter in einer einzigen XML-Datei unterbringen. In einem sogenannten merge-Step werden alle notwendigen Properties gesetzt. Diese Job-XML (PrefixJob.xml) kann dann folgendermaßen über die Kommandozeile aufgerufen werden (PrefixJob.bat):
cibrsh.exe -d PrefixJob.xml
Auszug aus der Datei PrefixJob.xml (Kommentare beginnen mit <!-- und enden mit -->)
<step name="merge" command="merge"> <!-- Liste der Properties für diesen Step --> <properties> <!-- Daten werden in diesem XML mitgegeben -->
<property name="--logfile">!PrefixJob_log.log</property>
<property name="--inputfile">Prefix_in.rtf</property>
<property name="--outputfile">!Prefix_out.rtf</property>
<property name="-h">XML:$(inline)</property>
<property name="--datafile">/root/multi</property>
<property name="--multidatafile"/>
<property name="--prefix-delimiter"/>
<property name="-@">1</property </properties> </step>
Die Daten, die zuvor über die Datei Daten_mitAlias.xml bereitgestellt wurden, können direkt mit in der PrefixJob.xml übergeben werden. Dies wird mit XML:$(inline) beim Parameter -h angegeben. Hier muss explizit die Kurzschreibweise -h verwendet werden, da diese genau so erwartet wird. Das gleiche gilt für -@.
Die Daten aus Daten_mitAlias.xml können dann direkt in die PrefixJob.xml übernommen werden, indem sie direkt unterhalb des <root>-Knotens eingefügt werden.
Aufruf eines XML-Jobs über Java
Wird ein XML-Job verwendet, kann dieser auch über Java ausgeführt werden. Hierfür wird die Klasse JCibJobJob verwendet. In folgendem kleinen Java-Programm wird ebenfalls die Datei PrefixJob.xml ausgeführt:
Auszug aus MergeJob.java:
…
JCibJobJob t_Job = new JCibJobJob();
t_Job.initialize();
if (!t_Job.isInitialized())
{
// Fehler beim Initialisieren
System.err.println("Fehler beim Initialisieren");
System.exit(1);
}
try
{
t_Job.setProperty(ICibJobJob.PROPERTY_INPUTFILENAME,
"PrefixJob.xml");
//Job ausführen
t_Job.execute();
//Fehlerbehandlung
int t_Error = ((Integer)t_Job.getProperty(IComodJob.PROPERTY_ERROR)).intValue();
if (t_Error != 0)
{
// Fehler beim Ausführen des Jobs
String t_Errortext =
(String)t_Job.getProperty(IComodJob.PROPERTY_ERRORTEXT);
System.err.println("Fehler beim Ausführen: "+t_Error+" "+t_Errortext);
}
}
finally
{
t_Job.terminate();
}
…
Verhalten von NEXT bei fehlenden Variablen festlegen
Im Folgenden fehlt in einem Datensatz ein XML-Knoten. Die Datei Daten.xml wird so angepasst, dass im dritten Kunden-Datensatz der Knoten <KundenNr> fehlt (Daten_NextMode.xml). Im Ergebnis würde an der Stelle, an der diese Variable eingesetzt wird, einfach nichts stehen. Im Folgenden soll eine Variable, die in einem Datensatz enthalten ist, im nächsten jedoch nicht mehr, gelöscht werden. Dies soll zu einem Fehler führen und der Mischvorgang soll abgebrochen werden.
Folgender Aufruf erzeugt das gewünschte Verhalten (NextMode.bat):
cibmrg32.exe --parameterfile=NextMode_par.par
Inhalt der Datei NextMode_par.par:
Fehler
sollen protokolliert werden
--logfile=!NextMode_log.logBeteiligte
Dateien für den Mischlauf--inputfile=NextDef_in.rtf --outputfile=!NextMode_out.rtfSetzen des Dateinamens für die XML-Datenversorgung
--set=XmlDateiname=Daten_NextMode.xml -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@Verhalten für Next festlegen, wenn Variable nicht vorhanden
--next-mode=deleteSerienbrieffunktionalität
ausschalten--merge=1- Erläuterungen:
Der Parameter --next-mode bewirkt mit der Belegung „delete“, dass die fehlende Variable KundenNr gelöscht wird und somit nicht mehr definiert ist. Es kommt zu einem Fehler
unbekannte
Variable:
Name: KundenNr
und der Mischvorgang wird abgebrochen.
10.3. Anwendungsbeispiel Report mit mehreren Bausteinen
AllgemeinVerwendung von Unterverzeichnissen für Datenquellen und RTF-Bausteine
Optimierungen für Bausteine mit neuen Farben, Schriften, Listen steuern
Zeipunkt des Abbruchs beim Auftreten von Fehlern festlegen
Umgang mit unversorgten Feldern
Entfernen von Field-Results aus dem Rohtext
Einfügen dynamischer Geschäftsgrafik und Einbetten von Grafiken
Analyse der Feldstruktur in RTF-Bausteinen
Allgemein
Im Folgenden wird davon ausgegangen, dass Sie sich im Unterverzeichnis „Bausteine“ befinden. Das folgende Beispiel beinhaltet ein Anschreiben einer Bank an einen Kunden, das über den aktuellen Status seiner Konten informiert. Es enthält eine Auflistung seiner Konten, inklusive Kontoart, aktuellen Salden und eine Summe der Salden. Außerdem ist ein Bankenlogo eingebunden. Dies erfolgt im RTF über den Feldbefehl { INCLUDEPICTURE „Logo.jpg“}.
Die Daten liegen in mehreren CSV-Dateien vor. Diese beinhalten Kundendaten (knd_kunde.csv), Informationen über seine Konten (kont_konten.csv), die Daten der Bank (bnk_bank.csv) und Informationen zu seinem Ansprechpartner (ber_berater.csv). Es ist sinnvoll die Datenquellen in einem separaten Verzeichnis abzulegen. In diesem Fall liegen die Dateien im Unterverzeichnis „csv“.
Dieses Mal ist der Brief nicht in einer einzigen RTF-Datei untergebracht, sondern auf mehrere Bausteine aufgeteilt. Diese RTF-Bausteine befinden sich ebenfalls in einem separaten Unterverzeichnis „templates“. Es gibt einen Wurzelbaustein (wurzelbaustein.rtf), der mehrere Bausteine anzieht. Dies geschieht mit Hilfe des Feldbefehls { INCLUDETEXT „Baustein.rtf“ }. Unter anderem gibt es Bausteine für Kopf- und Fußzeilen (unterschiedliche für erste Seite und Folgeseiten), für das Anschreiben und für die Kontenübersicht.
Die Kontenübersicht ist als dynamische Tabelle realisiert, welche bereits im Anwendungsbeispiel Serienbrief näher erklärt wurde:
|
LfdNr |
Kontonummer |
Saldo |
Kontoart |
{ SET Saldo_Summe 0 } { IF { MERGEREC ?Konten } = 1
|
“{ MERGEREC Konten } |
{ REF kont_kontonummer } |
{ REF kont_saldo \# 0,00 } |
{ REF kont_kontoart } |
{ SET Saldo_Summe { = { REF Saldo_Summe } + { REF kont_saldo } } }{ NEXT Konten }" \* SOLANGE }
|
Summe Salden |
{ REF Saldo_Summe \# 0,00 } |
Um eine Summe über die Salden zu bilden, wird vor der Schleife eine Variable Saldo_Summe mit Hilfe des SET-Feldbefehls definiert und auf 0 gesetzt. In der Schleife wird für jedes Konto der zugehörige Saldo hinzuaddiert. Am Ende wird eine Gesamtsumme ausgegeben.
Das Ergebnis soll ebenfalls in ein eigenes Unterverzeichnis „result“ geschrieben werden.
Verwendung von Unterverzeichnissen für Datenquellen und RTF-Bausteine
Folgender Aufruf erzeugt den fertigen Brief inklusive Kontenübersicht (Bausteine.bat):
cibmrg32.exe --parameterfile=Bausteine_par.par
Inhalt der Datei Bausteine_par.par
Fehler
sollen protokolliert werden
--logfile=!Bausteine_log.logDatenquellen
sind unter diesem Pfad zu finden--target-directory=csvBausteine
befinden sich (relativ zu target) hier--source-directory=..\templatesEingabe-Datei
(in source zu finden)--inputfile=wurzelbaustein.rtfAusgabe
explizit in eigenes Verzeichnis--outputfile=!..\result\Kontenuebersicht.rtfDatenquelle
ist Multi-CSV--datafile=multi.csv --multidatafile --charformat
- Erläuterungen
Das Beispiel setzt mit Hilfe des Parameters --target-directory die Pfadangabe für die Datendateien. Somit ist keine explizite Pfadangabe beim Parameter --datafile erforderlich. Hier reicht es, den Dateinamen der Multi-CSV anzugeben. Alle weiteren CSV-Dateien werden dann ebenfalls in diesem Verzeichnis erwartet.
Der Parameter --source-directory setzt das Verzeichnis, in dem das RTF-Wurzeldokument und die RTF-Bausteine erwartet werden. Der Pfad ist relativ zu dem Pfad, der mit --target-directory angegeben wurde. Durch das Setzen dieses Aufrufparameters, ist keine explizite Pfadangabe beim Parameter --inputfile erforderlich. Hier reicht es, den Namen des Wurzelbausteins anzugeben. Alle weiteren Bausteine werden dann ebenfalls in diesem Verzeichnis erwartet. (sofern keine expliziten Pfadangaben mit INCLUDETEXT gemacht werden).
Das Ergebnis Kontenuebersicht.rtf wird durch eine explizite Pfadangabe in das Unterverzeichnis „result“ geschrieben. Wäre hier kein Pfad angegeben, würde das Ergebnis nach --target-directory geschrieben werden.
Der Parameter --multidatafile gibt an, dass es sich bei der Datei, die mit dem Parameter --datafile angegeben wird, um eine Multi-Steuerdatei handelt.
Optimierungen für Bausteine mit neuen Farben, Schriften, Listen steuern
In den Bausteinen werden neue Farben, Schriften und Listen verwendet. Standardmäßig sind diese auch im Ergebnisdokument enthalten, da der RTF-Kopf am Ende neu geschrieben wird. Hier sind unterschiedliche Optimierungen möglich, die wahlweise durch den Benutzer abgeschaltet werden können. Im Folgenden sollen die neuen Schriften ignoriert werden, alle Farben sollen aber enthalten sein, auch die, die nicht benutzt werden. Dies ist zum Beispiel dann sinnvoll, wenn ein Drucker nur bestimmte Schriftarten drucken kann. Da das Dokument nach dem Mischlauf eventuell noch bearbeitet wird, sollen hier auch alle verwendeten Listen zur Verfügung stehen. Unbenutzte Listen sollen jedoch entfernt werden.
Folgender Aufruf erzeugt das gewünschte Ergebnis (Header.bat):
cibmrg32.exe --parameterfile=Header_par.par
Auszug aus Header_par.par:
… --replace-header=automatic --fonts=keep --colors=expand --lists=adjust
- Erläuterungen
Ohne den Parameter --replace-header werden sowohl die Schriften und Listen, als auch die Farben in das Ergebnis-RTF übernommen. --replace-header=automatic bewirkt hier, dass der RTF-Kopf unter Berücksichtigung der Belegungen der Parameter --fonts, --lists und --colors neu geschrieben wird.
Der Parameter --fonts mit der Belegung „keep“ bewirkt, dass die Haupt-Schriftartentabelle nicht um die neuen Schriften erweitert wird. Es wird auch keine zusätzliche Optimierung durchgeführt, welche die unbenutzen Schriftarten entfernt.
Der Parameter --colors mit der Belegung „expand“ bewirkt, dass die Haupt-Farbtabelle um neue Farben erweitert wird und unbenutzte Farben nicht entfernt werden.
Der Parameter --lists mit der Belegung „adjust“ bewirkt, dass die Haupt-Listentabelle um neue Listen erweitert wird, unbenutzte Listen aber entfernt werden.
Zeipunkt des Abbruchs beim Auftreten von Fehlern festlegen
CIB merge bricht die Verarbeitung ab, wenn zum Beispiel eine Variable eingesetzt wird, die nicht definiert ist. Im Folgenden wird statt der korrekten CSV-Datei kont_konten.csv die CSV-Datei kont_konten_undef.csv verwendet. In dieser ist die Variable kont_kontoart falsch geschrieben (kont_kontart). Wird nun ein Mischlauf gestartet, der diese fehlerhafte CSV-Datei verwendet, entsteht ein Ergebnis-RTF mit einer defekten Tabelle. (OhneBreak_out.rtf).
Folgender Aufruf erzeugt das RTF mit defekter Tabelle (OhneBreak.bat):
cibmrg32.exe --parameterfile=OhneBreak_par.par
Auszug aus OhneBreak_par.par:
… --outputfile=!..\result\OhneBreak_out.rtf --datafile=multi_undef.csv …
Der Mischlauf soll nun, wenn möglich, fortgesetzt werden, obwohl die Variable kont_kontoart nicht definiert ist. Die Tabelle soll noch so ausgegeben werden, dass ein gültiges RTF entsteht. Anschließend soll der Mischvorgang aber abgebrochen werden.
Folgender Aufruf erzeugt das gewünschte Ergebnis (BreakLoop.bat):
cibmrg32.exe --parameterfile=BreakLoop_par.par
Folgender Parameter wird hier zusätzlich gesetzt:
--break=loop
Jetzt soll auch bei auftretenden Fehlern der Mischvorgang bis zum Ende durchgeführt werden und einen Fehler zurückliefern.
Folgender Aufruf erzeugt das gewünschte Ergebnis (BreakNever.bat):
cibmrg32.exe --parameterfile=BreakNever_par.par
Folgender Parameter wird hier gesetzt:
--break=never
- Erläuterungen
Der Parameter --break verschiebt den Zeitpunkt, an dem CIB merge im Fehlerfall den Mischvorgang abbricht.
Mit --break=loop wird folgendes Verhalten erreicht: falls sich der Mischlauf gerade in einer Schleife befindet, wird diese ab dem Fehler nur noch bis zum Ende durchlaufen, also nicht wiederholt. Direkt anschließend wird der Mischvorgang abgebrochen.
--break=never bewirkt, dass CIB merge ungeachtet aller auftretenden Fehler den Mischauftrag bis zum Ende durchführt und den Fehlercode des ersten aufgetretenen Fehlers zurück gibt.
Umgang mit unversorgten Feldern
In einigen Fällen kann es erwünscht sein, dass eine bestimmte Variable nicht durch die Datenquellen versorgt wird (z.B. für eine eventuelle spätere Restdatenerfassung). Im Folgenden wird absichtlich die Variable kont_kontoart nicht definiert (es können die gleichen Eingabedateien, wie im Beispiel zuvor verwendet werden). In diesem Fall soll der Mischvorgang fortgesetzt werden und alle nicht versorgten Felder sollen als REF-Felder in der Ausgabedatei erhalten bleiben.
Folgender Aufruf erzeugt das gewünschte Ergebnis (KeepFields.bat):
cibmrg32.exe --parameterfile=KeepFields_par.par
Folgender Parameter wird hier zusätzlich gesetzt:
--keep-fields=unresolved-ref- Erläuterungen
Der Parameter --keep-fields=unresolved-ref sorgt dafür, dass der Mischvorgang trotz fehlender Datenversorgung für die Variable kont_kontoart fortgeführt wird und das REF-Feld für kont_kontoart in der Ausgabedatei KeepFields_out.rtf erhalten bleibt.
Entfernen von Field-Results aus dem Rohtext
Durch MS Word werden sogenannte Field-Reuslts in den Rohtext eingefügt, wovon die meisten von den CIB-Modulen nicht benötigt werden. Durch die INCLUDETEXT-Anweisungen in wurzelbaustein.rtf enthält das RTF einige dieser unnötigen Field-Results. Um die Dateigröße zu optimieren, können die meisten davon entfernt werden. Das Ergebnis soll keine unnötigen Field-Results mehr enthalten.
Folgender Aufruf erzeugt das gewünschte Ergebnis (FieldResults.bat):
cibmrg32.exe
--parameterfile=FieldResults_par.par
Folgende Parameter werden hier gesetzt:
Fehler
sollen protokolliert werden
--logfile=!FieldResults_log.logDatenquellen
sind unter diesem Pfad zu finden--target-directory=csvBausteine
befinden sich (relativ zu target) hier--source-directory=..\templatesEingabe-Datei
(in source zu finden)--inputfile=wurzelbaustein.rtfAusgabe
explizit in eigenes Verzeichnis--outputfile=!..\result\wurzelbaustein_FieldResults.rtfField-results
entfernen--field-results=pKeine
Inhalte einmischen--filter=f- Erläuterungen
Die durch MS Word eingefügten unnötigen Field-Results werden mit Hilfe des Parameter --field-results entfernt. Durch die Belegung mit „p“ bleiben diejenigen erhalten, die zur Positionierung von Bildern notwendig sind.
Einfügen dynamischer Geschäftsgrafik und Einbetten von Grafiken
Im Folgenden soll die Übersicht der Kontoarten grafisch in einem Tortendiagramm dargestellt werden. Dazu wird eine neue CSV-Datei erstellt, die die Aufteilung des Vermögens je Anlageform enthält (Anlageform.csv). Diese CSV-Datei sieht folgendermaßen aus:
Anlageform;Wert;Legende Girokonto;530,46;Girokonto 0,56% Sparkonto;16.700,00;Sparkonto 17,67% Festgeld;74.000,00;Festgeld 78,29% Depot;3.288,33;Depot 3,48%
In dieser Datei ist die Legende des Diagramms enthalten und die Summe der Salden pro Anlageform. Die Datei Vermoegensstruktur_torte.emf enthält die Grafikschablone, die zur Erzeugung der dynamischen Geschäftsgrafik herangezogen werden soll. Diese Grafik und das Logo (Logo.jpg), das im Baustein Logo.rtf eingefügt wird, sollen im Ergebnis-RTF eingebettet werden.
Folgender Aufruf erzeugt das gewünschte Ergebnis (Chart.bat):
cibmrg32.exe --parameterfile=Chart_par.par
Folgende Parameter werden hier gesetzt:
Fehler
sollen protokolliert werden
--logfile=!Chart_log.logDatenquellen
sind unter diesem Pfad zu finden--target-directory=csvBausteine
befinden sich (relativ zu target) hier--source-directory=..\templatesEingabe-Datei
(in source zu finden)--inputfile=wurzelbaustein_chart.rtfAusgabe explizit
in eigenes Verzeichnis--outputfile=!..\result\Chart_out.rtfDatenquelle
ist Multi-CSV--datafile=multi_chart.csv --multidatafile --charformatSetzen der chart-Parameter
--chart-source=file --chart-target=embed --merge=1
Erläuterungen
Mit --chart-source=file wird angegeben, dass die Geschäftsgrafik aus der mit { INCLUDEPICTURE } eingefügten Grafik berechnet werden soll.
Der Parameter --chart-target=embed gibt an, dass alle Grafiken in das Ergebnis-RTF eingebettet werden sollen (sowohl Chart- als auch Nicht-Chart-Grafiken).
Analyse der Feldstruktur in RTF-Bausteinen
Im Folgenden soll die Feldstruktur der RTF-Bausteine ermittelt werden. Das Ergebnis soll in eine CSV-Datei Felder.csv geschrieben werden. Diese enthält dann alle vorkommenden Variablen, die durch eine Applikation ausgewertet werden könnten.
Folgender Aufruf erzeugt das gewünschte Ergebnis (Analyse.bat):
cibmrg32.exe --parameterfile=Analyse_par.par
Folgende Parameter werden hier gesetzt:
--logfile=!Felder.csv -mPfad;Feld;Wert --logfile=!Analyse_log.log --source-directory=templates --outputfile=- --analyse=+Felder.csv# für jeden Text
--inputfile=Basisbaustein.rtf -m@ --filter --inputfile=Bezug.rtf -m@ --filter... für jeden RTF-Baustein...
--inputfile=wurzelbaustein.rtf -m@ --filter -mdone
- Erläuterungen
Der Parameter --analyse erzeugt die Datei Felder.csv, die nach dem Analyse-Lauf folgendermaßen aussieht (Auszug):
Pfad;Feld;Wert Basisbaustein.rtf;REF;knd_geschlecht Basisbaustein.rtf;REF;knd_nachname Basisbaustein.rtf;REF;ber_vorname Basisbaustein.rtf;REF;ber_nachname Basisbaustein.rtf;REF;ber_vorname Basisbaustein.rtf;REF;ber_nachname Bezug.rtf;REF;knd_bezug Briefkopf.rtf;REF;bnk_name Briefkopf.rtf;REF;bnk_erg_1 Briefkopf.rtf;REF;bnk_erg_2 Datum.rtf;REF;bnk_datumort … Logo.rtf;INCLUDEPICTURE;Logo.jpg wurzelbaustein.rtf;INCLUDETEXT;?KopfFolgeSeiten.rtf wurzelbaustein.rtf;INCLUDETEXT;KopfFolgeSeiten.rtf wurzelbaustein.rtf;INCLUDETEXT;?FussFolgeSeiten.rtf wurzelbaustein.rtf;INCLUDETEXT;FussFolgeSeiten.rtf wurzelbaustein.rtf;INCLUDETEXT;?FussErsteSeite.rtf wurzelbaustein.rtf;INCLUDETEXT;FussErsteSeite.rtf wurzelbaustein.rtf;INCLUDETEXT;?Briefkopf.rtf …
Diese Ausgabedatei bietet somit eine Übersicht über alle vorkommenden Variablen. Es wird kein Ausgabe-RTF erzeugt (--outputfile=-) und es werden keine Felder ausgewertet (--filter).
Dateilose Dateneingabe mit directory-Parametern:
|
Summe Salden |
{ REF Saldo_Summe \# 0,00 } |
11. Schneller Einstieg
Dieses Kapitel zeigt Ihnen in einem Kurzüberblick eine mögliche Nutzung von CIB merge aus einer Kundenanwendung. Die Beispiele nutzen keineswegs den vollen Funktionsumfang, sondern demonstrieren das grundsätzliche Prinzip beim Umgang mit CIB merge.
Für Ihren konkreten Anwendungsfall können Sie auch gerne beim CIB Support nach weiteren Beispielen rückfragen.
Hinweis:
Zur schnellen Benutzung von CIB merge über die CIB runshell aus der Kommandozeile, befinden sich im Übergabe-Paket fertige Beispiele. Die Aufrufe der CIB runshell sind in Batch-Dateien fertig vorgegeben.
Einbindung von CIB merge als C++ Codebeispiel
Im Kapitel Anwendungsbeispiele sind bereits Codebeispiele vorhanden, die demonstrieren, wie CIB merge aus C++ heraus aufgerufen werden kann. Ein Beispiel zeigt den Aufruf von CIB merge mit Übergabe von mehreren einzelnen Parametern und ein weiteres Beispiel verwendet eine Parameterdatei.
Wenn Sie CIB merge direkt in ihr C++ Programm einbinden möchten, stellt Ihnen der CIB Support gerne ein Beispiel bereit“.
Einbindung von CIB merge als Java Codebeispiel
Im Kapitel Anwendungsbeispiele sind bereits Codebeispiele vorhanden, die demonstrieren, wie CIB merge aus JAVA heraus aufgerufen werden kann. Ein Beispiel zeigt den Aufruf von CIB merge mit Übergabe von mehreren einzelnen Parametern und ein weiteres Beispiel verwendet eine Parameterdatei.
Wenn Sie CIB merge direkt in ihr C++ Programm einbinden möchten, stellt Ihnen der CIB Support gerne ein Beispiel bereit“.
Einbindung von CIB merge als VB Codebeispiel
Wenn Sie CIB merge direkt in ihr VB-Programm einbinden möchten, stellt Ihnen der CIB Support gerne ein Beispiel bereit“.
Einbindung von CIB merge als Delphi Codebeispiel
Wenn Sie CIB merge direkt in ihr Delphi-Programm einbinden möchten, stellt Ihnen der CIB Support gerne ein Beispiel bereit“.
Hinweis zu GZIP unter JAVA
CIB merge ermöglicht mit –z eine ZLIB Komprimierung mit Mehrfachheadern. Unter JAVA ist es nicht möglich solche Dateien mit der GZIP Klasse sofort zu entpacken.
Deshalb unten aufgeführter Beispielcode, der das unterstützt:
/*
* Created on 01.08.2006
* <p>
* It was not possible to take the FilterInputStream as a base class because I
* had to call super(gzin) in the constructor. This is supposed to be the first
* line but there gzin is not initialized yet. Further is was not possible to
* call super(new ExtendedGZIPInputStream(...)) because the nested class cannot
* access the not then initialized enclosing class.
* </p>
*/
package de.cib.java.util.zip;
import java.io.ByteArrayInputStream;
import java.io.EOFException;
import java.io.IOException;
import java.io.InputStream;
import java.io.SequenceInputStream;
import java.util.zip.GZIPInputStream;
/**
* <p>
* This is a GZIPInputStream capable of reading a gzipped input stream
* consisting of multiple members.
* </p>
* <p>
* See RFC 1952 about gzip and multiple members.
* </p>
* <p>
* This implementation is based upon the java.io.GZIPInputStream which is not
* capable of reading further than the first member. For further information on
* the implementation see the comment for the java file.
* </p>
*
* @author CIB consulting GmbH, Tammo Wüsthoff
*/
public class MultipleMemberGZIPInputStream extends InputStream {
/**
* I need some data which is not public. So I have to subclass.
*
* @author Tammo
*/
protected class ExtendedGZIPInputStream extends GZIPInputStream {
/**
* Uses a default buffer size * * @param in * gzipped input stream * @throws IOException */ protected ExtendedGZIPInputStream(InputStream in) throws IOException { super(in);
}
/** * @param in * gzipped input stream * @param size * buffer size * @throws java.io.IOException */ public ExtendedGZIPInputStream(InputStream in, int size) throws IOException { super(in, size);
} /** * @return a new InputStream with the unprocessed bytes only or null if * there were none */ public InputStream createInputStreamForUnprocessedBytes() { final int n = getRemaining(); if (n > 0) { return new ByteArrayInputStream(buf, len - n, n); } return null;
}
/** * @return number of unprocessed bytes */ public int getRemaining() { return inf == null ? 0 : inf.getRemaining();
}
/** * @return true iff there is unprocessed data */ public boolean hasRemaining() { return getRemaining() > 0;
}
}
/**
* Unfortunately the trailer is checked in the unprocessed part of the
* buffer inside the original GZIPInputStream. Well, if I want to continue
* with the unprocessed data then I have to skip the trailer again. The
* readTrailer() is private. So I have to guess the length. But the 8 bytes
* are part of the specification RFC 1952.
*/ protected static final int trailerLength = 8;
/**
* gzipped input stream maybe with prepended unprocessed data
*/ protected InputStream base;
/**
* from time to time newly constructed input stream (once per gzip member)
*/ protected ExtendedGZIPInputStream gzin;
/**
* buffer size if given, -1 else, used for reconstruction of the member gzip
*/ private final int size;
/**
* Uses a default buffer size
*
* @param in * gzipped input stream
* @throws IOException
*/ public MultipleMemberGZIPInputStream(InputStream in) throws IOException { super(); base = in;
size = -1; gzin = new ExtendedGZIPInputStream(in);
}
/**
* @param in * gzipped input stream
* @param size * buffer size
* @throws IOException
*/
public MultipleMemberGZIPInputStream(InputStream in, int size)
throws IOException {
super();
base = in;
this.size = size;
gzin = new ExtendedGZIPInputStream(in, size);
}
/**
* @see java.io.InputStream#available()
*/ public int available() throws IOException { if (gzin.available() > 0 || base.available() > 0 || gzin.hasRemaining()) return 1; return 0;
}
/**
* @see java.io.InputStream#close()
*/ public void close() throws IOException { gzin.close();
}
/**
* @see java.io.InputStream#mark(int)
*/ public synchronized void mark(int readlimit) { gzin.mark(readlimit);
}
/**
* @see java.io.InputStream#markSupported()
*/ public boolean markSupported() { return gzin.markSupported();
}
/**
* read a single byte retrying if a gzip member ends just here
*
* @see java.io.InputStream#read()
*/
public int read() throws IOException { int value; do { value = gzin.read();
} while (value == -1 && retry()); return value;
}
/**
* @see java.io.InputStream#read(byte[])
*/
public int read(byte[] b) throws IOException { return read(b, 0, b.length);
}
/**
* read a sequence of bytes retrying if a gzip member ends just here
*
* @see java.io.InputStream#read(byte[], int, int)
*/ public int read(byte[] b, int off, int len) throws IOException { int n; do { n = gzin.read(b, off, len);
} while (n == -1 && retry()); return n;
}
/**
* @see java.io.InputStream#reset()
*/ public synchronized void reset() throws IOException { gzin.reset();
}
/**
* If unprocessed input is available then prepend the remaining bytes to the
* input and skip the trailer. If no unprocessed input is available or after
* skipping the trailer look if there are more bytes in the input. If yes
* then make a new gzip input.
*
* @return true iff further data available
* @throws IOException
*/
protected boolean retry() throws IOException { InputStream unprocessed = gzin.createInputStreamForUnprocessedBytes(); if (unprocessed != null) {
base = new SequenceInputStream(unprocessed, base); base.skip(Math.min(trailerLength, gzin.getRemaining()));
}
// well, looking if there are more bytes using available fails for
// several reasons; other solution: try to initialize gzin; this should // read the gzip header or give eof try { if (size == -1) { gzin = new ExtendedGZIPInputStream(base); } else { gzin = new ExtendedGZIPInputStream(base, size); }
} catch (EOFException e) { return false;
} return true;
}
/**
* @see java.io.InputStream#skip(long)
*/ public long skip(long n) throws IOException { return gzin.skip(n);
}
}
private static void testGunzip() {
try {
FileInputStream fin = new FileInputStream( "d:\\cib\\temp\\output.rtf");
MultipleMemberGZIPInputStream gzin = new MultipleMemberGZIPInputStream(
fin);
StringBuffer stringbuffer = new StringBuffer();
final int size = 512;
byte[] bytebuffer = new byte[size];
char[] charbuffer = new char[size * 4];
int read;
while ((read = gzin.read(bytebuffer)) != -1) {
int converted = ByteToCharConverter.getDefault().convert(
bytebuffer, 0, read, charbuffer, 0, charbuffer.length);
stringbuffer.append(charbuffer, 0, converted);
}
String output = stringbuffer.toString();
System.out.println(output);
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
12. Sonstiges
12.1. Fehlerbehandlung
CIB merge liefert beim Mischen einen Rückgabewertes ungleich 0 wenn ein Fehler aufgetreten ist. Zusätzlich kann bei einem CIB merge Lauf eine Fehlerprotokolldatei geschrieben werden, die ausführliche Informationen zu dem aufgetretenen Fehler enthält.
Der Rückgabewert kann von der Anwendung ausgewertet werden, siehe Kapitel Programmrückgabewerte.
Die Fehlerprotokolldatei kann vom Anwendungsentwickler per Fehlerkategorien und Diagnoseleveln vielseitig skaliert werden. Sie hilft besonders dem Rohtextentwickler, kann aber auch dem Benutzer zur Fehleranalyse dienen. Siehe dazu Kapitel Fehlerprotokolldatei.
CIB merge kann optional ausführliche Tracedateien erzeugen. Diese sind für den CIB Support bei der Analyse von komplexen Supportfällen oft sehr nützlich. Siehe Kapitel Tracemöglichkeiten.
12.2. Programmrückgabewerte
Nachfolgende Aufstellung gibt eine Übersicht über mögliche Fehlerrückgaben durch CIB merge. Es gibt für Anwendungsentwickler CoMod Schnittstellen um zu einer Fehlernummer direkt den Text abzufragen und dem Endanwender mit konkreten Hinweisen weiterzuhelfen.
Mit der Version 3.11 von CIB merge wurden die Rückgabewerte geändert. Im Wesentlichen wurden sie aus dem Bereich 0-20 in den neuen Bereich 800-820 verschoben. Zukünftig sind die Fehlernummern 800-850 für CIB merge reserviert.
Um die Fehlernummern älterer CIB merge-Versionen nachzuschlagen, bitte addieren Sie 800 zum Betrag der hinteren beiden Stellen. Beispiele: 4 -> 804, 302 -> 802.
Die Fehlernummern haben folgende Bedeutung:
|
Rückgabewert |
Beschreibung der Rückgabewerte |
|
-1 |
Der Mischauftrag wurde durch den Benutzer abgebrochen. Ursache: In der Prozentanzeige wurde der "Abbrechen"-Button betätigt bzw. die ESC-Taste ausgelöst. |
|
0 |
Alles in Ordnung |
|
801 |
ungültige Parameterkennung Parameter ohne Parameterkennung keine Eingabedatei für Dokument angegeben Syntax: -wHWND;WINID komprimierte Ausgabe nur mit Dateien möglich (nicht mit Standardein- und -ausgabe) |
|
802 |
Datei ist fehlerhaft |
|
803 |
Datei nicht gefunden Datei existiert bereits Datei wird benutzt von einem anderen Prozess Lese-Zugriff auf Datei nicht erlaubt Schreib-Zugriff auf Datei nicht erlaubt FD/HD-Speicher ist voll Zugriff auf Datei nicht erlaubt
Hat mit Dateizugriffen zu tun: Erfahrungswerte aus dem Support: 1)
Auf
ausdrücklichen Wunsch schreibt Merge schon noch eine temporäre Datei. Es ist
per Patch oder per Environment ein nicht vorhandenes TEMP Verzeichnis
gesetzt.
|
|
804 |
Datei nicht gefunden Syntaxfehler bei der Bestimmung einer Datenquelle Datei ist nicht positionierbar Datei ist Standard-Ein-/Ausgabegerät kein Dateiname angegeben |
|
805 |
Meldung des Parsers für Zeit-Werte ... Meldung des Scanners/Parsers für Ausdrucksfeld ... kein Datenbankzugriffsobjekt angelegt |
|
807 |
Parameter existiert nicht mehr Parameter verloren |
|
808 |
fehlerhaftes RTF-Format falsche Kontrollworte |
|
809 |
Dokument ist leer |
|
810 |
Textmarke des Ausdrucks nicht gefunden Aliasname nicht gefunden Syntaxfehler: ... Division durch 0 0 hoch 0 negative Basis hoch nicht ganzzahligen Exponenten Falsche Anzahl von Parametern Unbekannte Feldanweisung unbekannter Vergleichsoperator in Bedingung ungültige Informationskennung Wert hinter Info ist nicht korrekt unbekannter Schalter keine Steuerdatei unbekannte Variable Syntaxfehler: " gefehlt {.. " ..} |
|
811 |
keine Verbindung zur Datenbank SQL-Anweisung nicht korrekt ausgeführt nicht fehlerfrei von der Datenbank getrennt Fehler vom Datenbankzugriffsobjekt konnte Zeilennummer nicht feststellen Aliasnamen mehrfach vorhanden konnte nicht auf die erste Zeile stellen |
|
812 |
Zeit wurde falsch berechnet Wochentag wurde falsch berechnet Monat wurde falsch berechnet Accessoren inkompatibel ungültiger Index Illegaler Index Illegaler Status zu wenig Felder im Datensatz zu viele Felder im Datensatz ungültiges Trennzeichen Meldung des Parsers für Zeit-Werte ... Meldung des Scanners/Parsers für Ausdrucksfeld ... ungültige Informationskennung ungültiger Feldbefehl Advance außerhalb der Grenzen unerwartetes Listenende Ringpuffer zu klein Suchbaum für RTF Token ist defekt Read wurde ohne vorherige endOfMem-Prüfung aufgerufen Block zu gross "default:" erreicht ungültige Quell-CodePage ungültige Ziel-CodePage itoa mit base!=10 aufgerufen! Dokumentvariablen nicht bekannt |
|
813 |
im aktuellen Kontext ungütige Werte/Daten |
|
814 |
Abbruch durch Benutzer |
|
815 |
CIB merge stößt auf eine nicht implementierte Feldanweisung / Feldschalter (z.B. Tippfehler bei Schalter in REF feldern \* xxxxx ) |
|
817 |
Funktion noch nicht implementiert |
|
818 |
Zulässige Gesamtgrösse überschritten |
|
819 |
Endlosinclusion erkannt |
|
820 |
Fehler im Recombine |
|
821 |
Maximale Ausführungszeit überschritten |
12.3. Fehlerprotokolldatei
AllgemeinDiagnoselevel
Fehlerkategorien
Fehlerprotokolldatei bis CIB merge 3.8.x
Allgemein
Mit dem Parameter -L(!)<Fehlerprotokolldatei> schreibt CIB merge eine Beschreibung der Fehlermeldung in die angegebene Logdatei. Tritt kein Fehler auf, so wird eine leere Datei geschrieben. Siehe auch Kapitel -L<Logdatei>.
Fehlerprotokolldatei mit --verbose ab CIB merge 3.9.x
CIB merge schreibt ab version 3.9.x eine nach Fehlerkategorien und Diagnoseleveln frei skalierbare Fehlerprotokolldatei, die somit individuell auf die Bedürfnisse der User zugeschnitten werden kann.
Diagnoselevel
Die Diagnoselevel bezeichnen dabei die Detailtiefe der Protokolldatei wie folgt:
|
level |
verbosity |
name |
standards |
function |
remarks |
|
0 |
nothing |
silent/still/stumm |
|
quiet |
|
|
1 |
severe errors |
severe/schwer(wiegend) |
|
errors |
|
|
2 |
all errors |
error(s)/Fehler |
|
|
|
|
3 |
important consequences |
initial |
initial |
|
|
|
4 |
helpful consequences |
""/default/standard |
default |
|
|
|
5 |
all consequences |
stack |
|
|
|
|
6 |
helpful information |
info(rmation) |
|
trace |
|
|
7 |
technical information |
technical/technisch |
|
|
|
|
8 |
timing information |
timing/Zeit(en) |
|
|
reserved |
|
9 |
memory information |
memory/Speicher |
|
|
reserved |
Wird --verbose nicht gesetzt, so wird der initial Level 3 gesetzt. Wird --verbose ohne einen Diagnoselevel gesetzt, so gilt der default Level 4.
Fehlerkategorien
CIB merge unterscheidet zur Protokollierung mit --verbose verschiedene Fehlerkategorien:
ALL/ALLE, DATA/DATEN, DIALOG, DOC/DOCUMENT/DOK/DOKUMENT, INCLUDE/EINFUEGEN, FIELD/FELD, FILE/DATEI, PAR, REF, SOURCE/QUELLE, SOURCEPATH/QUELLPFAD
Diese können beliebig kombiniert werden, z.B. --verbose +DATA +DOK +INCLUDE oder --verbose +ALL -SOURCE
Fehlerprotokolldatei bis CIB merge 3.8.x
Die Fehlerprotokolldatei und enthält Informationen für Anwendungsentwickler, Rohtextentwickler und den CIB Support. Eine Skalierung mit --verbose ist nicht möglich, die Datei ist wie folgt aufgebaut:
Die erste Zeile gibt die Fehlerart und Kategorie an.
Die zweite Zeile beschreibt, in welcher Datei der Fehler passiert ist. CIB merge Versionen < 3.8.108 geben in der zweiten Zeile Informationen für den CIB Support aus.
In den weiteren Zeilen erhält der Anwender die nötigen Hinweise für die Verfolgung der Fehlerursachen.
Die letzte Zeile der Fehlermeldungen enthält die folgenden Angaben:
Programmrückgabewert: xxxx - siehe Kapitel Programmrückgabewerte "==>" bezeichnet immer die Folgen in CIB merge.
Hinweise zur Analyse der Fehlerprotokolldatei
Feldanweisungen werden grundsätzlich von innen nach außen ausgewertet, CIB merge listet daher zuerst den "innersten" Fehler und anschließend die daraus folgenden Fehler in den äußeren Feldern aus.
BeispielEine Variable wird in einer WENN-Bedingung mit einem festen Wert verglichen. Der Baustein ist Teil eines größeren Projekts und wird mit EINFÜGENTEXT in das Wurzeldokument eingefügt. Fehlt nun die Variable in der Datenversorgung, so wird CIB merge folgendes ausgeben:
FEHLER: Fehlbedienung: Fehlerhafte Feldanweisung
Fehler während der Datei baustein.rtf
unbekannte Variable
Name: dummy_feld
==> konnte Feldanweisung nicht auswerten
Befehl: REF
Parameter: 2 Stück
1: REF
2: dummy_feld
Schalter: 0 Stück
==> Feld nicht neu berechnet
==> linken Operanden nicht ausgewertet
==> Bedingung nicht ausgewertet
==> konnte Feldanweisung nicht auswerten
Befehl: WENN
Parameter: 6 Stück
1: WENN
2: {REF dummy_feld}
3: <>
4: ""
5: "REF dummyfeld ist nicht leer"
6: "REF Dummyfeld ist leer"
Schalter: 0 Stück
==> Feldergebnis nicht neu berechnet und geschrieben
==> Feld nicht korrekt ausgewertet und geschrieben
==> Dokument nicht vollständig bearbeitet und geschrieben
==> Datensatz-Nr.: 1
==> konnte Feldanweisung nicht auswerten
Befehl: EINFÜGENTEXT
Parameter: 2 Stück
1: EINFÜGENTEXT
2: "baustein.rtf"
Schalter: 0 Stück
==> Feldergebnis nicht neu berechnet und geschrieben
==> Feld nicht korrekt ausgewertet und geschrieben
==> Einzeldokument nicht vollständig bearbeitet und geschrieben
==> Mischvorgang abgebrochen
==> Dokument nicht vollständig bearbeitet und geschrieben
==> Datensatz-Nr.: 1
==> Dokument nicht korrekt bearbeitet
Programmrückgabewert 0010
12.4. Tracemöglichkeiten
Durch optionales Setzen von Umgebungsvariablen in Ihrer Systemumgebung können Sie auf Bedarf einen Tracelauf mit unseren Komponenten durchführen. Hierbei werden entsprechende Logdateien im gewünschten Verzeichnis erzeugt, die für unseren Support sehr hilfreich sein können.
Tracedatei mit Umgebungsvariablen setzen:
Die Tracedatei wird hier jeweils gelöscht und neu geschrieben, wenn CIB merge neu angezogen wird. Für Serveranwendungen empfiehlt sich daher das weiter unten beschriebene Patchen der CIB merge dll.
Für die Traceausgabe setzen Sie bitte die Umgebungsvariable:
CIB_MRGTRACE = <Verzeichnis + Dateiname> (z.B. CIB_MRGTRACE=c:\temp\mrg.log)
Hinweis:
Bei älteren CIB merge-Versionen (bis 3.7.64) heißt die Umgebungsvariable
CIB_TRACE.
CIB_TRACE = <Verzeichnis + Dateiname> (z.B. CIB_TRACE=c:\temp\mrg.log)
Setzen Sie im Zweifelsfall einfach beide Umgebungsvariablen.
Tracedatei direkt in der dll patchen:
Sie können die Trace-Ausgabe auch direkt in der CIB merge dll patchen, dies ist besonders für Server-Anwendungen interessant, in denen CIB merge immer angezogen bleibt und die Tracedatei sonst immer weiter wachsen würde. Ist die Trace-Ausgabe per Patch gesetzt, so wird die Tracedatei nach jedem fehlerfreien Mischauftrag gelöscht.
Öffnen Sie dazu die Datei mit einem Hexeditor und suchen Sie nach " EXTERN_CIB_TRACE". Beginnen Sie ein Zeichen vor "EXTERN_CIB_TRACE" und geben Sie im Überschreiben-Modus Pfad und Namen der Tracedatei ein, z.b. c:\temp\cibmrgtrace.txt. Dieses Feature ist aber der CIB merge Version 3.7.84d verfügbar.
12.5. Lieferumfang
CIB merge, wird als Binärmodul in Form von DLLs oder shared libraries (Unix) ausgeliefert.
|
Komponente |
Softwareumfang |
|
CIB merge |
WIN32 |
|
|
|
WIN64 |
|
|
|
|
UNIX |
|
|
|
|
XML-Zugriffe |
WIN32 |
|
|
|
WIN64 |
|
|
|
|
UNIX |
|
|
|
|
(optional) |
WIN32 |
|
|
|
WIN64 |
|
|
|
|
UNIX |
|
|
|
|
CIB runshell |
WIN32 |
|
|
|
WIN64 |
|
|
|
|
UNIX |
|
|
Zusätzlich werden die für die C(++) Programmierung erforderlichen Header- und Library Dateien und eine ausführliche Versionshistorie mitgeliefert.