CIB merge technical documentation (EN)
| Site: | CIB eLearning |
| Course: | CIB merge |
| Book: | CIB merge technical documentation (EN) |
| Printed by: | Guest user |
| Date: | Thursday, 18 June 2026, 12:06 PM |
Table of contents
- 1. Introduction
- 2. Installation
- 3. CIB merge as a document interpreter
- 4. Data supply
- 5. Technical interfaces
- 6. Call parameters in detail
- 6.1. General notes
- 6.2. Note Calling examples
- 6.3. Overview about the abbreviations for call parameters
- 6.4. Parameter --analyse
- 6.5. Parameter --break
- 6.6. Parameter --charformat
- 6.7. Parameter --chart-…
- 6.8. Parameter --codepage
- 6.9. Parameter --colors
- 6.10. Parameter --compress
- 6.11. Parameter --datafile
- 6.12. Parameter --default-mode
- 6.13. Parameter --default-prefix
- 6.14. Parameter --delimiter
- 6.15. Parameter --destination-colorschememapping
- 6.16. Parameter --destination-datastore
- 6.17. Parameter --destination-themedata
- 6.18. Parameter --dialog
- 6.19. Parameter --directory-…
- 6.20. Parameter --directory-set-inline
- 6.21. Parameter --directory-log
- 6.22. Parameter --directory-read
- 6.23. Parameter --directory-remove
- 6.24. Parameter --directory-set
- 6.25. Parameter --directory-write
- 6.26. Parameter --docproperty
- 6.27. Parameter --encrypt
- 6.28. Parameter --field-nesting-level-limit
- 6.29. Parameter --field-results
- 6.30. Parameter --filter
- 6.31. Parameter --fonts
- 6.32. Parameter --headerfile
- 6.33. Parameter --help
- 6.34. Parameter --inline-is-not-this
- 6.35. Parameter --html-switches
- 6.36. Parameter --inputfile
- 6.37. Parameter --input-language
- 6.38. Parameter --intermediatefile
- 6.39. Parameter --keep-fields
- 6.40. Parameter --keep-refs-if-in-list
- 6.41. Parameter --LicenseCompany
- 6.42. Parameter --LicenseKey
- 6.43. Parameter --lists
- 6.44. Parameter --logfile
- 6.45. Parameter -m
- 6.46. Parameter -- max-executiontime
- 6.47. Parameter --maxOutputSize
- 6.48. Parameter --maxSingleSize
- 6.49. Parameter --merge
- 6.50. Parameter --multidatafile
- 6.51. Parameter --next-mode
- 6.52. Parameter --old-compare
- 6.53. Parameter --optimize
- 6.54. Parameter --outputfile
- 6.55. Parameter --output-language
- 6.56. Parameter --parameterfile
- 6.57. Parameter --prefix-delimiter
- 6.58. Parameter --remove-hidden-text
- 6.59. Parameter --replace-color
- 6.60. Parameter --replace-header
- 6.61. Parameter --serialletter
- 6.62. Parameter --set
- 6.63. Parameter --short-tokens
- 6.64. Parameter --source-directory
- 6.65. Parameter --statistics
- 6.66. Parameter --target-directory
- 6.67. Parameter --template-combine
- 6.68. Parameter --verbose
- 6.69. Parameter --version
- 6.70. Parameter --window-handle
- 6.71. Parameter --workingset-size
- 7. Special funcionality: Textcaching
- 8. Special funcionality: Result optimization, encryption and compression
- 9. Special funcionality: Mixing document properties
- 10. Use case examples
- 11. Quick start
- 12. Annex
1. Introduction
CIB merge is a central component from the document construction kit of the CIB office modules. With CIB merge, the user is provided with a tool with which he can interpret document modules (=templates), which can also contain field instructions (=commands), and mix them with variable data to form a target document. CIB merge supports the RTF format of Microsoft as document format. The variable data can be merged from one or more CSV files, XML files or from database(s). It is also possible to add your own UserExit functions to CIB merge.
This documentation gives a quick overview of the possible use.
2. Installation
Windows 32/64-Bit
For active use of the RTF text interpreter, the respective CIB merge program version has to be accessible.
Unix in general
Because of multiple libs archives, the installation instructions are available for various Unix derivatives.
Systems
CIB merge runs on Windows 32- and 64-bit.
CIB merge is available for the following platforms:
- Solaris Sparc (32/64)
- Solaris x86 (32/64)
- AIX-ppc (32/64)
- Linux-x86 (32/64)
Further platforms on request.
Additional modules
According to the well-proven modular principle of the CIB office modules (=CoMod), there are also additional components around CIB merge, which can either facilitate the technical integration into the developer's preferred architecture or which can sensibly supplement the functional range of the CIB merge module.
All additional products are documented in detail in separate technical guides. You can request this information from CIB Support.
CIB chartWith the CIB chart module there is an optional supplement for the CIB merge, which makes it possible to generate various dynamic diagrams from the same data supply and store them as graphics in the result document
.
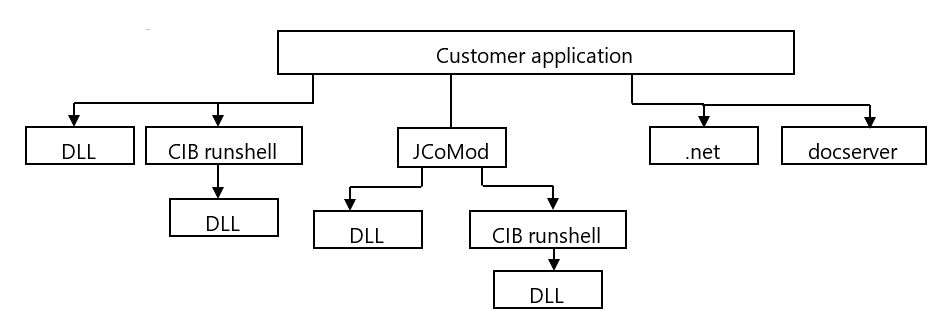
The CIB runshell is a command line tool that can be used to control all CIB products delivered as DLLs or shared libraries. With the CIB runshell it is possible to set all call parameters ("properties") that each individual CIB office module makes available to the user.
It is also ideally suited for use within (batch) jobs and for designing your own processes (instances) with the modules. A Java encapsulation is also available for the CIB runshell.
.
JCoMod WrapperWith the JCoMod Wrapper you get a complete JAVA/JNI encapsulation, which allows an easy control of CIB merge from JAVA. The corresponding JAVA/JNI interfaces also operate the CIB runshell, so that the CIB components can also be started in your own processes within the JAVA VM.
CoMod.netCIB documentServer/J2EE
The CIB documentServer serves to optimize the use of the CIB office modules (CoMod), especially when used on servers (document and print services). With the J2EE standard package of the CIB documentServer, a fast realization - even of complex document requirements - is possible in the respective customer system.
Calling and using the CIB documentServer releases the developers of the calling application from the details of the respective technical connection of the CIB docgen modules:
The call for document generation is made by means of a standardized job description in XML format, in which the input, outputs, options and even data for CIB merge are formally specified.
In addition, a framework of Java classes is available to the application developer for easier integration.
CIB workbench
CIB pdf toolbox
The CIB pdf toolbox is an interpreter for PDF files comparable to the CIB merge. It offers multiple processing possibilities for PDF and supplied data streams. It is also possible to process additional PDF templates into a target document in existing RTF document projects.
For more information please have a look at the CIB pdf toolbox technical guide.
3. CIB merge as a document interpreter
CIB merge is a universal interpreter for the dynamic processing of documents with field commands, external data supply via CSV or XML files, SQL accesses and own user exits.
RTF is supported as document input format.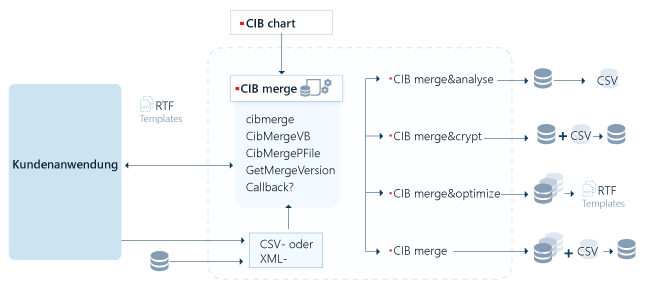
The user has access to the entire functional range of the CIB merge via the call interface.
The CIB merge functionality can be divided into "task areas". However, most of these can also be used simultaneously via a single call.3.1. CIB merge
With CIB merge it is possible:
- to merge data from external XML and CSV data sources into RTF. Variable fields contained in the RTF document are addressed by their unique name and filled with the specified content. The possibility of processing data records supports both the single letter and serial letter functionality.
- to execute SQL queries directly from documents.
- to control documents from user side.
3.2. CIB merge&optimize
The document base (=templates) is created using text systems (usually MS Office, Open Office) of different versions that are widely used on the market. Accordingly, the individual modules are partly enriched with various very redundant information.
CIB merge & optimize makes it possible, when providing the modules (="Deploy templates") into the application environment, to streamline them accordingly without changing their formatting or content.3.3. CIB merge&crypt
Often there is a requirement to store the document base (=templates) in a protected manner in an application and also to protect any interim results from a mixed run against "misuse". CIB merge has corresponding call options that enable packing and/or encryption.3.4. CIB merge&analyse
With its own environment "report & analyse", CIB offers the possibility to create your own reporting from document projects. The CIB merge component provides valuable services in this analysis environment, both for evaluating the contents of the analysis project modules and for generating the actual output report.
3.5. Supported field commands
GeneralOverview of basic field commands
Supported text functions
Supported date functions
Rules for processing text and date functions
General
MS-Office provides about 85 different field commands that can be used to program dynamic documents. All commands that are not directly related to the formatting of text are evaluated and supported by the CIB merge component during a merge process.
The interpretation of the remaining field commands that are important for the layout/print display (e.g. (total) page numbering, print date, signature fields, etc.) is reserved for the CIB format/output component. CIB merge passes these field commands unfiltered in the result document.
From CIB merge version
3.13.7:
The same behavior applies to a calculation expression that contains references
to table elements: The expression is passed to the result document unfiltered.
Overview of basic field commands
The following field commands of a document are interpreted directly by the CIB merge component during a merge process and dynamically converted into the output file (the field commands here are only listed alphabetically and not described with their full syntax):
|
Field command |
Description |
|
COMPARE |
Compares two values and returns the numeric value 1 if the comparison is true and 0 (zero) if the comparison is false. |
|
DATA |
|
|
DATE |
Inserts the current date. |
|
IF |
Compares arguments under certain conditions. Can be extended optionally to a loop instruction. |
|
INCLUDEPICTURE |
Inserts a graphic from a file. Is only executed by CIB merge in conjunction with the call parameter --EMBED. Otherwise the interpretation is only carried out by CIB format/output. |
|
INCLUDEPICTURE "?graphic file" (from CIB merge Version 3.9.174) |
Returns 0 if the file does not exist, otherwise 1. |
|
INCLUDETEXT |
Inserts a text from a file. "Please note in this context the possible field switch NEWLISTID" |
|
INCLUDETEXT "?text file" |
Returns 0 if the file does not exist, otherwise 1. |
|
INFO |
Inserts information from the Properties dialog box. |
|
MERGEFIELD |
Defines a placeholder with a name that will be replaced by a delivered variable content later. |
|
MERGEREC <Alias-Name> |
Inserts the number that the current record has in the input file (or table) <alias name>. |
|
MERGEREC ?<Alias-Name> |
Returns 0 if there are no more datasets in the file (or table) <alias name>. |
|
MERGEREC #<Alias-Name> (from CIB merge version 3.12.1) |
Returns the exact number of datasets in the file (or table) <alias name>. Attention: This function can be resource-intensive with CSV data sources! |
|
MERGEREC ##<Alias-Name> (from CIB merge version 3.12.1) |
Returns status information about the number of datasets in the file (or table) <alias name>. Values: 1 one dataset 2 two or more datasets Attention: This function has no negative effect on the resources of CSV data sources. |
|
NEXT |
Moves to the next dataset or node in the data supply. |
|
NEXTIF |
Moves to the next dataset or node in the data supply when a certain condition is met. |
|
QUOTE |
Inserts text into the document. |
|
REF |
Defines a placeholder with a name that will be replaced by a delivered variable content later. |
|
REF "?variable" (from CIB merge version 3.9.191) |
Returns 0 if the variable does not exist, otherwise 1. |
|
TO DO: REF DAT |
|
|
TO DO: NEXT DEF |
|
|
SET |
Assigns new text to a bookmark. |
|
SKIPIF |
Skips a dataset or node in the data supply during a mail merge according to a condition. Usage with alias names is not possible! |
|
TIME |
Inserts the current time. |
|
= Expression |
Calculates the result of an expression (= formulas). CIB merge supports very extensive functions, even in complicated formulas. From CIB merge version 3.11.0 the text functions described in the following chapter are supported. |
Some of these field commands allow an extension of their functionality with additional switches.
For example, loop instructions can be used to create dynamic tables of any length. It is also possible to insert text modules dynamically.
Supported text functions
From CIB merge version 3.12.0 the text
functions described in the following chapter are supported.
Notes:
- The possibility for linked (multiple) processing of text functions is described here.
- Fixed texts (strings) can be used as parameters of a text function. The content of a string must be specified in quotation marks. The string itself must not contain quotation marks.
|
Text function (syntax) |
Description |
|
TRIM(text) |
Deletes spaces in a text that are not individually between words and thus serve as separators. You can use TRIM for texts that you have copied from other application programs and that may contain unwanted spaces. Parameters: text (type text, required) The text, from which the spaces should be removed. Example: =Trim( " abc " ) results in abc |
|
LEN(text) |
Returns the number of characters in a string. Parameters: text (type text, required) The text from which you want to find out its length. Blank spaces count as characters. Example: = LEN( "ab abc" ) results in 6 |
|
FIND(find_text;within_text; start_num) |
FIND searches for a character string within another and returns the position of the searched character string from the first character of the other character string. Parameters: find_text (type text, required) Sets the text to search. within_text (type text, required) Sets the text, in which you search with find_text. start_num (type number, required) Specifies the character to begin the search with. The first character corresponding to find_text has the number one 1. Example: =FIND( "b"; "abc", 1 ) results in 2 Notes: |
|
SEARCH(find_text; within_text; start_num) |
SEARCH searches for a character string within another character string and returns as result the number of the starting position of the first character string, counted from the first character of the second character string. Parameters: find_text (type text, required) is the text you want to search for. A string specified as find_text can contain the placeholder characters question mark (?) and asterisk (*). A question mark replaces one character, an asterisk replaces any character string. If you search for a question mark or an asterisk, you must enter two backslashes (\\) before the character you want to search for. within_text (type text, required) is the text in which to search for find_text. start_num (type number, required) Specifies the character at which the search should start. The first character belonging to find_text has the number 1. Example:
=SEARCH(
"b"; "ABC", 1 ) results in 2 Notes: |
|
MID(text; start_num; num_chars) |
The MID function returns a certain number of related characters from a given string. Parameters: text (type text, required) Text, to return characters from. start_num(type number, required) Character position in text, where the part to be extracted begins. num_chars(type number, required) Returns the number of characters that MID should return from text. Example: =MID( "abc"; 2; 1 ) results in b Notes:
|
|
SUBSTITUTE(text; old_text; new_text; instance_num) |
Replaces old with new text in a string. You can use SUBSTITUTE whenever you want to replace a specific character string within a text. You should always use REPLACE if you want to replace a character string starting at a specific position within a text. Parameters: text (type text, required) is the text with the characters to be replaced. old_text (type text, required) is the text to be replaced. new_text (type text, required) is the text to be replaced with old_text. instance_num (type number, required) Specifies how often old_text should be replaced with new_text. If you specify instance_num, only this occurrence of old_text will be replaced; otherwise, old_text will be replaced by new_text wherever it occurs in. Example: =SUBSTITUTE( "abcbcbcd"; "bc"; "d"; 2 ) results in addbcd |
|
REPLACE(old_text; start_num; num_chars; new_text) |
REPLACE replaces a character string of the specified length in the text from the specified position onwards with another character string. Parameters: old_text (type text, required) is the text, in which you want to replace an amount of characters. start_num (type number, required) The position of the character in old_text where to start replacing with new_text. num_chars (type number, required) The amount of characters in old_text, that REPLACE replaces with new_text. new_text (type text, required) The text with which you want to replace characters in old_text. Example: =REPLACE( "abcd"; 2; 2; "d" ) results in add |
|
LOWER(text) |
Converts a text to lower case. Parameters: text (type text, required) The text to convert in lower case. Example: =LOWER( "ABC9" ) results in abc9 Note:
|
|
UPPER(text) |
Converts a text to upper case. Parameters: text (type text, required) The text to convert in upper case. Example: = UPPER( "abc9" ) results in ABC9 Note:
|
|
LEFT(text; num_chars) |
Cuts the specified number of characters starting from the left. Parameters: text (type text, required) The text string with the characters to be cut. num_chars (type number, required) Amount of characters to be returned. Example: =LEFT( "abc"; 2 ) results in ab Notes:
|
|
RIGHT(text; num_chars) |
Cuts the specified number of characters starting from the right. Parameters: text (type text, required) The text string with characters to cut. num_chars (type number, required) Amount of characters to be returned. Example: =RIGHT( "abc"; 2 ) results in bc Notes:
|
|
REPT(text; number_times) |
Repeats a text as often as specified. You can use REPT to repeat a text with a certain frequency. Parameters: text (type text, required) The text to be repeated. number_times (type number, required) A positive number indicating the number of repetitions Example: =REPT( "abc"; 2 ) results in abcabc Notes:
|
|
TOKENIZE(text; delimiters; tokenIdx) |
Splits a text into individual text parts using the specified separators and returns the part specified with tokenIdx (e.g. with tokenIdx = 3, the third part). Parameters: text (type text, required) The text to separate. delimiters (type text, required) List of delimiters. If using a comma as separator, it needs to be masked with a backslash (\). tokenIdx (Type number, required) Number of the text part to be returned. If the index is negative, counting starts from the end of the text Examples: =TOKENIZE( "a b c-d"; " -"; 4 ) results
in d Notes:
|
|
BEFORE(text; before_text) |
Returns the characters of text that precede the first occurrence of before_text in text, or returns an empty string if before_text is not included in text. Parameters: text (type text, required) Is the text from which the string is to be taken. before_text (type text, required) The text to be searched for, which marks the end of the character string to be extracted. Example: =BEFORE( "abcdefg"; "cd" ) results in ab Notes:
|
|
AFTER(text; after_text) |
Returns the characters of text that follow the first occurrence of after_text in text, or returns an empty string if after_text is not included in text. Parameters: text (type text, required) Is the text from which the string is to be taken after_text (type text, required) The text to be searched, which marks the beginning of the character string to be extracted. Example: =AFTER( "abcdefg"; "cd" ) returns in efg Notes:
|
|
FORMAT(text; format) |
Returns text in the format format. This function works similar to formatting numbers. Parameters: text (type text, required) Is the text to format. format (type text, required) Defines the format. (Details see below) Valid characters to specify the format: x Placeholder characters for one character of the specified text. Adding spaces and separators: Space will be displayed exactly as entered / will be displayed exactly as entered ( will be displayed exactly as entered ) will be displayed exactly as entered . will be displayed exactly as entered - will be displayed exactly as entered Examples: =Format(„abcdefghi“;“xxx
xxx xxx“) results in „abc def ghi“ Note:
|
Supported date functions
From version 3.12.12 CIB merge supports the date functions described below.
The date functions are defined analogous to
calculation or text functions in the form
{ =DATUMSFUNKTION }
{ =DATE FUNCTION }
into the document.
A requirement for these functions is that the date used as input (or a variable "date") has a valid date value and is formatted in a valid date format.
|
Date function (syntax) |
Description |
|
ADDDAYS(Date,AmountDays) \@ Format Return: Date |
Add days: Parameters: Date See requirement above AmountDays Integer Format Has to be a valid syntax for date formatting
|
|
ADDDAYS_VD(VDatum,AnzTage) \@ Format Rückgabe: Datum |
Tage addieren mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
ADDMONTHS(Date,AmountMonth) \@ Format Return: Date |
Add month: Parameters: Date See requirements above AmountMonth Integer Format Has to be a valid syntax for date formatting
|
|
ADDMONTHS_VD(VDatum,AnzMonate) \@ Format Rückgabe: Datum |
Monate addieren mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
ADDYEARS(Date,AmountYears) \@ Format Return: Date |
Add years: Parameters: Date See requirements above AmountYears Integer Format Has to be a valid syntax for date formatting
|
|
ADDYEARS_VD(VDatum,AnzJahre) \@ Format Rückgabe: Datum |
Jahre addieren mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
ADDWORKINGDAYS(Date,AmountDays, \@ Format Return: Date |
Add working days: Parameters: Date See requirements above AmoutDays Amount of days, integer Holidays Optionally, a list of public holidays can be specified, which are taken into account in the calculation. Syntax: dd.MM. Data separated by ";". WorkingDays Working days per week.
Values between 2 and 7, default is 5. Format Needs to have a valid syntax for date formatting Example: |
|
ADDWORKINGDAYS_VD(VDatum,AnzTage, \@ Format Rückgabe: Datum |
Werktage addieren mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
GETNEXTWORKINGDAY(Date,Holidays,WorkingDays) \@ Format Return: Date |
Next working day from date: Based on the value of the variable varDate, the next working day is determined taking the days off into account and output in the desired format. Parameters: Date See requirements above. Holidays Optionally, a list of public holidays can be specified, which are taken into account in the calculation. Syntax: dd.MM. Data separated by ";". WorkingDays Working days per week.
Values between 2 and 7, default is 5. Format Needs to have a valid syntax for date formatting Example: |
|
SUBTRACTDAYS(Date,AmountDays) \@ Format Return: Date |
Subtract days: A certain number of days is subtracted from the value of the Date variable and displayed in the desired format. Parameters: Date See requirement above AmountDays Integer Format Has to be a valid syntax for date formatting
|
|
SUBTRACTDAYS_VD(VDatum,AnzTage) \@ Format Rückgabe: Datum |
Tage subtrahieren mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
SUBTRACTMONTHS(Date,AmountMonth) \@ Format Return: Date |
Subtract months: A certain number of months is subtracted from the value of the variable Date and displayed in the desired format. Parameters: Date See requirement above AmountMonth Integer Format Has to be a valid syntax for date formatting
|
|
SUBTRACTMONTHS_VD(VDatum,AnzMonate) \@ Format Rückgabe: Datum |
Monate subtrahieren mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
SUBTRACTYEARS(Date,AmountYears) \@ Format Return: Date |
Subtract years: A certain number of years is subtracted from the value of the variable Date and output in the desired format. Parameters: Date See requirement above AmountYears Integer Format Has to be a valid syntax for date formatting
|
|
SUBTRACTYEARS_VD(VDatum,AnzJahre) \@ Format Rückgabe: Datum |
Jahre subtrahieren mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
SUBTRACTWORKINGDAYS(Date,AmountDays,Holidays,WorkingDays) \@ Format Return: Date |
Subtract working days: A certain number of working days is subtracted from the value of the variable varDate and displayed in the desired format. Parameters: Date See requirements above AmountDays Amount of working days, integer Holidays Optionally, a list of public holidays can be specified, which are taken into account in the calculation. Syntax: dd.MM. Data separated by ";". Optionally, a list of public holidays can be specified, which are taken into account in the calculation. Syntax: dd.MM. Data separated by ";". WorkingDays Working days per
week. Value between 2 and 7, default is 5. Format Has to be a valid syntax for date formatting Example: |
|
DATEDIF(Date1,Date2,Unit) Return: Integer |
Calculate date difference: The difference between the date values Date1 and Date2 is calculated. The time unit is controlled by the Unit parameter. Parameters: Date1 Unit Possible values: Y Difference in completed years M Difference in completed months D Difference in days MD Difference between the days (in days, ignoring month and year specification) YM Difference between the months (in months, ignoring day and year specification) YD Difference between days and months (in days, ignoring year specification)
|
|
DATEDIF_VD(VDatum1,VDatum2,Einheit) Rückgabe: Ganzzahl |
Datumsdifferenz berechnen mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
GETDAYDIFF(Date1,Date2) Return: Integer |
Calculate difference in days: The difference between the date values Date1 and Date2 is calculated in days. Parameters: Date1 |
|
GETDAYDIFF_VD(VDatum1,VDatum2) Rückgabe: Ganzzahl |
Differenz in Tagen berechnen mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
GETMONTHDIFF(Date1,Date2) Return: Integer |
Calculate difference in months: The difference between the date values Date1 and Date2 is calculated in months. Parameters: Date1 |
|
GETMONTHDIFF_VD(VDatum1,VDatum2) Rückgabe: Ganzzahl |
Differenz in Monaten berechnen mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
GETYEARDIFF(Date1,Date2) Return: Integer |
Calculate difference in years: The difference between the date values Date1 and Date2 is calculated in years. Parameters: Date1 |
|
GETYEARDIFF_VD(VDatum1,VDatum2) Rückgabe: Ganzzahl |
Differenz in Jahren berechnen mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
GETFIRSTOFMONTH(Date) \@ Format Return: Date |
First day of the month: The first day of the month of a given date is output in the desired format. Parameter: Date See requirements above Format Has to be a valid syntax for date formatting Example: |
|
GETFIRSTOFMONTH_VD(VDatum) \@ Format Rückgabe: Datum |
Erster Tag im Monat berechnen mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
GETFIRSTOFNEXTMONTH(Date) \@ Format Return: Date |
First day of next month: The first day of the next month of a given date is output in the desired format. Parameters: Date See requirements above Format Has to be a valid syntax for date formatting Example: |
|
GETFIRSTOFNEXTMONTH_VD(VDatum) \@ Format Rückgabe: Datum |
Erster Tag des nächsten Monats berechnen mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
GETFIRSTOFQUARTER(Date) \@ Format Return: Date |
First day of the quarter: The first day of the quarter of a given date is output in the desired format. Parameters: Date See requirements above Format Has to be a valid syntax for date formatting Example: |
|
GETFIRSTOFQUARTER_VD(VDatum) \@ Format Rückgabe: Datum |
Erster Tag des Quartals berechnen mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
GETLASTOFMONTH(Date) \@ Format Return: Date |
Last day of the month: The last day of the month of a given date is output in the desired format. Parameters: Date See requirements above Format Has to be a valid syntax for date formatting Example: |
|
GETLASTOFMONTH_VD(VDatum) \@ Format Rückgabe: Datum |
Letzter Tag des Monats berechnen mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
GETLASTOFLASTMONTH(Date) \@ Format Return: Date |
Last day of last month: The last day of the previous month of a specified date is output in the desired format. Parameters: Date See requirements above Format Has to be a valid syntax for date formatting Example: |
|
GETLASTOFLASTMONTH_VD(VDatum) \@ Format Rückgabe: Datum |
Letzter Tag des letzten Monats berechnen mit Valutadatum: Datumsvariablen vom Typ Valutadatum werden immer mit 30 Tagen
im Monat berechnet. Beispiel: |
|
GETLASTOFQUARTER(Date) \@ Format Return: Date |
Last day of the quarter: The last day of the quarter of a specified date is output in the desired format. Parameters: Date See requirements above Format Has to be a valid syntax for date formatting Example: |
Rules for processing text and date functions
Processing variables from the data supplyWithin a text or date function the name of a variable from the data supply can be used to process the content of this variable.
Example1:
{ SET myVar " My content from the data supply " }
{= LEFT(myVar; 4) }
Result: My
The content of the variable myVar may contain any characters, including special
characters such as quotation marks, semicolons, commas, brackets, etc.
Example2:
To be able to correctly process special characters that would otherwise be interpreted by RTF processing, the following procedure is recommended:
{ SET COMMA "," }
{ = SUBSTITUTE("123.45"; "."; COMMA; "1") }
Result: 123,45
The special character is assigned to a variable by the SET command, which can then be used in the SUBSTITUTE command.
Example3:
{ SET myDate "15.02.2015" }
{= ADDDAYS(myDate, 14)\@ "tt.MM.jjjj }Result: 01.03.2015
To process text or date functions concatenated, i.e. to continue working within a text/date function with the result of another text/date function, the detour via variables is necessary.
Example:
{SET a " abc "}
{SET b { = TRIM (a)} }
{ = LEFT(b;2)}
Result: ab
Here b is first assigned the value abc (the blanks are removed by the TRIM
function). Then b is passed to the LEFT function.
3.6. Handling of field switches
The various field switches that can be used in the RTF and are evaluated by the CIB merge are explained in detail in the RTF training documents:
Dynamische Dokumente - Band 1 - Grundlagen.pdf
They are mentioned in this guide only insofar as they are relevant for the treatment of some parameters, e.g. \* CHARFORMAT.
3.7. Additional functionality of interest
CIB merge offers - in direct connection with further CIB components - useful additional functionalities for dynamic document generation or for the evaluation of such a document project.
Dynamic charts with CIB chartDocument analysis with CIB report&analyse
Dynamic charts with CIB chart
Often the tables in raw texts, which are filled with current data by CIB merge, are not informative enough. A supplement by an optical business graphic, for example by a line, pie and bar chart, is desirable here. Of course, these graphics must be generated dynamically, also from the same current data of the application.
CIB chart is a module for the creation of dynamic business graphics, both for screen interface and for integration into documents. The product CIB chart consists of:
- the CIB chart designer which enables the text organizer to create graphic templates
- the CIB chart generator which is used at runtime of CIB merge to generate diagrams from supplied variable data.
The CIB chart designer is a stand-alone Windows application and is used by the text organizer to design a graphic template with sample data. The template is an Enhanced Metafile (EMF) with extensions in the form of CCR (=CIB chart Resource) commands.
This EMF shows the example graph based on test data with the layout (colors, dimensions and labels) designed by the CIB chart designer. It can be displayed with the usual graphic tools, such as the preview in Windows Explorer.
In Microsoft Word, the EMF can be inserted, positioned and scaled comfortably like any other graphic file via the menu option "Insert/Graphics/File...".
The CCR extensions in this graphic transmit the settings and data made in the CIB chart designer to CIB merge or CIB format. This allows the desired business graphic to be created at the time of document creation using the practical data available at that time and the layout predefined by the text organizer.Document analysis with CIB report&analyse
Many users create very complex document projects. In order to generate internal project reports or to carry out weak-point analysis in document modelling, there is the possibility of a "CIB report&analyse".
This reporting procedure is also integrated into the CIB workbench (AddIn under MS Office). Its use is described in a separate detailed guide.
4. Data supply
Besides the interpretation of field commands such as conditions, loops, formulas and insert commands, the insertion of variable data is a central task of CIB merge.
There are 4 different variants of data supply, which can also be used in mixed form.
- The supplied data has a structure in CSV file format
- (Distribution to several CSV files is also possible)
- Data is supplied via an XML file
- SQL queries are made directly from a document module
- UserExits are generated directly from a document module
4.1. CSV
GeneralNotes for the usage of separation and special characters inside the CSV file
Notes on UTF-8 encoded data CSVs
Single CSV file
Multi CSV file
General
The CSV files are one or more text files containing the names of the input fields and the corresponding values. The abbreviation CSV stands for "Comma Separated Values".
The first line of the control file contains the so-called control record, which consists of field names separated by ";". The tax record can contain any number of field names, limited only by the free working memory.
Each subsequent line contains exactly one data record. A data record contains the text modules or data to be inserted, also separated by ";", in the order of the field names. The number of entries in the data record must match the number of field names in the tax record.
CIB merge can process a single CSV file or multi-CSV files.
Usage with CIB merge:
The parameter -d<Dataset source> sets the CSV file for CIB merge, see chapter Parameter –d.
Notes for the usage of separation and special characters inside the CSV file
If a text passage to be inserted contains a semicolon, a tab character or a quotation mark, the entire text passage must be placed in quotation marks. Quotation marks in a text passage must then be doubled. For example, to insert the company name Laundry "Weißer Riese" in a raw text, the entry in the control file must have the following appearance: ; "Laundry""Weißer Riese"";.
CIB merge can also use the -T parameter to apply a different separator than ";" to the CSV files, see chapter Parameter –T.
The dataset can also be provided in a separate control file which can be set in CIB merge using the parameter –h, see chapter Parameter –h.Notes on UTF-8 encoded data CSVs
To merge UTF-8 encoded data files correctly using the CIB merge, the following steps are necessary:
1. The CIB merge
par file needs to be extended by the following parameter:
-putf-8
This parameter indicates that the data files are encoded in UTF-8 format.
2. Remove the "byte order mark" (BOM) from the data files.
Since for the processing of UTF-8 encoded data files by CIB merge the parameter described under 1.) is used, all characters contained in the data file are interpreted according to the UTF-8 character set. This also applies to a BOM. This results in error messages during processing. For this reason all BOMs must be removed from the data files used.
Single CSV file

Description
With the single CSV file, the input fields are directly assigned to their values. The user uses the field name directly in the document module to access a value.
|
Syntax |
Example |
|
Headline 1. DataLine … n.DataLine |
FieldName1;FieldName2 Value11; Value12 ... ValueN1; ValueN2 |
Multi CSV file

Description:
A multi CSV file can be used to manage several CSV files. It contains the names of all CSV files to be loaded in the current merge process. Using the fields in the header of the multi CSV file, each CSV file is assigned an alias name, which can then be used to access these CSV files in the document.
Usage with CIB merge
For a multi CSV data supply, in addition to the parameter -d with the multi CSV file, the parameter -c must also be set, see chapter Parameter -c.
|
Syntax |
Example |
|
Header with alias names All involved CSV file names
|
Table1; Table2 Tab1.csv; Tab2.csv
|

|
|
Syntax |
|
|
Syntax |
|
|
|
|
Tab1.csv |
|
|
Tab2.csv |
|
|
|
CSVName1; CSVName2 Value11; Value12 ValueN1; ValueN2 |
|
|
CSVName1; CSVName2 Value11; Value12 ValueN1; ValueN2 |
Advantages over XML:
- Simple format
- Simple 1-n relationship
- Smaller file size
4.2. XML
GeneralAdditional XML components
XML properties
General
Since version 3.9.x CIB merge also supports the processing of data in XML format. There is also a separate documentation for long-term CIB merge users to convert a document project, which was previously based on CSV data supply, step by step into XML based data supply.
Additional XML components
Support of the XML data supply is provided by means of additional DLLs, which must be installed in addition to the CIB merge DLL. These additional components are automatically included in CIB merge transfer packages and are dynamically activated by CIB merge only in case of XML data supply.
XML properties
XML documents have a physical and a logical structure.
The physical structure of an XML document consists of entities. The first entity is the main file of the XML document. Other possible entities are defined using entity references (&name; for the document or %name;
for the document type definition) included character strings, possibly even entire files, and References to character entities to include individual characters referenced by their number (&#decimal number;
, or &#xhexadecimal number;).An XML declaration is optionally used to specify XML version, character encoding, and process ability without document type definition.
A document type definition is used optionally to specify entities and the permitted logical structure.
The logical structure of an XML document is a tree structure and thus hierarchically structured. The following tree nodes exist:
Elements whose physical attributes are identified using
a matching pair of start tag (<Tag-Name>) and end tag (</Tag-Name>) or
(<Tag-Name />) can be used,
attribute name="attribute value") written with a start tag or an empty
element tag for additional information about elements (a kind of
meta-information)Processing Instructions (
<?target name parameter ?>)Comments (
<!-- comment text -->)
Text, which can appear as normal text or in the
form of a CDATA section (<![CDATA[ beliebiger
Text]]>).
An XML document must contain exactly one top-level element. Further elements can be nested below this document element.

The parameter -d<Dataset source> sets the CSV file for CIB merge, see chapter Parameter –d.
XML file
|
Syntax |
Example |
|
<XMLHeader>XMLData1</XMLHeader> <XMLHeader>XMLData2</XMLHeader> <XMLHeader>XMLData3</XMLHeader> <XMLHeader>XMLData4</XMLHeader>
|
<Data> <User>Tester</User> <Telephone>09/987 654</Telephone> <Street>Test Street 9</Street> <City>99999 Test City</City> </Data>
|
Multi XML file
Advantages over CSV:
- Fewer files
- Works internally via nodes
- RTF structures can be simplified with XPATH
4.3. ODBC and SQL
GeneralODBC versions
SQL
SQL queries in multi control files
Dynamic assigning of aliases
SQL-Queries in the field “REF”
General
SQL can be accessed directly from CIB merge via the CIB SQL DLL additionally stored in the program directory. The result of a query (a table) is used like a CSV dataset file. Instead of specifying a control file in the multi control file, a query is placed there in SQL. It is also possible to dynamically assign a control file or SQL query to existing or new control file aliases. Dynamic alias assignment is also allowed without any control file or multi control file. Furthermore, it is possible to insert the value of the first column and first row of a result table of an SQL query immediately into the raw text (without the detour via an alias, the field "Next" and variables).
ODBC versions
The CIB SQL Dll uses internally ODBC API conformance levels Core, Level 1 (e.g.: long data) and Level 2 (e.g.: scrollable cursor). The SQL conformance level Extended SQL Grammar is required for data fields. See ODBC SDK 2.10 Programmers Reference.
It is therefore important to ensure that the ODBC versions and driver versions used support the corresponding levels.
The CIB SQL functionalities have been tested with ODBC 3.51 under Windows NT 4.0 using the Microsoft Jet ODBC drivers for MS Access, which are supplied with the corresponding ODBC versions.
This version also supports joins (select to multiple tables).SQL
SQL access should be possible directly from CIB merge. The result of a query (a table) should be used like a control file. Instead of specifying a control file in the multi-control file, a query is placed in SQL. A second extension should be able to dynamically assign a control file or SQL query to existing or new control file aliases. A third extension is to insert the value of the first column and first row of a result table of an SQL query immediately into the raw text (without the detour via an alias, the "Next" field and variables). A fourth extension should allow dynamic alias assignment even without a multi-control file and possibly even without a normal control file.
SQL queries in multi control files
The entry of a field in the multi-control file usually looks like this: "[;]control file" or "header file;dataset file". For SQL accesses, there is the option of "SQL:Database;Query".
The new function is only available with a DLL for SQL queries.
The query is sent to the database. Further accesses are made with the known commands for control files with unchanged meaning. The only difference is the data source: The table is not in the control file as a set of records, but in a database. (The database must be set up as a user or system data source in the system settings for ODBC.)
The following example provides two control files with the aliases NormalDat and SqlDat The control file SqlDat contains two columns from the prices table. The database containing the table is made available via ODBC with the name ODBC Tariffs Database.
Multi control file:
NormalDat;SqlDat“normal.csv”; “SQL:ODBC Tariffs Database;SELECT TariffNo, TariffName FROM Tariffs ORDER BY TariffNo”
Dynamic assigning of aliases
The "Next" command usually reads the next data row or places the read position in front of the beginning of the data source. But it is also possible to redefine or reassign an alias with "NEXT DEF:Alias;Data source”.
The alias will be redefined if it does not exist yet. If the alias is already occupied, the associated data source will be closed and the alias reassigned.
The data source can be a control file or an SQL query. The value behind the semicolon must therefore look like an entry in the multi control file.
This function is also available without any control file or multi control file being specified in the parameters passed to CIB merge.
The example dynamically defines the alias SqlDyn in the raw text as the entire tariffs table. Certain fields are then listed in a table.
Raw text:
{ NEXT “DEF:SqlDyn;SQL:ODBC Tariffs table;SELECT * FROM Tariffs table ORDER BY TariffNo” }
|
Tariff number |
Name |
{ IF { DATASET ?SqlDyn } = 1 “
|
{ REF TariffNo \*Character format } |
{ REF TariffName \*Character format } |
{ Next SqlDyn }” \*while }
Restriction: Initially this function should only be available if a multi-controller file has been specified. A later extension to the case without any control file or at least without multi control file is intended.
SQL-Queries in the field “REF”
The command "REF" previously inserted the value of a variable into the raw text. The goal is to use "REF SQL:Database;Query" to insert the value of the first row and first column of the query result table into the text. No alias or variable is required, but the rest of the table is no longer available without a new query. (However, the purpose of this type of query is also to retrieve a single special value from the database, for which an extra query was necessary anyway.)
The following example inserts the name of a tariff into the raw text. The tariff is selected via the previously defined variable N. For this example, this variable must have the content "'801"" according to the database structure and SQL syntax. (including the single quotation marks), because the condition field TariffNo used is a text field.
Control file:
N;...
"'801'"; ...
Raw text:
{ REF "SQL:ODBC Tariffs Database;SELECT TariffNo FROM Tariffs WHERE TariffNo = {REF N}" }
Limitation:
This way, no memo fields can be selected in the first version. This is due to a technical limitation of Microsoft ODBC.
5. Technical interfaces
This chapter gives a short overview of the available API and its parameters. In general you can use the function cibmerge to set your desired parameters in CIB merge.
5.1. Operating principle
The interface philosophy of the CIB merge component is for historical reasons still different from the other CIB modules. The function for executing a mixing run still gets the call parameters set directly.
Very few of the properties are mandatory (e.g. input file(stream)). Many parameters are optional and enable the user to determine the desired result (e.g. working directories, optimization, encryption, default values, ...).
5.2. cibmerge
Syntax:
int WINAPI cibmerge(int argc, char *argv[])
Call parameters:
The call parameters are described in detail under Call parameters.
Return value:
0 if everything is successful
- 1 on abortion by user
> 0 on abortion by error
Troubleshooting:
An error code greater than 0 means that a problem has occurred and the mixing job was not completed properly. An error code less than 0 means that the user deliberately cancelled the mixing order. In addition, an error log file can be written during a CIB merge run, which contains detailed information about the error that occurred.
For more information about the error codes and the error log files, see Troubleshooting.5.3. CibMergeVB
The individual parameters are passed to this function in a long character string (=string), whereby a blank must be set for the separator, e.g.: "-I Input.rtf –o Output.rtf -@1"
Syntax:
int WINAPI CibMergeVB(char* strParameters)
Return value:
Troubleshooting:
No special troubleshooting is active.
Fallback
Calling concept
5.4. CibMergePFile
A parameter file name will be transferred to this function, for example D:\Test.par.
Syntax:
int WINAPI CibMergePFile(char* szParamFile)
Return value:
Troubleshooting:
No special troubleshooting is active.
5.5. GetMergeVersion
This function returns the current version number of the CIB merge DLL. This allows you to ensure that a minimum version is available in your application if, for example, you are using special program features that were not made available until a certain release.
Syntax:
unsigned long WINAPI GetMergeVersion()
Return value:
The return value returns the current version number of the CIB merge DLL. The long value returns the information in two ranges. The first two bytes contain the version counter of the main release. Bytes 3 and 4 contain the corresponding current release counter. Depending on the programming language the high and low ranges have to be considered accordingly (see code examples below).
Troubleshooting:
No special troubleshooting is active.
6. Call parameters in detail
The following chapter describes all available call parameters in alphabetical order. Many of the available parameters are optional and not mandatory.
Parameters can be transferred as single letters, such as -Iinput.rtf. However, it is also possible to transfer written-out parameters, such as --inputfile=input.rtf.
Formally, CIB can receive merge parameters in the form ('-'| '/') (("letter" | ("property" '=')) "value") | "property" from the command line.
6.1. General notes
- Upper and lower case
of the parameters is not relevant.
- All values supplied by letters also exist as long versions.
- Necessity to use "-" or "/" as start characters for parameters that are transferred as letters. For parameters that are written out in full, the start character is "--".
- The first parameters that are transferred without a start character are assigned the parameter characters from "IODH" in order (input, output, data).
- After evaluation of all parameters, "/@" is automatically executed.
- "Property" may contain any character except '='.
- The capitalization of the property is not important.
- Characters other than a-z, A-Z or 0-9 are treated like a '-'.
- The input of
('-' | '/') "Property"
stands for - A "+" after
a file name appends to the already existing file
a "!" after a file name overwrites an existing file (applies to parameter -o output file and parameter -l log file)
('-' | '/') "Property" '=' "Value"
with the empty string as value.
6.2. Note Calling examples
The parameter description contains short notes on how to use the parameter from a specific environment.
A more detailed description based on use cases can be found in the chapter "Application examples" Detailed code examples for various programming languages can be found in the chapter "Quick start".
6.3. Overview about the abbreviations for call parameters
|
Calling Parameters |
Description |
Type |
||
|
: |
--set |
Assignment of variable values |
Character string |
|
|
? |
--help |
Help (short user manual) |
|
|
|
@ |
--merge |
Merge |
Listing |
|
|
@* |
--parameter[file] |
Parameter file |
Input file |
|
|
2 |
--word2 |
Compatibility with WinWord 6 off |
Yes/No |
|
|
6 |
--word6 |
Compatibility with WinWord 6 on |
Yes/No |
|
|
A |
--source-directory |
Directory to insert (sources) |
Character string |
|
|
B |
--break |
break-level |
Listing |
|
|
C |
--(Meta|Multi)[datafile] |
Meta control file |
Yes/No |
|
|
D |
|
--data[file] |
Control file |
Input file |
|
F |
|
--filter |
Filtering |
Listing |
|
H |
|
--header[file] |
Header file |
Input file |
|
I |
|
Input[file] |
Input file |
Input file |
|
K |
|
--keep-fields |
Outputting field instructions (keep fields) |
|
|
L |
|
Log[file] |
File for notifications (logs) |
Output file |
|
M |
|
--message |
Notification (output text) |
Character string |
|
O |
|
Output[file] |
Output file (RTF) |
Output file |
|
P |
|
--codepage |
Character set (codePage) |
Listing |
|
Q |
|
--target-directory |
Work directory for output files |
Character string |
|
R |
|
--field-results |
Do not write results |
Listing |
|
RTA |
|
--short-tokens |
Short RTF tokens for formatter (faster) |
|
|
S |
|
--HTML-switches |
Switch for HTML-conversation |
|
|
T |
|
--delimiter |
Delimiter for control files |
Character string |
|
V |
|
--version |
Version |
|
|
W |
|
--window-handle |
Target for Windows messages |
Character string |
|
X |
|
--dialog |
Cancel dialog progress bar |
|
|
Y |
|
--encrypt |
Encryption |
Yes/No |
|
Z |
|
--compress |
Compression |
Listing |
6.4. Parameter --analyse
The parameter --analyse is only relevant for the reporting tool "CIB report&analyse". It determines the static field structure.
Syntax
--analyse=<Dateiname>
Description
The structure, which is determined by means of --analyse, can be used for further analysis or presentation. The message is sent to a separate file in CSV format. Initially, only Ref, Mergerec, Next and Includetext (Ref, Record, Next and Insert text) fields are determined. They have only one parameter, which is also reported. This parameter is useful in the additional project CIB report&analyse.
The static field structure is the same order of the fields as written down.
Example for static field structure
{If {Mergerec ?Data} <> 0 „{Ref Name}{Next data}” \* Solange} reports 1. If, 2. Mergerec, 3. Ref and 4. Next
The dynamic field structure is the order of the fields during the evaluation.
Examples for dynamic field structure
{If {Mergerec ?Data} <> 0 „{Ref Name}{Next data}” \* Solange} reports 1. If, 2. Mergerec, 3. Ref, 4. Next, 5. Mergerec, 6. Ref, 7. Next, 8. Mergerec, 9. Ref, 10. Next, … etc., until the loop is complete.
CSV-Dateien bestehen aus Zeilenschaltungen getrennte Datenzeilen, welche durch Komma, Tabulator oder Semikolon () getrennt sind. Die erste Zeile enthält die Spaltenüberschriften (Feldnamen). Jede Zeile muss die gleiche Anzahl Felder haben. Felder, die Feldtrenner oder Zeilenschaltungen oder Anführungszeichen im Inhalt haben, werden von Anführungszeichen umschlossen. Die inhaltlichen Anführungszeichen werden verdoppelt.
Example: Extract from the parameter file:
--logfile=!fields.csv -mPath;Field;Value --logfile=!cibmerge_blocks_analyse.log --source-directory=templates --outputfile=- --analyse=+fields.csv # for all text --inputfile=basicblock.rtf -m@ --filter --inputfile=reference.rtf -m@ --filter ... for all RTF blocks... --inputfile=rootblock.rtf -m@ --filter -mdone
This example consists of several RTF blocks. The --analyse parameter is used to generate the output "fields.csv". This file has the following structure:
Path;Field;Value
A more detailed description of the output can be found in the application example blocks.
Note:
Because of the static field sequence, fields in loops are output only once. For the same reason, fields from both the then and else branches of an if statement will be output. Since the filter and not the merge process generates the output, no fields are calculated and therefore no embedded texts (include text) are expanded or their fields output.
If you do a related field analysis over a whole lot of texts and blocks, you will also get the call tree with the inserted blocks. Identical fields that occur more than once are also reported several times (e.g.: two times {Ref Name})
6.5. Parameter --break
[-b]
The parameter --break shifts the time at which CIB merge stops a mixing process in case of an error.
Syntax
--break=<Abbruchniveau>
<Abbruchniveau>: all, loop, doc, par, never oder ok
Description
CIB merge aborts the processing in various situations with error messages. This occurs especially in mixing processes, for example, when a variable is used that is not defined.
In some situations, however, it is desirable that CIB merge does not terminate immediately on every error, but continues with the processing if possible. For this purpose the parameter B for break was introduced in version 3.7.62.
In order to find the position in the raw text or text module, CIB merge also outputs the subsequent errors or situations after the cause of the error. (This corresponds to a kind of "stack unrolling".) CIB merge also writes the closing brackets of the raw text, as far as the situation allows, so that the text can be opened by other applications.
<cancellation level> determines the point up to which the process is continued or aborted. The following values are possible:
|
Cancellation level |
Description |
|
all |
always cancel, never continue (default) |
|
loop |
continue to the end of the loop, cancel it (also series and parameters) |
|
doc |
continue until end of document, cancel series (also parameters) |
|
par |
continue to the end of the series (-@), no more parameters |
|
never |
continue until all parameters are processed, no cancellation, but return error code |
|
ok |
move until all parameters are processed, no cancellation, return OK |
|
However, CIB merge will continue to output all errors to the error log file, only with the note "==>continue (parameter "break" with level "XXX")" after certain mistakes. |
|
Examples
--break=loop
If the mixing run is currently in a loop, it will only run until the end after the error, i.e. will not be repeated. Immediately after this, the mixing process will be cancelled.
--break=never
CIB merge carries out the mixing job to the end regardless of any errors occurring and returns the error code of the first error that occurred.
The use of the parameter with these two example assignments is described in detail in the use case example Templates.Note
Independently of --break=<cancellation level> all errors occurring up to the end or cancellation of the mixing process will be logged in the log file.
6.6. Parameter --charformat
With --charformat can be determined, if CIB merge shall use the switch \* CHARFORMAT if the results of fields do not deliver an own formatting.
Syntax
--charformat=<Option>
<Option>: off/none, auto/automatic oder plain-values-only
Description
With the parameter --charformat can be set, for which fields the character format is to be changed, i.e. for which fields the formatting is to be transferred to the field contents.
With the parameter --charformat most of the \* CHARFORMAT switches can be omitted, making the raw text shorter and more readable.
If the \* NOCHARFORMAT switch is specifically set for a field, this can prevent the --charformat parameter from being applied to this field (from CIB merge version 3.9.156).Nicht formatbehaftet sind Feldinhalte aus CSV-Datei, aus Paramterdatei, Datum Felder mit Schalter sind formatbehaftet.
For <Option> can be set the following values:
|
Option |
Description |
|
off or none |
The character format is not changed unless \* CHARFORMAT is explicitly specified in the field. |
|
auto or automatic |
Default setting. |
|
plain-values-only |
The character format is changed for fields that produce results without their own formatting, whether or not they have switches. |
Example
--charformat=plain-values-only
The
result of
{REF Vorname \* <cib-formfield type="text" info="Vorname" testvalue="Max" />}
gets the formatting of the REF field if --charformat=plain-values-only is set (in this case the text is written bold), although this field has a switch.
The use of the parameter is described in detail in the use case example Gap Text.There are field contents with formatted values on the one hand and field contents with non-formatted values on the other.
Formatted values that are output as field results do not need the field switch \* CHARFORMAT, but could be formatted in the same way.
Examples of field contents with formatting
are:
{includetext}, inserted RTF contents, {REF} (if the variable is formatted).
In these cases it is normally not useful to use the --charformat parameter. If desired, the \* CHARFORMAT switch can be set manually.
Values that CIB merge calculates from fields may be visible in the input text, may be completely new or may originate from the control file.
Examples of visible values are IF fields whose text comes from one of the alternatives exactly as it appears in the field or values assigned with SET. Visible values are formatted and not affected by the parameter.
By using the switch \*NOFORMAT in the SET command, this value can be turned into a non-formatted value (from CIB merge version 3.9.174).
Non-formatted values appear by default in the standard font (Times Roman, font size 10). They will be formatted by the --charformat parameter as if you specified the /* CHARFORMAT switch each time.
Examples for field contents with: {MERGEREC}, {date}, {=…}, values from CSV, {REF} (if the variable is not formatted),.
If --charformat is set for these fields, the \* CHARFORMAT switches can be omitted.
Examples of generated values are Aktualdat or the expression calculation with "=". These values are not formatted and are therefore affected by the parameter when they appear in the output.
Furthermore, there is no need to apply the switch if another switch already changes the formatting, for example \@ "dd.MM.yy". Here the formatting of the mask is used and not the character format. This also applies to superior fields. An IF field with \* CHARFORMAT does not need to handle the contents from the THEN or ELSE part in a formatted manner. A field contained in one of the two parts is formatted with the character format anyway.6.7. Parameter --chart-…
GeneralParameter --chart-output-format
Parameter --chart-source
Parameter --chart-target
General
The --chart parameter allow the creation and insertion of dynamic business graphics. In this case, CIB merge can leave the graphic statement in the text or replace it with the updated graphic. CIB merge automatically updates (overwrites) the original file and removes the binary graphic data from the result if the graphic statement is kept. Otherwise, the file remains unchanged and only the result will be embedded in the RTF output instead of the instruction.
It is also possible to embed graphic data from non-chart graphics from a file into the RTF. The following image formats are supported: BMP / DIB, EMF (chart and non-chart graphics), PNG, JPG and WMF.
The following parameters are provided:
|
--chart-output-format |
Determines the output format of the graphic (only relevant for chart graphics) |
|
--chart-source |
CIB merge takes the graphic description from the given source |
|
--chart-target |
CIB merge writes the updated graphic to the specified destination. |
Parameter --chart-output-format
CIB merge can deliver all graphic formats offered in CIB chart designer as result. S If you want to leave the graphics statement in the text, you can either set "--keep-fields" for all fields or insert the switch "\* leave" in selected graphics statements.
The --chart-output-format parameter determines the output format of the graphic.Syntax:
--chart-output-format=<Bildformat>
<image format>: ccr (CIB chart resources), emf (Enhanced Metafile), or emfccr (Enhanced Metafile extended by CIB chart resources (embedded))
Parameter --chart-source
With --chart-source you specify whether the chart should be calculated from the embedded data, or, in the case of an INCLUDEPICTURE instruction, for the contents of the specified file or never. ({\pict} do not calculate).
Syntax:
--chart-source=<Option>
<Option>:
auto, file/datei, none/ignore/ignorieren/kein/keine oder document/dokument/embed/embedded/einbetten/eingebettet
For the graphic source, the following settings are available <Option> :
|
Option |
Description |
|
none ignore kein |
No {\pict} group will be updated. |
|
file/datei |
CIB merge takes the graphic description from the file specified in the {INCLUDEPICTURE} statement if the {\pict} group is in its result. |
|
document/dokument embed/embedded einbetten/eingebettet |
CIB merge takes the embedded data as source |
|
auto |
CIB merge takes the file with priority. If this does not work, the embedded data is used. (Default and default) |
Parameter --chart-target
The --chart-target parameter determines where the output of the updated graphic data is to be written: embedded in the document or over the old content of the specified file.
Syntax:
--chart-target=<Option>
<Option>: auto, file/datei, none/ignore/ignorieren/kein/keine oder document/dokument/embed/embedded/einbetten/eingebettet
Description:
For the graphic target, the following settings are available for <Option> :
|
Option |
Description |
|
none ignore/ignorieren kein/keine |
No {\pict} group will be updated. |
|
file/datei |
CIB merge writes the graphic description in the file specified in the {INCLUDEPICTURE} statement if the {\pict} group is in its result. |
|
document/dokument embed/embedded einbetten/eingebettet |
CIB merge embeds the data in the target document. |
|
auto |
CIB merge writes the file with priority if the {INCLUDEPICTURE} statement comes with --keep or \* lassen into the output. If this does not work or the statement is removed, the data will be embedded. (Standard and default) |
If no chart library is available, chart graphics are treated like normal graphics.
By setting the parameter --chart-target=embed, if --chart-source is not "embed", the image data of EMF, JPG (JPEG), PNG, WMF and BMP or DIP graphic files are embedded in the result RTF. The type of file format is determined by the file content, not by the suffix.
Example:
--chart-source=file
--chart-target=embed
The graphic data here origins from one file. All graphics (chart and non-chart graphics) should be embedded in the result RTF.
The parameter are described in detail in the use case example Templates.
The following table provides an overview:
|
Graphic source |
Graphic target |
Not embed chart |
Chart |
Chart |
Update chart |
Embed chart |
Write chart in file |
|
ignore |
ignore |
– |
– |
– |
– |
– |
– |
|
ignore |
file |
– |
– |
– |
– |
– |
– |
|
ignore |
embed |
+ |
– |
+ |
– |
+ |
– |
|
ignore |
auto |
– |
– |
– |
– |
– |
– |
|
file |
ignore |
– |
– |
– |
– |
– |
– |
|
file |
file |
– |
– |
+ |
+ |
– |
+ |
|
file |
embed |
+ |
– |
+ |
+ |
+ |
– |
|
file |
auto |
– |
– |
+ |
+ |
+ (1) |
+ (2) |
|
embed |
ignore |
– |
– |
– |
– |
– |
– |
|
embed |
file |
– |
+ |
– |
+ |
– |
+ |
|
embed |
embed |
– |
+ |
– |
+ |
+ |
– |
|
embed |
auto |
– |
+ |
– |
+ |
+ (1) |
+ (2) |
|
auto |
ignore |
– |
– |
– |
– |
– |
– |
|
auto |
file |
– |
+ (3) |
+ (4) |
+ |
– |
+ |
|
auto |
embed |
+ |
+ (3) |
+ (4) |
+ |
+ |
– |
|
auto |
auto |
– |
+ (3) |
+ (4) |
+ |
+ (1) |
+ (2) |
(1) „Keep“ switch not set
(2) „Keep“ switch set
(3) Data could not be read from the file
(4) Data could be read from the file
6.8. Parameter --codepage
[-p]
The --codepage parameter controls the currently used character set for the control file (for control file see parameter --datafile or --headerfile).
Syntax
--codepage=<Zeichensatz>
<Zeichensatz>: pca, pc, utf-8 oder ansi
Description
If the parameter --codepage is not specified and thus no character set is defined for the control file, the default is the declaration in the RTF input file (e.g. \rtf1\ansi). The following character sets are permitted: pca, pc, utf-8 or ansi.
Examples
--codepage=pca
Here a different character set is used in the CSV files (here pca). This must be specified via the --codepage parameter.
The use of the parameter is described in detail in the use case example Gap Text.
Note:
For the RTF templates the code page specified in the RTF input file is always used.
See also the notes on UTF-8 encoded data files in chapter “Notes for UTF-8 coded data CSVs”.
6.9. Parameter --colors
The parameter --colors can be used to optionally disable optimizations that are performed for color tables in the header of the RTF document.
Syntax
--colors=<Option>
<Option>: keep, expand, optimize oder minimal
Description
Every RTF document contains color tables in the header. Therefore CIB merge has to spend time for matching because of inserts or for optimization. But not every user is interested in this adjustment or optimization. Therefore they can be switched off with the parameter --colors.
Possible values for <Option> are:
|
Option |
Description |
|
keep |
The main color table remains unchanged, even if the inserted text templates actually require an extension or unused colors could be removed. |
|
expand |
Colors are added to the main color table if the inserted text templates require an extension. Unused colors are not removed. |
|
optimize |
Colors are added to the main color table if the inserted text templates require an extension. Unused colors are removed if they are not among the 17 standard colors of MS Word. |
|
minimal |
Colors are added to the main color table if the inserted text templates require an extension. Unused colors are removed, even if they belong to the 17 standard colors including "automatic". MS Word usually has the color "automatic" at the position zero and then 16 standard colors at the positions one to 16. After that the additional colors are added. |
Example
--colors=expand
New colors used in RTF components are added to the color table and unused colors are not removed. Therefore no optimization takes place.
The use of the parameter is described in detail in the use case example Templates.6.10. Parameter --compress
[-z]
If the --compress parameter is set, CIB merge compresses the output file using the zlib method.
Syntax
--compress=<Komprimierungsgrad>
<Komprimierungsgrad>: 1-9
Description
If the --compress parameter is used for compression, the priorities between the optimization time and the result for the desired application must be evaluated. More time will produce very small results, but the fastest possible compression will produce a very small but not minimal result.
The user can therefore set the --compress parameter to an integer value from 1 to 9. The default value is 6.
Examples
--compress
CIB merge komprimiert mit dem Default-Komprimierungsgrad 6.
--inputfile=Optimierung_in.rtf --outputfile=!Optimierung_out.rtf --compress=9
The file is compressed as much as possible. This results in a smaller file size, but a slightly increased time for this merging process.
The use of this parameter is illustrated together with other optimization parameters in the use case example Gap Text.
6.11. Parameter --datafile
[--data/-d]
Set the data source with the --datafile parameter.
Syntax
--datafile=<Dateiname>
Description
A file in CSV or XML format can be specified as data source.
If the data is distributed over several data files, the multi-controller file must be specified here and the parameter --multidatafile must also be set.Examples
Single CSV via parameter file
--datafile=Adresse.csv
The data is located in a single data source called Addresse.csv.
This way of using the parameter is demonstrated in the use case example Gap Text.
Multi CSV via parameter file
--datafile=multi.csv --multidatafile
The data is distributed over several data files, which are specified in the file multi.csv. To define that it refers to a multi CSV, the parameter --multidatafile must also be set.
This way of using the parameter is demonstrated in the use case example serial letter.
If the parameter --target-directory is also set, the multi.csv and all other data files are expected in this directory:
--target-directory=csv
The use of the combination of the parameters --datafile and --target-directory is demonstrated the use case example Templates.
Multi XML via parameter via
--headerfile=XML:Daten_mitAlias.xml --datafile=/root/multi --multidatafile
The --datafile parameter sets the XPath to the multi nodes.
This context is demonstrated in the use case example serial letter.
Note:
The first line of the record source contains the so-called tax rate, which consists of field names separated by ";". This tax rate can also be provided in a separate tax rate source, which is set with the parameter --headerfile.6.12. Parameter --default-mode
[--defaultmodus/--default-modus]
The --default-mode parameter provides a mechanism to determine a default value for each variable if the variable is undefined or empty.
Syntax
--default -mode=<Value>
<Value>: -/off/aus/no/none/kein/keiner/nein, undefiniert/undefined/+, leer/empty oder beides/alles/both/all/voll/full
Description
The --default-mode parameter is only to be used in combination with the --default-prefix parameter. This defines the prefix that is placed in front of a variable name. When the REF field is evaluated, it is determined whether the value is suitable for the default behavior, otherwise the value or an error is output. The default behavior occurs under the following conditions:
- “Variable is undefined and behavior accordingly selected” or
- “Variable is defined and empty and behavior accordingly selected”.
- If one of the conditions applies, the variable name is composed of the default prefix and the old name. If such a default is again not set, there is another one for all together. Only if this does not exist, the usual error is reported that a variable is not defined. You can choose between 'no default', 'default for empty', 'default for undefined' and 'default for both'. The default is "no default“.
Possible values for <Value> are:
|
Option |
Description |
|
-/off/aus/no/none/kein/keiner/nein |
Standard, no default |
|
undefiniert/undefined/+ |
Default for undefined variables |
|
leer/empty |
Default for empty variables |
|
beides/alles/both/all/voll/full |
Default for both cases |
Example
--default-mode=all
The system searches for a suitable default value if a variable is empty or undefined.
The use of the parameter is described in detail in the use case example Gap Text.
6.13. Parameter --default-prefix
This parameter defines a prefix for variables, i.e. it sets a prefix before the original variable name.
Syntax
--default-prefix=<prefix>
Description:
With the parameter --default-prefix a variable can be assigned a substitute value (default). The common default is the variable that has the same name as the default prefix. The default prefix is “default”. This parameter must be specified in combination with the --default-mode parameter.
Example 1
--default-mode=all --default-prefix=Default.
Here a default value is searched for if a variable cannot be filled by the data supply because the variable does not exist or is empty. To determine the default value, the prefix "Default." is prefixed to the variable.
The use of the parameter is described in detail in the use case example Gap Text.Example 2
--default-mode=undefined --default-prefix=Default.
Assignment of variables: A=Anton, B=Berta, C=, Default.B=Bruno, Default.C=Cäsar, Default.D=Dora, Default.=Mama
The default mode defines the prefix "Default" for undefined variables. The variables supply the following values:
REF A delivers Anton
REF B delivers Berta
REF C delivers „“
REF D delivers Dora
REF E delivers Mama, because Default.E is not defined. If "Default." were not assigned, there would be an error with the message that E is not assigned.
If the default mode is set to all or empty (--default-mode=all/--default-mode=empty) then the evaluation for REF C provides Cäsar.
REF D returns an error with a default mode off (--default-mode=off) or empty (--default-mode=empty).
6.14. Parameter --delimiter
[-t]
The --delimiter parameter defines a different delimiter for the control files. The default delimiter for the control files is ";".
Syntax
--delimiter=<Trennzeichen>Example
--delimiter=,
CIB merge now interprets the comma character instead of the semicolon as separator.
The use of the parameter is described in detail in the use case example Gap Text.
6.15. Parameter --destination-colorschememapping
(from CIB merge version 3.12.2)
This parameter can be used to control whether the \*\colorschememapping is included in the output file.
Syntax
--destination-colorschememapping=<Option>
<Option>: keep, remove oder merge
Description
Possible values for <Option> are:
|
Option |
Description |
|
keep |
All color scheme mapping information found in the original RTF will be passed to the output RTF unchanged. (Same behavior as CIB merge versions lower than 3.9.185) |
|
remove |
No color scheme mapping information will be
passed to the output RTF. |
|
merge |
This parameter behaves like keep. |
6.16. Parameter --destination-datastore
(from CIB merge version 3.12.2)
This parameter controls whether the \*\datastore is included in the output file.
Syntax
--destination-datastore=<Option>
<Option>: keep, remove oder merge
Description
Possible values for <Option> are:
|
Option |
Description |
|
Keep |
All datastore information found in the source RTF will be passed to the output RTF unchanged. (Same behavior as the CIB merge versions lower than 3.9.185) |
|
remove |
No datastore
information will be passed to the output RTF. |
|
merge |
This parameter behaves like keep. |
6.17. Parameter --destination-themedata
(from CIB merge version 3.12.2)
This parameter controls whether to transfer \*\themedata in the output file.Syntax
--destination-themedata=<Option>
<Option>: keep, remove oder merge
Description
Possible values for <Option> are:
|
Option |
Description |
|
Keep |
All themedata information found in the source RTF will be passed to the output RTF unchanged. (Same behavior as the CIB merge versions lower than 3.9.185)) |
|
remove |
No themedata
information will be passed to the output RTF. |
|
merge |
This parameter behaves like keep. |
6.18. Parameter --dialog
[-x]
The --dialog parameter displays a percentage bar on the screen during the mixing process (non-modal dialog mask). The mixing process can be stopped using the Cancel (Abbrechen) button.
In exceptional cases, the system will not start the progress bar in the foreground. With the "top" switch, the progress bar is explicitly placed in the foreground at startup.Syntax
--dialog
Beispiel
--dialog=top
The progress bar moves to the foreground when the mixing process is started.

In the use case example Serial Letter, the progress bar is used to terminate an endless loop.
6.19. Parameter --directory-…
The directory parameters allow a file-less data entry. This is done via entries (virtual files) in virtual directories.
The following parameters are available:
|
--directory-log |
writes the content of a virtual file with start and end line to the error output. |
|
--directory-read |
stores the content of a file in the virtual directory. |
|
--directory-remove |
removes the specified entry from the virtual directory. |
|
--directory-set |
defines a virtual file. |
|
--directory-set-inline |
file-less data input using the parameter file. |
|
--directory-write |
writes the content from a virtual directory to a file |
6.20. Parameter --directory-set-inline
The parameter --directory-set-inline allows a file-less data entry using the parameter file.
Syntax
--directory-set-inline=<virtueller Dateiname> VAR1;VAR2 VALUE1;VALUE2 VALUE3;VALUE4 … end-of-file
Description
The --directory-set-inline parameter reads the lines of the parameter file up to the end-of-file. This means that all lines between --directory-set-inline and end-of-file are interpreted as contents of <virtual filename>. The content is entered in the virtual directory under <virtual filename>. If a content already exists, it will be overwritten.
Example
Excerpt from a parameter file with file-less data input:
--datafile=daten.csv --directory-set-inline=daten.csv Var1;Var2;Var3 Wert1.1;Wert1.2;Wert1.3 Wert2.1;Wert2.2;Wert2.3 end-of-file
The parameter --directory-set-inline=data.csv indicates file-less data entry. The following lines are read in up to the "end-of-file" line and thus form the contents of the virtual file named data.csv.
6.21. Parameter --directory-log
The --directory-log parameter writes the contents of a virtual file with the start and end line to the error output.
The start line is --directory-set-inline.
The end line is “end-of-file”.Syntax
--directory-log=<virtueller Dateiname>
Example
--logfile=!merge.log --datafile=daten.csv --directory-set-inline=daten.csv var1;var2;var3 1.1;1.2;1.3 2.1;2.2;2.3 3.1;3.2;3.3 end-of-file --inputfile=directory-set-inline.rtf --directory-log=daten.csv
The content and the start and end line are written to the log file. The content of the log file merge.log looks like this:
--directory-set-inline=daten.csv
var1;var2;var3
1.1;1.2;1.3
2.1;2.2;2.3
3.1;3.2;3.3
end-of-file
6.22. Parameter --directory-read
The --directory-read parameter stores the contents of a file
in the virtual directory. If necessary, the existing content will be
overwritten.
This Parameter is also used for
Merge-Recombine. (from CIB merge version
3.9.181)
Syntax
--directory-read=<Dateiname>
or
--directory-read=<virtueller Dateiname>=<Dateiname>
or (from CIB merge version 3.9.181)
--directory-read=cibrec-snippetN.rtf=<Dateiname>
N=0,1,2….
Description
For <filename> all specifications are possible, which are also allowed with the parameter --inputfile. The short form of the parameter is --directory-read=<filename>, where <filename> is also used as <virtual filename>.
Note: If the <filename> contains the characters "+" "-" "!", these are interpreted as switches and are not considered part of the file name.
Any switches +/-/! etc. are not included in the name.
Merge
recombine (from CIB merge version
3.9.181):
The CIB viewers (CIB view&rec and CIB jview&rec2) offer the
possibility to enter or edit text passages in CIB REC fields. These text passages
are stored by the CIB viewers in so-called RTF snippet files. When the editing
process of a document is finished, CIB merge merges the RTF snippets into the
document and saves them as new output RTF.
The snippet files are transferred to CIB merge using the parameter "--directory-read=cibrec-snippetN.rtf=<filename>" if the files are on the hard drive.
Example
--directory-read=inNeu.log=in.log --directory-write=inNeu.log=!out.log
The --directory-read parameter stores the content of the file in.log into the virtual file inNew.log. In the next step, the virtual file with the name inNew.log is taken and the content is written to out.log.
6.23. Parameter --directory-remove
The --directory-remove parameter removes the specified entry from the virtual directory, or all entries if no name is specified.
Syntax
--directory-remove
or
--directory-remove=<virtueller Dateiname>
Example
--directory-remove=name
The entry "name" will be removed from the directory.
--directory-remove
All entries will be removed from the directory.
6.24. Parameter --directory-set
The command --directory-set=<virtual filename> defines a virtual file under <virtual filename> and is stored in the memory of CIB merge. A useful application is for example to transfer CSV data file-less. For a transfer in a parameter file the call parameter --directory-set-inline.is to be used.
This parameter is also used for the merge recombine. (from CIB merge version 3.9.181)
Syntax
--directory-set=<virtueller Dateiname>
or (from CIB merge version 3.9.181)
--directory-set=cibrec-snippetN.rtf={\rtf1 ...}
N=0,1,2….
Description
Merge
recombine (from CIB merge
version 3.9.181):
The CIB viewers (CIB view&rec and CIB jview&rec2) offer the
possibility to enter or edit text passages in CIB REC fields. These text
passages are stored by the CIB viewers in so-called RTF snippets. When the
editing process of a document is finished, the CIB merge merges the RTF
snippets into the document and saves them as new output RTF.
The snippet files are passed to the CIB merge using the parameter "--directory-set=cibrec-snippetN.rtf={\rtf1 ...}", if the snippet is transferred to memory.
6.25. Parameter --directory-write
The command --directory-write=<virtual filename>=<filename> writes the contents of <virtual filename> from the virtual directory to the file <filename>. Any switches +/-/! etc. are not included in the name.
Syntax
--directory-write=<virtueller Dateiname>=<Dateiname>
Example
--directory-set=out=out.log --directory-write=out.log=!out.log
The virtual file named out.log is taken and the content written to out.log.
- Comparison: file-based and file-less data entry
Starting from a classic file-based example, alternatives are presented using the means just mentioned.
The output of the RTF can be done file-less with means described in other documents and is not mentioned here!
- Java merge job and retrieval of error text and number
Data input by file:
The data.csv should be merged into the input.rtf. The output is called output.rtf. Errors are written to merge.log. All files are located in the file system under directory test.
JCibMergeJob t_Job = new JCibMergeJob();
t_Job.initialize();
t_Job.setProperty(ICibMergeJob.PROPERTY_WORKSPACE, "test\\");
t_Job.setProperty(ICibMergeJob.PROPERTY_ERRORFILE, "merge.log");
t_Job.setProperty(ICibMergeJob.PROPERTY_DATAFILE, "daten.csv");
t_Job.setProperty(ICibMergeJob.PROPERTY_INPUTFILE, "input.rtf");
t_Job.setProperty(ICibMergeJob.PROPERTY_OUTPUTFILE, "output.rtf");
t_Job.execute();
int error =
((Integer)t_Job.getProperty(ICibMergeJob.PROPERTY_ERROR)).intValue();
if(error > 0)
{
String errortext = (String)t_Job.getProperty(ICibMergeJob.PROPERTY_ERRORTEXT);
}
Data input without file:
Only data.csv should be transferred in the first step file-less. The content is in the string variable csv_data. The following additional property is set for this. (The rest remains unchanged)
t_Job.setProperty(ICibMergeJob.PROPERTY_DICTIONARY_SET, "daten.csv=" + csv_data);
- Merge job via parameter file (Java, C++ or COModSuite)
Data input by file:
Content of the merge.par file:
-L!merge.log -V -Ddaten.csv -Iinput.rtf -O!output.rtf -M@ -@1 -MEnde
Specify log file
Report version
Specify data, input and output files
Report file names
Merge single document
Call "cibmrg32.exe -@merge.par" to start the job.
Data input without file:
Similar to the case in Java, this is also possible in the parameter file:
The parameter file merge.par must be supplemented by the following specification (rest remains unchanged)
--dictionary-set-inline=daten.csv Var1;Var2;Var3…
Wert1.1;Wert1.2;Wert1.3… Wert2.1;Wert2.2;Wert2.3… … end-of-file
- Job from C++
Data input by file:
const char *const arguments[]= { „cibmerge“, „-L!merge.log“, „-Ddaten.csv“, „-Iinput.rtf“, „-O!output.rtf“, 0 }; cibmerge(sizeof(arguments)/sizeof(*arguments) – 1, arguments);
Data input without file:
Here the data is transferred in string constants. A better option would be to assemble them dynamically via stringstreams of the STL:
The arguments must be extended by the following specification (rest remains unchanged):
„--dictionary-set=daten.csv\n“ „Var1;Var2;Var3…\n“ „Wert1.1;Wert1.2;Wert1.3…\n“ „Wert2.1;Wert2.2;Wert2.3…\n“ „…\n“
6.26. Parameter --docproperty
(from CIB merge version 3.9.181)
This parameter can be used to set and merge document properties.
Syntax
-- docproperty=[key]=[value]
Description
The parameter--docproperty enables the user to define the document properties of the output document.
Both predefined values (author, title, etc.) and user-defined document properties are supported.
Possibilities for use are, for example:
- Simple and central assurance of the document properties of the output documents before they reach the customer environment (consistent author for all outgoing documents).
- Using the document properties to transfer additional information
6.27. Parameter --encrypt
[-y]
The parameter --encrypt generates an encrypted output format that can be further processed by other CIB components (for example CIB format/output).
Syntax
--encrypt
Description
The encryption used by the --encrypt parameter is based on a CIB proprietary CC9 algorithm. This algorithm is intended to make the modules or intermediate results "unreadable" and thus prevent "immediate" manipulation of the content.
The encrypted file cannot be opened with MS-Office.Example
--encrypt
The output file is encrypted here.
The use of the parameter is described in detail in the use case example Gap Text.6.28. Parameter --field-nesting-level-limit
(from CIB merge 3.12.10)
With the parameter --field-nesting-level-limit the nesting depth of field commands can be limited.
Syntax
--field-nesting-level-limit=number
number=integer between 0 and n
Description
The --field-nesting-level-limit parameter can be used to limit the nesting level of field commands.
The default value is "0", i.e. the nesting level is not limited.
If the value is greater than 0, the CIB merge terminates with error 810 when this nesting level is reached.
Note: This parameter is only effective for the merge template combine!Example
--field-nesting-level-limit=10
CIB merge interrupts with error 810 when a nesting level of 10 is reached.
6.29. Parameter --field-results
[-r / -rp]
The --field-results parameter can be used to control whether all field-results are removed in Rich Text Format, thus reducing the size of the output file.
Syntax
--field-results
or
--field-results=p
Or (from CIB merge
3.9.183)
--field-results= Keepswitch
Description
MS Word generates field results in RTF. In most cases, these entries are not required by the CIB office modules. The parameter --field-results removes these entries.
For certain graphic objects, CIB format requires certain parts of the field results for positioning and scaling in individual cases (e.g. positioning graphics over text). The switch p "print" (short: -rp) causes CIB merge to receive these data. In addition, further entries are removed from the RTF, which are not required for further processing with CIB format. If in doubt, --field-results=p should be used, as the output file size increases only slightly compared to --field-results, and CIB format will certainly have all the necessary information available.
--field-results is usually used to optimize the file size of an RTF project before testing and delivery. On request, CIB Support will provide you with detailed information on the optimization of RTF projects.
Keepswitch (from CIB merge 3.9.183):
There
are use cases in which the data supply of a document must be carried out over
several merge processes, because not all information is available at the time
of the first run. In this case, the field contents of the previous merge
processes must be retained for the subsequent ones.
Example
--inputfile=wurzelbaustein.rtf --outputfile=!..\result\wurzelbaustein_FieldResults.rtf --field-results=p --filter=f
CIB merge does not merge field contents (--filter=f), removes all field-results which are not relevant for CIB format (--field-results=p) and writes the output file accordingly.
The use of this parameter is illustrated in the application example blocks. CIB merge does not merge field contents (--filter=f), removes all field-results which are not relevant for CIB format (--field-results=p) and writes the output file accordingly.
The use of this parameter is demonstrated in the usage example Templates.
Note:
RTF files created with --field-results should no longer be edited with MS Word. Documents with scaled graphics or graphics positioned over text can no longer be displayed and edited correctly in MS Word. When saving with MS Word, the advantage of the reduced file size is also lost again.
The file size of the output file can be additionally reduced by CIBrtf output with --short-tokens and compressed with --compress.6.30. Parameter --filter
[-f / -ff]
With the parameter --filter CIB merge does not evaluate the field contents, but only reads the input file and writes the output file according to the set parameters.
Syntax
--filter
or
--filter=f
Description
With --filter the field contents are not evaluated, but parsed and translated. This can be prevented with the switch f = "fast". So --filter=f filters faster (without syntax check of the RTF stream), --filter can detect errors in the fields more easily.
--filter=f (or also -ff) is mostly used to optimize or encrypt RTF projects before testing and delivery, see chapter Overview: Optimization, Encryption and Compression and parameter --field-results.
Example
--inputfile=Optimierung_in.rtf --outputfile=!Optimierung_out.rtf --optimize --short-tokens --compress=9 --filter=f
Here some optimizations (see respective parameter) are carried out and no field contents are mixed in.
The use of this parameter together with optimization parameters is demonstrated in the usage example Gap Text.
In the usage example Templates, the parameter is used together with --field-results.
6.31. Parameter --fonts
With the --fonts parameter, optimizations performed for font tables in the header of the RTF document can be switched off optionally.
Syntax
--fonts=<Option>
<Option>: keep, optimize, expand oder adjust
Description
Every RTF document contains font tables in the header. Therefore CIB has to spend merge time for matching due to insertions or for optimization. With the parameter --fonts these optimizations can optionally be switched off. The default is adjust. Das bezieht sich auch auf den gesamten Kopf.
The following values are <Option> :
|
Option |
Description |
|
keep |
The main font table remains unchanged, although inserted text templates contain additional fonts. Unused fonts are not removed. |
|
optimize |
The main font table is not extended. Unused fonts are removed. |
|
expand |
The main font table is extended by the fonts used in inserted text templates. Unused fonts are not removed. |
|
adjust |
Standard setting. The main font table is extended by the fonts used in inserted text templates. Unused fonts are removed. |
Example
--fonts=keep
Although inserted text templates contain additional fonts, these are not included in the main font table. Unused fonts are not removed. This is useful, for example, if a document is to be printed but the printer does not know all the fonts used.
The usage of the parameter is demonstrated in the example Templates.6.32. Parameter --headerfile
[--header/-h]
The --headerfile parameter can be used for data supply with XML. It points to the set data file.
Syntax
--headerfile=<Kopfsatzdatenquelle>
Description
If --headerfile is used in combination with the --multidatafile parameter, --datafile specifies the XPath to the multi-node. Usage of this parameter with a CSV data supply is not recommended.
Example Multi control file from XML
--headerfile=XML:Daten_mitAlias.xml --datafile=/root/multi --multidatafile
XML-Datei:
<root>
<multi>
<Kunden>XML:$(this);/root/data/Kunden/Kunde</Kunden>
<Einzelposten>XML:$(this);/root/data/Posten/Einzelposten</Einzelposten>
</multi>
<data>
<Kunden> <Kunde>
<Vorname>Franz</Vorname> <Name>Meier</Name>
<Strasse>Teststr. 4</Strasse>
<PLZ>12345</PLZ> <Ort>Musterdorf</Ort>
<Geschlecht>M</Geschlecht>
<KundenNr>9898989</KundenNr> <AuftragsNr>111111-2</AuftragsNr>
<Betrag>999</Betrag>
</Kunde>
weitere Kunden ......
</Kunden>
<Posten>
<Einzelposten>
<KundeAuftragsNr>111111-2</KundeAuftragsNr> <Bezeichnung>Artikel1</Bezeichnung>
<Betrag>999</Betrag> </Einzelposten>
weitere Einzelposten....
</Posten>
</data>
</root>
The multi-nodes are located in the file Data_withAlias.xml. The alias names result from the node name (customers, line items), which are defined with the specified XPath. The alias definitions are the node contents (XML:$(this);/root/data/customers/customer, XML:$(this);/root/data/items/single item). The special file name XML:$(this) points to the current file.
The use of this parameter will be described in detail in the usage example Serial Letter.
6.33. Parameter --help
[-?]
The --help parameter shows the help page (e.g. in log files).
Syntax
--help
Description
This parameter is used to output the automatic program help. This is an up-to-date short overview of all call parameters available in the version used.
If you also specify the log file parameter, the help is redirected to a file. Output to the console is not possible on Windows.
Description: CIB merge as programm
cibmrg32 --logfile=!hilfe.txt --help
The help is redirected to the file hilfe.txt. An excerpt from this help output can be found in the usage example Gap Text.
6.34. Parameter --inline-is-not-this
[--inline-is-not-this]
(from CIB merge 3.9.190)
By usage of the parameter "--inline-is-not-this" the behavior of CIB merge versions older than 3.9.166 concerning $(inline) can be restored.
Syntax
--inline-is-not-this
Description
Up to CIB merge version 3.9.165 the identifier $(inline) was used internally, i.e. a context was created. From CIB merge version 3.9.166 the $(inline) is replaced by the actual file name.
This means that constructs with "--directory-read=inline=<filename>" ($(inline) is redirected to a file) and at the same time "REF "DAT:XML:$(inline);relative/path" " no longer work because there is no context for relative XPATH expressions. You would have to work with absolute XPATH commands.
By using the parameter "--inline-is-not-this" a context is created internally and thus the usage of relative XPATH commands is possible.6.35. Parameter --html-switches
[--html/-s]
With the parameter --html-switches, CIB merge also supports extended REF statements that contain additional switches for the output of forms with CIB format/html.
Syntax
--html-switches
Description
CIB merge understands by default only the switches defined in MS Word. With the parameter --html-switches the additional switches for the output of forms are also interpreted. A specification of these additional switches can be found in the CIB format help, which you can get from the contact addresses or under http://www.cib.de under Support à Documentation.
Example
--html-switches
The parameter causes CIB merge to understand the following additional switch, for example.
{REF \* <cib-formfield type="text" info="name" testvalue="Max" />}
With CIB format/html this results in a single-line text field.
The usage of the parameter is demonstrated in the use case example Gap Text.
6.36. Parameter --inputfile
[--input/-i]
The input file is specified with the parameter--inputfile. If there are several modules, the root module must be specified there.
Syntax
--inputfile=<Inputfile>
Example
--inputfile=Anschreiben_in.rtf
The input file letter_in.rtf will be searched in the current directory.
The usage of the parameter is demonstrated in the use case example Gap Text.
Nore
Do not specify the path for the root module with --inputfile, but separately with --source-directory. In this way, the included modules are also found automatically in this directory, absolute path specifications are no longer necessary for the RTF modules.
This is demonstrated in the example Templates.
6.37. Parameter --input-language
The parameter --input-language determines the country setting for the switch “numeric format” (\#)("numerisches Format”).
Syntax
--input-language=<Sprache>
<Sprache>: englisch/english oder german/deutsch
Description
Currently there are the valid values “English“/“englisch“ and “German“/“deutsch“. Default is ”German“. If the value is set to “German”, CIB merge interprets dots in the number format specification as an instruction to structure the number to be output with 1000 dots or with substitute characters of the set output language. Commas are interpreted as subdivisions between places before and after the decimal point. The character that matches the set output language is also output here. If the value is set to "English", dots and commas are interpreted in reverse. Nevertheless, the output is still in the output language.
The numbers must be specified in German in the CSV file. They are written in {=...} fields only understanding them in German. Likewise, the parser of the switch \# expects that the field result contains the number in German before using the switch.
Examples
- English RTF with English formatting
--input-language=english
The cover letter is written in English and therefore the specification of the number format. This fact is specified using the parameter --input-language.
This is demonstrated in the use case example Gap Text.
- Calculation examples
--input-language=german
There is the following statement in an RTF document:
{=1234 + 1 \# #.####0,00€}
Result: 1.235,00€
The instruction
{=12,34 + 1 \# #.####0,00€}
delivers the result: 13,34€
--input-language=english
There is the following statement in an RTF document:
{=1234 + 1 \# #,####0.00€}
Result: 1.235,00€
The instruction
{=12,34 + 1 \# #,####0.00€}
delivers the result: 1.334,00€
The reason for the different result from the German is the interpretation of the separators in English:
Thousands separator comma and decimal point
6.38. Parameter --intermediatefile
[--intermediate]
The --intermediatefile parameter allows intermediate results to be stored in a file or in memory.
Syntax
--intermediatefile=<String>
<String>: RAM, - oder <Dateiname>
Description
By specifying RAM as intermediate result file, no file is created on the file system. This is useful if no (write) access to the file system is possible on a system. Writing an intermediate file may take a lot of time, which can be saved by using this parameter.
Possible values for <String> are:
|
String |
Description |
|
RAM |
Writes intermediate results to memory. No intermediate results are written to a file on the file system. |
|
<filename> |
Writes intermediate results in the file „<filename>.rtf“. |
|
- |
Explicitly deactivates the intermediate results per parameter. |
Example
--intermediatefile=Zwischenergebnis
The parameter --intermediatefile writes the intermediate result to the file intermediatefile.rtf .
Note
Alternatively, the file for the intermediate results can be specified via the environment variable "CIB_MRGINTERMEDIATE".
The parameter can be set for all merge processes using the "AUTOSTART" functionality (from Merge 3.9.104 and 3.8.130). For this purpose, the "AUTOSTART" parameter file can be patched directly into the binary file via hex editor or the environment variable "CIB_MRGAUTOSTART" can be set with the parameter file name.
6.39. Parameter --keep-fields
[-k]
The --keep-fields parameter continues the mixing process, even if not all fields can be filled using the data supply.
Syntax
--keep-fields=<Option>
<Option>: unresolved-ref, unresolved-ref-as-formfield, all oder none
Description
If not all fields can be filled during the data supply (information is not yet available), it is possible to tell CIB merge to skip these fields without aborting the merge process using the parameter --keep-fields.
Possible values <Option> are:
|
Option |
Description |
|
unresolved-ref |
all unsupplied ref fields remain in the output file |
|
unresolved-ref-as-formfield |
all unsupplied ref fields are replaced by {\rtf...formtext...} |
|
all |
Default value, all fields are kept in the output file, for fields supplied with data the result is filled accordingly. |
|
none |
no keep |
Example
--logfile=!cibmerge_Bausteine_KeepFields.log --target-directory=csv --source-directory=..\templates --inputfile=wurzelbaustein.rtf --outputfile=!..\result\KeepFields_out.rtf --datafile=multi_undef.csv --multidatafile --charformat --keep-fields=unresolved-ref
Here, the variable kont_kontoart is used in one of the RTF modules. However, this variable is not supplied from the data sources. With the parameter --keep-fields=unresolved-ref the mixing process is continued, the REF field for kont_kontoart remains in the output file KeepFields_out.rtf.
The usage of the parameter is explained in the example Templates.
Note:
If CIB merge writes a field as such (without merging the data) because of the parameter keep or because of the switch \* LEAVE (LASSEN), a textual error message appears in the logfile. This action is not considered an error and therefore does not generate an error return value.
(From CIB merge version 3.9.181)
When controlling via field switches, there are other possibilities besides \* LEAVE (LASSEN):
\*keepalways: This field statement always remains in the output document.
\*keepuntilresolved: This field statement remains in the output document until it is filled.
Hint:
As --keep-fields=unresolved-ref, this parameter is perfectly suited for realizing a residual data acquisition with the CIB office modules. Ask the CIB support for further information for your use case.
6.40. Parameter --keep-refs-if-in-list
(From CIB merge version 3.9.186)
The --keep-refs-if-in-list parameter can be used to set the keep switch externally for the specified fields.
Syntax
--keep-refs-if-in-list=<Variable>|<Variable-List>
<Variable-List>=<Varable>;<Varable>;…
Description
The --keep-refs-if-in-list parameter can be used to pass a single or a list of fields to the CIB merge for which a keep switch is to be set. These REF fields are left in the merged document, a possible variable value is stored in the fieldresult. If a REF field occurs more than once in an RTF, all of them are retained in the output.
Keep switches for these fields already contained in the RTF are not affected and have priority.6.41. Parameter --LicenseCompany
Name of the licensee
for the function(s) of the CIB merge to be activated in connection with the
LicenseKey parameter.
Syntax
--LicenseCompany"=<Name>6.42. Parameter --LicenseKey
License key, which in conjunction with the correct licensee unlocks licensed function(s).
Syntax
--LicenseKey=4e4e-c1c1-123456786.43. Parameter --lists
The --lists parameter can be used to disable optimizations that are performed for list tables in the header of the RTF document.
Syntax
--lists=<Option>
<Option>: keep, optimize, expand oder adjust
Description
Every RTF document contains list tables
(\listtable, \listoverridetable) in its header. When processing these tables,
CIB has to spend merge time for insertion matching and optimization.
With the parameter --lists these optimizations can be switched off.
The following values are possible for <Option> :
|
Option |
Description |
|
keep |
The list table of the root document is copied unchanged to the output even if inserted text templates contain additional lists. Unused lists are not removed. |
|
optimize |
The list table of the root document is not extended by list tables from inserted text templates. Unused lists are removed. |
|
expand |
The list table of the root document is extended by list tables from inserted text templates. Unused lists are not removed. |
|
adjust |
The list table of the root document is extended by list tables from inserted text templates. Unused lists are removed. (default) |
|
NEWLISTID |
The list table contains new list IDs in the merged document in the result document. It allows to create independent and non-continuous lists if there are multiple includes of a file. |
„Important Note“
NEWLISTID is a field switch and this is usage when the same file is included in multiple copies.
Example: {INCLUDETEXT "new1.rtf" \* NEWLISTID}
Version 3.13
Attention:
This parameter depends on the parameter "--replace-header".
"replace-header=never"
No control possibility of the handling of the list tables. The behavior is the
same as with "lists=keep".
"replace-header=always"
(default value) Here the root document is always extended by list tables from
inserted text templates. Only optimization and non-optimization is
distinguished.
This means that "lists=keep" is treated like "lists=expand" (no optimization) and "lists=optimize" like "lists=adjust" (optimization).
"--replace-header=auto"
Only in this setting all 4 variants of the "-lists" parameter are executed as described above.
Example
--lists=adjust
Here the list table is to be extended by the lists used in the text templates. Unused lists shall be removed. Thus, the usage lists are available again for later editing in MS Word.
This parameter is demonstrated in the use case example Templates.
6.44. Parameter --logfile
[--log/-l]
The --logfile parameter sets the file name and path for the error log file that CIB merge writes for each merge process.
Syntax
--logfile=<Fehlerprotokolldatei>
Description
With --logfile=!<Error log file> an already existing error log file is overwritten, with --logfile=+<Error log file> the current entries are simply appended to the file. If no error occurs, an empty error file is written.
Example
--logfile=!Komma_log.log
A possibly already existing file Comma_log.log in the current directory is overwritten.
The usage of the parameter is illustrated in the use case example Gap Text.
Note
It is recommended to write the parameter --logfile in the first line of the parameter file. This will already log errors in the parameter file.
From CIB merge version 3.9.x on, --logfile can be scaled additionally with --verbose. For details of --logfile and --verbose see chapter Error log file. Please also refer to the book "CIB merge Error Handling" for further information about trace options and program return values.
6.45. Parameter -m
The parameter -m<text> instructs CIB merge to output a specified <text> in the message/error log file.
Syntax
-m<Text>
Description
The parameter -m<Text> enables the insertion of self-defined texts into the message file. With -m@ CIB merge automatically outputs the set parameters for input and output file names.
Example
--logfile=!Komma_log.log --inputfile=Anschreiben_in.rtf --outputfile=!Komma_out.rtf --datafile=Adresse_Komma.csv -m -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@
The text specified after -m is written to the log file. With -m@ the names of the input and output files are output.
An excerpt from the log file can be found in the Gap Text application example.
Note
If errors occur in the merge process, they are output after the messages --m.
The output of the program version of CIB merge is controlled by the parameter --version.
6.46. Parameter -- max-executiontime
(from CIB merge version 3.10.3)
This parameter limits the maximum execution time.
Syntax
-- max-executiontime=[#milliseconds]
Description
This parameter sets the maximum execution time in milliseconds. As soon as this value is exceeded, CIB merge stops with error 821.
If this value is 0 (zero) or not set, the execution time is unlimited.
This parameter is used to avoid risks that can arise from endless loops. The following field combination is an example of such a loop:
{ IF {MERGEREC \* keepalways} <> "{REF value}" \* SOLANGE}6.47. Parameter --maxOutputSize
(from CIB merge version 3.9.174)
The maxOutputSize parameter sets the maximum allowed size for the entire serial letter in the "serialletter" case.
Syntax
--maxOutputSize=[#bytes]
Description
This parameter is a cancellation criterion for serial letters created with CIB merge. If the mail merge exceeds the maximum size, CIB merge will acknowledge this with a return code 818.
This allows the user to make sure that the generation (which usually happens automatically and without human control) is aborted if there is unwanted behavior in the file size range.
6.48. Parameter --maxSingleSize
(from CIB merge version 3.9.174)
The parameter maxSingleSize sets the maximum allowed size for a single document in the "serialletter" case.Syntax
--maxSingleSize=[#bytes]
Description
This parameter is an abort criterion for merge letters created with CIB merge. If a single document of a mail merge letter is larger than the set maximum size, CIB merge acknowledges this with a return code 817.
This allows the user to make sure that the creation (which usually happens automatically and without human control) is aborted if unwanted behavior in the file size range occurs.
6.49. Parameter --merge
[-@[<Ziffer>]]
A simple --merge as argument makes CIB merge start mixing immediately and use all arguments, which were used before.
Syntax
--merge
or
--merge=<Ziffer>
Description
With this call parameter, several jobs can be stored one after the other in a parameter file, each of which is processed separately.
Note:
An already set parameter is valid until a new value is assigned to it.
If not all data records/variables in the involved data files have been processed, CIB merge interprets the merge process as a mail merge, inserts a section change into the target document, and merges further starting from the root document.
In contrast, a --merge=1 is executed as a single merge run and ends at the end of the RTF text templates, no matter how many supplied data are still untouched. The number specifies how many data sets are passed through, thus limiting the merge to a certain number of data sets.Examples
--merge=1
Here a single merge run is executed, i.e. the result RTF contains only the data from the first record.
--merge=3
The result is an RTF document with the first three data sets, even if the data sources contain more than three data sets.
The usage of this parameter is demonstrated in the use case example Serial Letter.
Note:
If the parameters are transferred to CIB merge in a parameter file, only the parameters placed before the --merge parameter are evaluated.6.50. Parameter --multidatafile
[--meta/--metadatafile/--multi/-c]
If a multi-controller file/multi-CSV file is used as data source, the parameter --multidatafile must be set additionally.
Syntax
--multidatafile
Description
The parameter --multidatafile indicates that the data file specified with the parameter --datafile contains further data files.
Example
- Parameter file with multi control files from multi-CSV files
--datafile=multi.csv --multidatafile
The parameter --datafile defines a multi-CSV file. The aliases are defined in the first line of the CSV file, all other lines are the alias definitions.
The usage of the parameter in connection with CSV files is demonstrated in the use case example Serial Letter.
Note:
When using multi-CSV files, the --headerfile parameter is not used.
- Parameter file with multi control files from two separated CSV files
--datafile=Daten.csv
--multidatafile
--headerfile=Alias.csv
Alias CSV file:
Address;License information
Data CSV file:
Adress.csv;LicenseInfo.csv
Note:
In this example, the alias names and alias definitions are stored separately in two CSV files. To specify the CSV file for the alias names, the --headerfile parameter is used. The alias definitions are located in the CSV file which is set with the parameter --datafile. Each line represents a new definition (data set).
- Parameter file with multi control files from XML file
--headerfile=XML:Daten_mitAlias.xml --datafile=/root/multi --multidatafile
The --headerfile parameter defines the XML file. The aliases result from the node names in the XML file, which are defined with the specified XPath. The alias definitions are the node contents.
The usage of the parameter in connection with XML files is demonstrated in the use case example Serial Letter.6.51. Parameter --next-mode
[--next-modus/--next]
The --next-mode parameter controls the behavior of the {NEXT} command and affects variables that are present in one data set but no longer exist in the next one.
Syntax
--next-mode=<Option>
<Option>: delete, empty oder keep
Description
Variables that are present in one data set but no longer exist in the next one can be deleted, cleared or retained using the --next-mode parameter.
Possible values for <Option> are:
|
Option |
Description |
|
delete |
The variables are deleted and are therefore no longer defined. |
|
empty |
The variables are cleared. These are then still defined but empty like „“ |
|
keep |
The variables are kept and the values remain unchanged. |
Example
--next-mode=delete
If a variable is no longer present in the next record (e.g. missing node in the XML), this variable is deleted, which then leads to an error. This is desired so that the error does not remain undetected by simply leaving out the missing value.
The usage of this parameter is demonstrated in the use case example Serial Letter.
6.52. Parameter --old-compare
With this parameter the new interpretation of conditions can be switched off.
Syntax
--old-compare=<Option>
--alter-Vergleich=<Option>
<Option>: +, - oder „“
Description
With newer versions, MS-Office has an extended range of functions in the automatic comparison of data types. This has required a renewal in CIB merge (from version 3.8.126). Customers who wish to use an older (conservative) comparison procedure can do so by using the --old-compare call parameter.
Switching off the new interpretation of conditions can be controlled by the --old-compare parameter. The parameter can be set for all merge processes using the "AUTOSTART" functionality (from CIB merge versions 3.9.104 and 3.8.130). The "AUTOSTART" - parameter file can be patched directly into the binary file via hex editor or the environment variable "CIB_MRGAUTOSTART" can be set with the parameter file name.
Spezifikation
Der Parameter heißt „OLD-COMPARE“. Alternativ kann auch „ALTER-VERGLEICH“ angegeben werden. Wie bei allen Merge - Parametern wird die Groß-/Kleinschreibung nicht berücksichtigt.
Possible values for <Option> are:
|
Option |
Description |
|
+ |
CIB merge interprets the conditions as in previous versions (until 3.9.127 / 3.8.126): Both sides of a comparison (condition) have a "data type", if the type does not match, the result is "false". No evaluations are made, wildcards are not allowed. |
|
- |
Default setting. CIB merge interprets the conditions according to the current comparison method. The data type used on the left side indicates how the comparison will be done: · if a date is on the left, a date will be compared · if a number is on the left, there will be assumed a number on the right as well ·
evaluations can
be made · wildcards can be used |
|
„“ |
Same as Option „+“. |
Example
--old-compare=+
CIB merge interprets the conditions according to the old comparison method.
„“ ist gleich „+“. Die Voreinstellung ist „-“
Wenn „+“ eingestellt ist, interpretiert CIB merge Bedingungen, wie in den vergangenen Versionen (bis 3.9.127 bzw. 3.8.126). Die Erweiterung wird in CIB merge 3.8 und 3.9 aufgenommen.
|
{compare …} |
Explanation |
Evaluation without switch |
Evaluation with switch --old-compare=+ |
|
1.1.2004 = 01.01.2004 |
Comparison as calendar date. |
1[1] |
1 |
|
„1.1.2004“ = 01.01.2004 |
Comparison as text, because there are quotation marks on the left. |
0[2] |
0 |
|
1.1.2004 = „01.01.2004“ |
Comparison as date, because the right quotation marks do not bother. |
1 |
0 |
|
1 = 01 |
Comparison as number. |
1 |
1 |
|
„1“ = 01 |
Comparison as text, because there are quotation marks on the left. |
0 |
0 |
|
1 = „01“ |
Comparison as number, because the right quotation marks do not bother. |
1 |
0 |
|
Amount < „10.000 €“ |
Comparison as text, because there are quotation marks on the right. |
1 |
1 |
|
Height> 3,5m |
Comparison as number with 3,5. |
1 |
1 |
|
Amount < EUR10000 |
Comparison as text, because 10000 is not at the beginning. |
1 |
1 |
|
Amount < „EUR 10000“ |
Comparison as text, because 10000 is not at the beginning. |
1 |
1 |
|
1.1.2004 = 1 |
Comparison as number because no date was recognized on the right. If no date is recognized on the right side, the system tries to interpret both sides as a number. |
0 |
0 |
|
1+1 = 2 |
Comparison as number, where the expression 1+1 is not evaluated. (Thus: 1 = 2) |
1 |
0 |
|
„Test Wild“ = „*W??d” |
„*“ and „?“are interpreted as ordinary characters (i.e. returns 0) |
1 |
0 |
6.53. Parameter --optimize
The parameter --optimize removes the superfluous switches inserted by MS Word.
Syntax
--optimize
Description
When inserting or reformatting REF fields, MS Word sometimes inserts a switch \* FORMATBINDEN or \* MERGEFORMAT, which makes the raw texts less readable and leads to performance disadvantages in CIB merge. CIB merge removes these superfluous switches with the –optimize parameter.
Example
--inputfile=Optimierung_in.rtf --outputfile=!Optimierung_out.rtf --optimize --filter=f
Here all MERGEFORMAT switches are removed from the RTF optimization_in.rtf without mixing in field results (--filter=f). The result letter_optimized does not contain such switches anymore.
The usage of this parameter together with other optimization parameters is described in the Gap Text example.
6.54. Parameter --outputfile
[--output/-o]
The --outputfile parameter specifies the output or result file.
Syntax
--outputfile=<Ausgabedatei>
Description
The call --outputfile=! overwrites an already existing output file, --outputfile=+ appends the output file to the already existing file and thus creates a MultiRTF file.
If no explicit path is given, the file is created in the working directory specified with --target-directory, without --target-directory the output file is stored in the current directory.
Example
- Creation of a single-RTF file
--outputfile=!Anschreiben_out.rtf
The file cover_letter_out.rtf is written to the current directory. The exclamation mark may overwrite an already existing file.
The usage of the parameter is described in the example Gap Text.
--outputfile=!..\result\Kontenuebersicht.rtf
The file account_overview.rtf is written in the result directory. The exclamation mark overwrites an existing file if necessary.
The usage of the parameter in this way is described in the application example Templates.
- Creation of a multi-RTF file
--logfile=!multirtf.log --outputfile=!multirtf.rtf --inputfile=input1.rtf -@1 -m@ --outputfile=+multirtf.rtf --inputfile=input2.rtf -@1 -m@ --inputfile=input3.rtf -@1 -mfertig.
This example creates a multi-RTF file from three RTF files and outputs the call parameters in each case. In the first merge process the multirtf.rtf is overwritten with --outputfile=!multirtf.rtf, then the other files are appended with --outputfile=+multirtf.rtf.
6.55. Parameter --output-language
This example creates a multi-RTF file from three RTF files and outputs the call parameters in each case. In the first merge process the multirtf.rtf is overwritten with --outputfile=!multirtf.rtf, then the other files are appended with --outputfile=+multirtf.rtf.
Syntax
--output-language=<Sprache>
or
--Ausgabesprache=<Sprache>
<Sprache>: english/englisch, french/franzoesisch, german/deutsch, spanish/spanisch, italian/italienisch, swiss/schweizerisch oder dutch/niederlaendisch
Description
The --output-language parameter affects only the output of the thousands and decimal separators and the weekdays as well as month names. The supply of the numbers is currently in German.
Ausgabesprache
Die Versorgung der Zahlen muss in deutschem Zahlenformat erfolgen.
Kalenderdaten müssen den Ländereinstellungen des aktuellen Benutzers des Systems entsprechend eingegeben werden. (Deutsch zum Beispiel 28.8.2001, US-englisch 8/28/2001)
Die Angabe der Schalter \# und \@ muss im Rtf auf englisch geschehen.
|
info |
Deutsche Installationen von Word tauschen in den \#-Formaten die Tausenderpunkte und Dezimalkommata gegen die englischen Kommata und Punkte. Man gibt also die Bilder in deutsch an, damit sie im rtf auf englisch stehen. |
Merge übersetzt intern wieder zurück. Aus \# #.###,00 macht Word also \# #,###.00 und Merge wieder \# #.###,00. Kommt die Formatierung aus Steuerdaten, bleibt sie immer #.###,00.
Angaben hinter \@ werden seit Word 2000 nicht mehr übersetzt. (Vorher schon, daher hängt hier Merges Verhalten vom Parameter „word-version“ ab.)
Vor Word 2000 musste man also zum Beispiel zur Ausgabe eines vollen Wochentages \@ tttt schreiben. Seit Word 2000 jedoch \@ dddd. Im Rtf landet jeweils \@ dddd und Merge macht schließlich intern \@ tttt daraus.
The output of fields without \# and \@ will not be affected, as for instance {Aktualdat/Time/Date} or {=…}.
Possible values for <language> are:
The output of the thousand and decimal separators affects for example 1234567 with \# #.###,00 as:
|
Language |
Output |
||
|
|
Number |
Date |
|
|
English |
englisch |
1,234,567.00 |
07/20/2007 |
|
French |
franzoesisch |
1 234 567,00 |
20/07/2007 |
|
German |
deutsch |
1.234.567,00 |
20.07.2007 |
|
Spanish |
spanisch |
1.234.567,00 |
20/07/2007 |
|
Italian |
italienisch |
1.234.567,00 |
20/07/2007 |
|
Swiss |
schweizerisch |
1'234'567.00 |
20.07.2007 |
|
Dutch |
niederlaendisch |
1.234.567,00 |
20-07-2007 |
Default is German. If you omit the language behind the switch, the program will be reset to German output.
The setting applies to all merge processes (-@/-@1) after „output-language“, until the parameters are completely processed or "output-language" is changed.
The output of weekdays and month names is done accordingly. For example, 28.08.2001 with the format \@ "dddd, d. MMMM yyyyy" becomes the result "Dienstag, 28. August 2001" if the output language is set to German. For English, the result is "Monday, August 28, 2001".
(For a "real" English date you have to change the switch further, so that the order and fill characters correspond to the respective country-specific output.)Example
--output-language=english
The output format is English. The output of dates and number formats is in English format. The parameter is described in the application example Gap Text.
6.56. Parameter --parameterfile
[--parameter/-@<Parameterdatei>]
With the --parameterfile parameter, the name of the parameter file is specified. A mixing process is started, which uses the set parameter file.
Syntax
--parameterfile=<Parameterdatei>
Description
The --parameterfile parameter specifies a file name that is interpreted as a parameter file. CIB merge then expects this parameter file to contain all call parameters relevant for the merge process.
Example (command in the command line)
cibmrg32.exe --parameterfile=Komma_par.par
All call parameters relevant for the merge process can be found in the file comma_par.par.
The usage of this parameter is described in the application example Gap Text.
Note
The parameter can only be used in combination with the call of the Merge-EXE via command line. Any number of call parameters can be placed before and after it and any number of parameter files can be placed at any position between the other parameters. Further parameter files can also be called from parameter files. However, care must be taken to avoid infinite recursions.
6.57. Parameter --prefix-delimiter
The parameter --prefix-delimiter defines a separator between alias and variable name and enables the prefix mechanism
Syntax
--prefix-delimiter=<Trennzeichen>
Description
By setting the --prefix-delimiter parameter, the delimiter is specified which, together with the alias, is placed in front of the variables in the raw text. This is useful for instance when using multiple nodes to keep the variables unique. The default value is “.“ .
Example
--headerfile=XML:Daten_mitAlias.xml --datafile=/root/multi --multidatafile --prefix-delimiter
XML file:
<root> <multi> <Kunden>XML:$(this);/root/data/Kunden/Kunde</Kunden> <Einzelposten>XML:$(this);/root/data/Posten/Einzelposten</Einzelposten> </multi> <data> <Kunden> <Kunde> <Vorname>Franz</Vorname> <Name>Meier</Name> <Strasse>Teststr. 4</Strasse> <PLZ>12345</PLZ> <Ort>Musterdorf</Ort> <Geschlecht>M</Geschlecht> <KundenNr>9898989</KundenNr> <AuftragsNr>111111-2</AuftragsNr> <Betrag>999</Betrag> </Kunde> weitere Kunden ...... </Kunden> <Posten> <Einzelposten> <KundeAuftragsNr>111111-2</KundeAuftragsNr> <Bezeichnung>Artikel1</Bezeichnung> <Betrag>999</Betrag> </Einzelposten> weitere Einzelposten.... </Posten> </data> </root>
A "." is defined as separator (default). For raw texts, all accesses to variable names must be supplemented by the alias name and the separator. This makes the variable amount unique, for example. Extract from the raw text:
{REF customers.Amount}
{REF single item.Amount}
The parameter is used in the application example Serial Letter.
6.58. Parameter --remove-hidden-text
The -remove-hidden-text parameter completely removes all content marked as "hidden" from the document.
Syntax
--remove-hidden-text
Description
By setting the -remove-hidden-text parameter, the text marked as "Hidden" is removed. Other contents are processed without changes, depending on other standard parameters.
Example
--remove-hidden-text
-iInputfile.rtf
-o!Outputfile.rtf
-ff
6.59. Parameter --replace-color
The parameter --replace-color is used to replace colours in RRGGBB format.
Syntax
--replace-colorDescription
The colour replacement is done with the parameter --replace-color=xxxxxx=yyyy, where xxxxxx is the hexidecimal representation of the source colour to be replaced in RRGGBB format (ff0000 is red, ffffff is white, etc.) and yyyyyy is the new colour in the same format. There can be as many such parameter pairs as required, with no restrictions.
For batch processing by CIB merge, it is possible to reset all marked replacements by specifying the --replace-color parameter without additional data.
Example
--replace-color=ff0000=00ff00
This replaces red with green. Mit dem Parameter “—prefix-delimiter” wird der Präfix “sample.” aktiviert.
6.60. Parameter --replace-header
The --replace-header parameter is used to optionally
disable RTF output header rewriting.
Syntax
--replace-header=<Option>
<Option>: always, never oder automatic
Description
The header of the RTF output is rewritten at the end. Because of the color, list and font tables in the RTF output header, CIB merge has to spend time for insertion matching or optimization. But not every user is interested in this adjustment or optimization. Therefore they can be switched off optionally. This also applies to the entire header.
Possible values for <Option> are:
|
Option |
Description |
|
always |
The header of the RTF output is always written reduced at the beginning and already at the beginning it is known that the header is rewritten at the end. But if the RTF header would not be written at all at the beginning, the document would be incomplete and not readable with MS Word. The font tables as well as the unspecified part of the header are not output. The table lists of the include files are ignored. |
|
never |
The header of the RTF output is never replaced. Wird er am Anfang trotzdem reduziert geschrieben? |
|
automatic |
The header of the RTF output is replaced if one of the following conditions applies:
--lists=optimize or expand
--lists=optimize or expand.
--fonts=expand or adjust.
--fonts=optimize or adjust.
--colors=expand or optimize or minimal.
--colors=optimize or minimal. |
Example
--replace-header=automatic
The usage of this parameter together with --fonts, --colors and --lists is demonstrated in the application example Templates.
6.61. Parameter --serialletter
This parameter changes the behavior when writing multi-RTF files.
Syntax
--serialletter=<Option>
<Option>: auto oder multi
Description
Possible values for <Option> are:
|
Option |
Description |
|
auto |
Default value, here a section break is inserted after each data set and all data sets are in one RTF document. |
|
multi |
For each data set a complete RTF document is written into a multi-RTF. |
Example
--serialletter=multi --outputfile=!Serialletter_out.rtf
The result document Serialletter_out.rtf is a multi-RTF that contains all data sets.
The usage of the parameter is described in the example Serial Letter.
6.62. Parameter --set
[-:]
Sets a variable that can be used in RTF text templates. If this variable is also available in the data supply (CSV, XML), this value from the supplied data stream is used with priority.
Syntax
--set=Variable=Wert
Example
--set=XmlDateiname=Daten.xml
The variable "XmlFilename" is set to the value "data.xml". This variable can be queried in the RTF-modules.
The usage of this parameter is described in the example Serial Letter.
Note:
This parameter can also be used several times for a merge call.Calling examples
- CIB runshell
Cibrsh .....-m–set=Vorname=Hans -m–set=Nachname2=Wurst.......
- CIB merge with parameter file
...
# setze Vorname auf Hans
--set=Vorname=Hans
# setze Nachname auf Wurst
--set=Nachname=Wurst
...
- CIB merge from JAVA
...
t_MergeJob.setProperty("--set=Vorname=", "Hans");
t_MergeJob.setProperty("--set=Nachname=", "Wurst")
...
6.63. Parameter --short-tokens
[--rta/--cibrtf]
With this parameter CIB merge creates a target file in a format with shortened RTF tokens (CIBrtf).
Syntax
--short-tokens
Description
The shortened RTF tokens created with the --short-tokens parameter reduce the file size significantly. By using such optimized CIBrtf files, the performance of CIB format and CIB merge can be optimized.
Further processing of this target document is possible with CIB format/view and with CIB merge from version 3.8.106. CIBrtf is CIB specific and cannot be processed by third-party products, but CIB merge can read it in and output it as RTF without --short-tokens.Example
--inputfile=Optimierung_in.rtf --outputfile=!Optimierung_out.rtf --short-tokens --filter=f
CIB merge does not merge field contents (--filter=f) and writes an output file with shortened CIBrtf tokens (CIBRtf). The shortened RTF commands in the output result in a smaller result file compared to the RTF.
The usage of this parameter together with other optimization parameters is described in the Gap Text example.
Disadvantage:
The RTF format can only be processed by the CIB format/output component.
6.64. Parameter --source-directory
[--source/-a]
The --source-directory parameter sets a separate directory for the RTF root document and the RTF components.
Syntax
--source-directory=<Verzeichnis>
Description
The --source-directory parameter sets the directory where the RTF root document and RTF templates are expected. You can also specify a list of working directories. The individual specifications are separated by semicolons. For each usage a search is started and the first found file is used. With the parameter --source-directory a path can be specified absolute or relative to the parameter --target-directory. The parameter --target-directory must therefore be set before the parameter --source-directory. This allows e.g. in multithreaded applications to specify the same source directory --source-directory for each thread, but different output/log directories --target-directory. If no source directory is specified, the output directory is also the source directory.
Exception:
If files have their own qualified path in their name, the parameters --source-directory and --target-directory are ignored for these files.
Example of an optimal parameter file with --target-directory and --source-directory:
--target-directory=csv --source-directory=..\templates --inputfile=wurzelbaustein.rtf --outputfile=!..\result\Kontenuebersicht.rtf --datafile=multi.csv
With --source-directory you set the directory where all RTF blocks can be found. Thus an explicit path specification is not necessary with --inputfile. --source-directory is specified relative to --target-directory.
The usage of the parameter is demonstrated in the application example Templates.
6.65. Parameter --statistics
The parameter --statistics returns the number of created documents in a specified file.
Syntax
--statistics=<Filename>
Example
--statistics=!count.txt
The number of documents generated by CIB merge are output in the file count.txt.
For example, in the application example mail merge 3 documents are generated. The file count.txt contains the following content after the merge process:
GeneratedDocumentCount=3
6.66. Parameter --target-directory
[--target/-q]
The parameter--target-directory determines the directory for the data and output files.setzt das aktuelle Arbeitsverzeichnis, in dem CIB merge die übergebenen Dateien sucht.
Syntax
--target-directory=<Verzeichnis>
Description
In addition to the directory for the data and output files --target-directory, the --source-directory parameter can be used to specify a path where the root block and further RTF blocks can be searched.
--source-directory is relative to --target-directory, but can also be specified absolutely. So for multithreaded applications the same input directory --source-directory but different output/logdirectories --target-directory can be specified for each thread.
Example
--target-directory=csv
--datafile=multi.csv
--outputfile=!..\result\Kontenuebersicht.rtf
Here --target-directory is used to specify the directory for the CSV files, the output directory is set directly with --outputfile. Without explicit path specification with --outputfile, the result would also be written to --target-directory. The usage of the parameter is illustrated in the example Templates.
Note:
--target directory always sets the same --source directory, if --target directory comes after --source directory, the --source directory is overwritten.
6.67. Parameter --template-combine
(From CIB merge version 3.9.181)
The parameter "--template-combine" causes all {INCLUDETEXT} statements are resolved, but all other field statements remain unchanged.
Syntax
--template-combine
Description
This tells the merge process that only INCLUDETEXT statements are resolved. All other field statements remain unchanged. A large input document is generated from a document project with n templates.
6.68. Parameter --verbose
With --verbose you can determine the amount/type of error messages in the logfile.
Syntax
--verbose=<verbose-level>
<verbose-level>: 0-9
Description
<verbose-level> can take values between 0 and 9. 0 means, that no errors are given, 9 means, that also relevant subsequent errors are given.
The available verbosity levels can be found here. Please also note the error categories.
Example
--verbose=9+all+source6.69. Parameter --version
[-v]
With the parameter --version, CIB merge outputs the CIB merge program version in the message/log file.
Syntax
--version
Example
--logfile=!Komma_log.log --version
The log file contains error messages and an output of the CIB merge program version.
An excerpt of the contents of the log file can be found in the application example Gap Text.
6.71. Parameter --workingset-size
[--workingsetsize]
The --workingsetsize parameter sets the InitHeap and workingset size.
Syntax
--workingset-size=<min-Wert>;<max-Wert>
Description
Setting the InitHeap and Workingset size can improve the performance of CIB merge on some servers.
Alternatively this can be set via the environment variable "CIB_MRGWORKINGSETSIZE". The variable "WORKINGSETSIZE" can also be patched directly in the binary file using a HEX editor. The WorkingSet size defines the minimum and maximum size of the Windows Process-WorkingSet size. The minimum and maximum values are separated by a ";". (Both are required)
With the environment variable "CIB_MRGINITHEAPSIZE" the initial thread heap size in KByte can be set.
The initial heap size can also be patched in the binary file ("INITHEAPSIZE")
Patching comes before environment variable.
The extension is included in CIB merge 3.9. (Only for Windows)
Example
|
Setting |
Explanation |
|
--Workingset-Size= 504800;1413120 |
Sets the Windows process workingset size to a minimum of 504800 and a maximum of 1413120 (per parameter) |
|
CIB_MRGWORKINGSETSIZE= 504800;1413120 |
Sets the Windows process workingset size to a minimum of 504800 and a maximum of 1413120 ( per environment variable) |
|
CIB_MRGINITHEAPSIZE=400 |
Sets the init thread heap size to 400 KByte. (default is 300) |
Set the InitHeap and workingset size: Setting the InitHeap and workingset size can improve the performance of CIB merge on some servers. The optimal configuration depends on many parameters such as memory, network etc. Therefore the "best" setting cannot be determined for all systems. For the server in usage a possibly better setting can be determined by suitable tests. The parameter can be set for all merge processes using the "AUTOSTART" functionality (from CIB merge versions 3.9.104 and 3.8.130). For this purpose, the "AUTOSTART" parameter file can be patched directly into the binary file via HEX editor or the environment variable "CIB_MRGAUTOSTART" can be set with the parameter file name.
7. Special funcionality: Textcaching
CIB merge can output the result file not only in RTF format as a file on the hard disk. It can also use different parameters for optimization, compression and/or encryption of the result data stream.
- No matter which root is merged with, the include cache is effective regardless of the jobs that are sent within a merge call.
- The root is currently not included in the include cache yet. They include cache is only for includes.
Note for 2.: However, there has always been another optimization for the root: If you specify the -I parameter and mix it once, the root remains in memory until you specify -I again.
So if you mix many files with the same root directly after each other and specify -I only once, you will have the same cache effect.
Note for 1. and 2.: The optimization via the include cache is a trade-off for runtime at the expense of memory and functionality:
If you mix with root X, then for X the font tables, color tables etc. are changed (extended) with respect to the respective include. On the other hand, the font, color, etc. keys (\f12, \cf1...) for the includes are adjusted with respect to the current root and thus stored in the cache.
If the roots "fit together", then the colors, fonts etc. will be correct afterwards. If not, then not.
So to have absolute security, you have to mix documents with the same root one after the other to have the cache advantage and then empty the cache. After that you can mix with the next root, etc.
The cache can be cleared indirectly with one of the commands for controlling the behavior of the include with regard to fonts, colors, list tables, etc. For example, a single --replace-header is sufficient to clear the cache. (The default --replace-header=always is set, but it should be valid anyway).
Because of the last hint or rather because of the way the tables are merged from the header of the RTF, a root cache is mostly not useful and because of the necessary sorting of the requests by root not necessary.
8. Special funcionality: Result optimization, encryption and compression
CIB merge can output the result file not only in RTF format as a file on the hard disk. It can also use different parameters for optimization, compression and/or encryption of the result data stream.
The following table shows the compatibility of all possible combinations with the CIB office modules and third-party products
For details of the control with CIB merge see the corresponding parameters for optimization, encryption and compression.
|
Product |
CIB merge |
CIB format / view |
Third party products |
|||
|
Action |
Write |
Read |
Read |
Read |
||
|
|
|
MultiRTF |
|
|
|
|
|
CIB RTF output |
Yes |
Yes |
Yes *) |
Yes |
No |
|
|
Encrypt |
Yes |
Yes **) |
Yes |
Yes |
No |
|
|
Compress |
Yes |
Yes **) |
Yes **) |
Yes |
Yes, if ZLIB 1.1.3 format is supported |
|
|
Combination encrypt + compress |
Yes **) |
Yes **) |
Yes **) |
No (=bald, laut AE) |
No |
|
|
Combination |
Yes |
Yes **) |
Yes *) |
Yes |
No |
|
|
Combination |
Yes |
Yes **) |
Yes **) |
Yes |
No |
|
|
Combination |
Yes **) |
Yes **) |
Yes **) |
No (=bald, laut AE) |
No |
|
*) from version 3.8.106
**) from version 3.9.115
No encrypted, compressed or CIB RTF can be imported from control files and set variables.
9. Special funcionality: Mixing document properties
(from CIB merge Version 3.9.174)
In an RTF the document properties (Doc-Properties) can be set via the editor (e.g. MS-Word). Examples are author, title, department, project etc. Furthermore, there are also the so-called User-Properties. The CIB merge treats Doc-Properties and User-Properties the same way.
The command INCLUDETEXT in the raw RTF can be used to create a document hierarchy. Each of these RTFs can have its own document properties. The CIB merge merges this document hierarchy into a single output RTF.
The document properties of the output RTF are determined by the following rules:
Until CIB merge version 3.12.2:
- When merging, the last RTF overwrites the specifications of the previous one, i.e. it "wins" the lowest RTF in the hierarchy.
- Already occupied properties are not deleted by empty ones.
Example:
Starting from the call hierarchy
ROOT.rtf -> TEMPLATE1.rtf -> TEMPLATE2.rtf
with the following document properties of the individual documents:
ROOT.rtf: Title-R
/ Author-R / Project-R
TEMPLATE1.rtf: Title-1 / Project-1 / Storage-1
TEMPLATE2.rtf: Title-2 / Storage-2 / Department-2
the merged result document gets the following document properties:
Title-2 / Author-R / Project-1 / Storage-2 / Department-2
From CIB merge version 3.12.3:
- When merging, the document properties are "collected" in the merge order. Thus the root always has priority.
- Already used properties are not overwritten, only new properties are added.
Example:
Starting from the call hierarchy
ROOT.rtf -> TEMPLATE1.rtf -> TEMPLATE2.rtf
with the following document properties of the individual documents:
ROOT.rtf: Title-R
/ Author-R / Project-R
TEMPLATE1.rtf: Title-1 / Project-1 /
Storage-1
TEMPLATE2.rtf: Title-2 / Storage-2 / Department-2
the merged result document gets the following document properties:
Title-R / Author-R / Project-R / Storage-1 / Department-2
10. Use case examples
In this chapter the different call parameters are explained by means of illustrative examples. At the appropriate places, reference is made to the detailed parameter descriptions.
To test the following examples, the binaries must be stored in a directory, which should then be added to the PATH environment variable. To execute the examples from the command line, you must be in the respective directory. There is a batch executable file for each example.
At the time the application examples were developed, the following versions were used:
cibmrg32.dll, cibmrg32.exe: 3.9.171.0
CibJob32.dll: 1.4.20.0
CibChart.dll: 1.1.4.0
JComod.dll: 2.2.52.1
10.1. Use case example Gap Text
The following example is located in the subdirectory Lueckentext (gap text). Its usage is a cover letter, which is available as RTF. It contains variables that are to be filled from a data source. This is a CSV file with the data of the recipient. The result of the merge process is a payment reminder that contains the customer data from the CSV file.
Calling the CIB merge helpSimplest form of a merge process (IOD)
Calling single parameters via command line
Calling single parameters via JAVA
Calling single parameters via C++
Calling the parameter file via command line
the parameter file via JAVA
Optimizing raw texts before delivery
Calling the CIB merge help
The CIB merge help cannot be displayed on the console under Windows because it is a windowed application to display a progress dialog during the merge process (see parameter --dialog). To get an overview of all possible call parameters, the help can be output to a file. To do so, enter the following call in the command line, or execute the batch file hilfe.bat.
cibmrg32 --logfile=!help.txt --help
The help is redirected to the file help.txt and is structured as follows:
Usage of CIB merge:
>CIBMRG32 <Parameter1> <P2> ...
Each parameter should start with a start character from "-/".
Otherwise, the first parameters without a start character are assigned the parameter characters from "IODH" in sequence.
After evaluation of all parameters "/@" is executed automatically.
Parameter : Effect
Q<working directory> : sets the working directory (has to be at the beginning!)
A<template directory> : sets the template directory
I<input> : sets RTF input source
? : show help page
Further parameters
Simplest form of a merge process (IOD)
The simplest form of a merge process is to fill an input file with data and write the result to an output file. This can be specified using the individual parameters --inputfile (I), --outputfile (O) and --datafile (D). The following describes how these parameters can be specified on the command line. Furthermore, variants for control from JAVA and C++ are presented.
Calling single parameters via command line
To mix an input file with data and write it to an output file, a simple call on the command line is sufficient. The --inputfile call parameter is used to specify the file that serves as input file for the merge process. The parameter --datafile specifies the name of the data source and --outputfile specifies the output file.
The following call supplies the input file Anschreiben_in.rtf with the data from Adresse.csv (which is located in the same directory) and writes the result to the output file Anschreiben_out.rtf, overwriting any existing file.
cibmrg32.exe --Anschreiben_in.rtf --outputfile=!Anschreiben_out.rtf --datafile=adress.csv
If the order IODH (inputfile, outputfile, datafile, headerfile) is kept, the parameters can be omitted. The following call then leads to the same result (Anschreiben.bat):
cibmrg32.exe Anschreiben_in.rtf !Anschreiben_out.rtf Adresse.csv
Calling single parameters via JAVA
Instead of setting the parameters via the command line, the control can also be done via JAVA. The same result is achieved with the following JAVA code
(MergeEinzelneParameter.java) achieved:
Excerpt from MergeEinzelneParameter.java:
…
JCibMergeJob t_Job = new JCibMergeJob();
t_Job.initialize();
if (!t_Job.isInitialized())
{
// Fehler beim Initialisieren
System.err.println("Fehler beim
Initialisieren");
System.exit(1);
}
try
{
// Beteiligte Dateien für den
Mischlauf
t_Job.setProperty(ICibMergeJob.PROPERTY_INPUTFILE,
"Anschreiben_in.rtf");
t_Job.setProperty(ICibMergeJob.PROPERTY_OUTPUTFILE,
"Anschreiben_out.rtf");
t_Job.setProperty(ICibMergeJob.PROPERTY_DATAFILE,
"Adresse.csv");
//Job ausführen
t_Job.execute();
//Fehlerbehandlung
int t_Error =
((Integer)t_Job.getProperty(IComodJob.PROPERTY_ERROR)).intValue();
if (t_Error != 0)
{
// Fehler beim Ausführen des Jobs
String t_Errortext =
(String)t_Job.getProperty(IComodJob.PROPERTY_ERRORTEXT);
System.err.println("Fehler beim
Ausführen: "+t_Error+" "+t_Errortext);
}
}
finally
{
t_Job.terminate();
}
…
Here the job class is used for the usage of the CIB merge from Java. With the JCibMergeJob a mixed job from Java can be passed to the CIB merge. The job class first collects the parameters that are set with setProperty. CIB merge is then called with execute().
Calling single parameters via C++
If a control via C++ is desired, cibmerge(int argc, char *argv[]) usage is required. This way the desired parameters can be set. The directory C:\\comod\\, which contains the CIB modules, must be adapted accordingly. This directory is required for the initialization of CIB merge.
Excerpt MergeEinzelneParameter.cpp:
…
extern "C" const char *cibmerge_errormessage;
static char *test_arguments[]={"MergeEinzelneParameter", "--inputfile=Anschreiben_in.rtf", "--outputfile=!Anschreiben_out.rtf", "--datafile=Adresse.csv", 0};
int main(const unsigned int number_of_arguments, char *argument_vector[]) { if(!cibmerge_initialize("C:\\comod\\", 0)) cout << cibmerge_errormessage << endl;
int iReturn=0; iReturn = cibmerge(sizeof(test_arguments)/sizeof(*test_arguments) - 1, test_arguments); cout << "MergeEinzelneParameter Returnwert cibmerge: " << iReturn << endl;
if(!cibmerge_terminate()) cout << cibmerge_errormessage << endl; return 0; }
- Logging and usage of another separator in the data source
In the following, possible occurring errors are to be logged in a log file and in this file also contains messages as well as information about the program version used are to be output. Furthermore, the data source is structured in such a way that instead of the character ";" a comma is used as separator in the CSV file.
To realize this, additional call parameters must be considered during the merge process. This makes a call from the command line slightly confusing. In this case it is advisable to store the parameters in a parameter file. This parameter file can then be called via the command line. The variants how the parameter file can be executed via JAVA and C++ are also explained in the following.
Calling the parameter file via command line
The parameters required for this merge process are all located in the file Komma_par.par. If CIB merge is called from the command line, the parameter file is specified using the call parameter --parameterfile (Komma.bat):
cibmrg32.exe --parameterfile=Komma_par.par
All lines that do not begin with "--" or "-" in the parameter file are comments (parameters indented with spaces are also comments).
Content of the parameter file Komma_par.par:
Errors shall be logged--logfile=!Komma_log.log --versionInvolved files for the merge process
--inputfile=Anschreiben_in.rtf --outputfile=!Komma_out.rtf --datafile=Adresse_Komma.csv
Here the comma is the separator in the CSV
--delimiter=, -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@
- Explanations
Besides the already described call parameters --help, --inputfile, --datafile and --outputfile, the parameter file contains further call parameters that are taken into account during the merge process.
The --logfile parameter creates a file to which all errors occurring during the merge process are written. The log file is generated without path specification in the current working directory, so after the merge process the following text is also in the log file:
CIB merge 3.9.171
CIB software GmbH 1991-2009
This software is protected by copyright law and international treaties
protected. Unauthorized duplication and distribution, independent in what way
or by what means, electronically or mechanically and independently for what
purpose, whether in whole or in part, may have serious civil and criminal
consequences and is punished to the fullest extent of the law.
The mixing
process uses the following input and output files:
Input file: Anschreiben_in.rtf
Control file: Adresse_Komma.csv
Data set file:
Output file: Komma_out.rtf
log file: Komma_log.log
…
As delimiter in the CSV file the comma character is defined with the --delimiter parameter. The CSV file Adresse_Komma.csv therefore looks like this
first name,last name,street,postal code,city,gender,customer no,order no,amount,Max,Müller,Test Street 3,99999,Test City,M,0987392,232222-4,123118
Calling the parameter file via JAVA
Instead of setting the parameter file via the command line, it can also be called via JAVA. The same result is achieved with the following JAVA code (MergeParameterfile.java):
Extract from MergeParameterfile.java:
…
JCibMergeJob t_Job = new JCibMergeJob(); t_Job.initialize(); if (!t_Job.isInitialized()) { // Fehler beim Initialisieren System.err.println("Fehler beim Initialisieren"); System.exit(1); } try { // Parameterdatei für den Mischlauf t_Job.setProperty(ICibMergeJob.PROPERTY_PARAMETERFILE, "Komma_par.par"); //Job ausführen t_Job.execute(); //Fehlerbehandlung int t_Error = ((Integer)t_Job.getProperty(IComodJob.PROPERTY_ERROR)).intValue(); if (t_Error != 0) { // Fehler beim Ausführen des Jobs String t_Errortext = (String)t_Job.getProperty(IComodJob.PROPERTY_ERRORTEXT); System.err.println("Fehler beim Ausführen: "+t_Error+" "+t_Errortext); } } finally { t_Job.terminate(); } …
Calling the parameter file via C++
If the control is done via C++, the corresponding parameter file can be executed with the help of CibMergePFile. The directory C:\\comod\\, in which the CIB modules are located, must be adapted accordingly, since it is required for the initialization of CIB merge.
Extract from MergeParameterfile.cpp:
…
extern "C" const char *cibmerge_errormessage;
int main(const unsigned int number_of_arguments, char *argument_vector[]) { if(!cibmerge_initialize("C:\\comod\\", 0)) cout << cibmerge_errormessage << endl;
int iReturn=0; iReturn = CibMergePFile("Komma_par.par"); cout << "Returnwert CibMergePFile: " << iReturn << endl;
if(!cibmerge_terminate()) cout << cibmerge_errormessage << endl; return 0; }
- Set default behavior for undefined/empty variables
Now a defined default value should be output in the result RTF if a variable cannot be filled by the data supply or if it is empty. For this purpose, the value "<unknown value>" in red letters is assigned to a variable named "Default" in the Default_in.rtf RTF file using the SET field command.{ SET Default. „<unbekannter Wert>“ }
All empty or undefined variables should get this value. The CSV file Adresse_Default.csv is modified so that there is no value for the variable City. To support this behavior, it is necessary to set additional parameters.
The following call starts the merge process with desired default behavior (Default.bat):
cibmrg32.exe --parameterfile=Default_par.par
Extract from parameter file Default_par.par:
…
Involved files for the merge process
--inputfile=Default_in.rtf --outputfile=!Default_out.rtf --datafile=Adresse_Default.csvSetting Default behavior
--default-mode=all --default-prefix=Default. …
- Explanation
The --default-mode parameter defines in which cases the default behavior, i.e. the insertion of a substitute value, should be activated. In this case, a default value should be inserted, if a variable cannot be filled by the data supply, because it is not defined or because it is empty. If the behavior is to apply only to undefined variables, the default mode must be set to "undefined" (instead of "all").
The prefix, which is prefixed to unknown/empty variables, is defined with the parameter --default-prefix. Here it is the prefix "Default". For the variable Location no value was found in the data source, so it is checked if a value for Default.Location is defined. Since this is also not the case, the value that is defined for "Default. namely "<unknown value>". The result can be found in the file Default_out.rtf.
- Set input and output language for number format/date format
The RTF Language_in.rtf has been modified to include a number format switch for formatting the invoice amount. The amount should now be displayed with thousands separators and 2 decimal places. The cover letter is written in English. Accordingly, in this case, the number format is specified in English. The output of the numbers should also be in English number format. In the RTF, the following expression is therefore displayed:
{ REF Amount \# #,####0.00€}
In order to achieve a correct display in the result document, the parameters must be set to indicate that the input is an English number formatting (and not a German one, as assumed by default). To keep this formatting in the output document, an additional parameter must be set.
The following call starts the merge process to create the English payment reminder (Language.bat):
cibmrg32.exe --parameterfile=Language_par.par
Extract from the parameter file Language_par.par:
…Involved files for the merge process:
--inputfile=Language_in.rtf --outputfile=!Language_out.rtf --datafile=Adresse.csvInput format for numbers is in English
--input-language=english Output format for numbers and date is in English--output-language=english …
- Explanations
The calling parameter --input-language=English indicates that the number format specification in the RTF is in English. In order to achieve a correct display in the result, this information must be given, otherwise it is automatically assumed that the formatting is German, which may lead to unwanted results.
To get the numbers and dates in the result document also in English, the call parameter --output-language is set.
The field { DATE \@ "dddd, d.MM.jjjj" } appears in the result document e.g. as "Friday, 23.10.2009. (German: Freitag, 23.10.2009)
The field {REF Amount \# #,####0.00 } will be formatted to "123,118.00" for an amount of 123118. (German: 123.118,00)
Optimizing raw texts before delivery
In the following, we will demonstrate how to optimize and compress RTF templates. Especially in large projects this plays a role. The optimization is shown exemplarily with the RTF file Optimierung_in.rtf. This file contains some \* MERGEFORMAT switches, which MS Word partially inserts when inserting or reformatting REF fields. These switches should be removed from the RTF. Other ways to speed up the processing in CIB merge and CIB format is to use short tokens. The usage of short tokens offers additional protection against manipulation, because the file can only be processed with CIB modules. If the files are exchanged between different machines, a transfer can be accelerated by compressing the file before. All these steps should be performed without interfering with field contents. Which combination of optimizations makes sense depends on the respective environment and field of application. To test the effects of the various parameters, the respective parameters can be commented ("#" in the respective line can be removed).
The following call optimizes the input file (Optimierung.bat):
cibmrg32.exe --parameterfile=Optimierung_par.par
Content of the parameter file Optimierung_par.par:
Errors shall be logged--logfile=!Optimierung_log.log
--inputfile=Optimierung_in.rtf Output explicitly in own directory--outputfile=!Optimierung_out.rtf Remove Mergeformat switch--optimizeUse short tokens
#--short-tokensCompress#--compress=9Do not interfere with content--filter=f
- Explanations
The --optimize parameter
removes all MERGEFORMAT switches in RTF. This makes the file a bit smaller and
more readable. The --short-tokens
parameter creates an output file with shortened CIBrtf tokens (CIBRtf). The shortened
RTF commands in the output result in a smaller result file compared to the RTF.
This leads to an accelerated processing in CIB merge and CIB format. In
addition, the file can only be further processed with CIB modules. The --compress parameter
creates a compressed output file. Here the highest compression level 9 was
selected. Compression reduces the file size considerably. Additional usage of
--short-tokens would not result in a noticeable size advantage. The --filter parameter
the field contents are not evaluated. The assignment "f" (almost)
also prevents the field contents from being parsed and translated.
- Further possibilities for additional calling parameters
Now a postprocessing in the CIB dialog shall be controlled by switches in the RTF. The output shall be generated encrypted. The data is now created by the application in the code page PCA. In RTF the "\* CHARFORMAT" switch should not have to be set manually for each field.
The parameter file Zusatz_par. contains the necessary additional parameters to support this (Zusatz.bat):
cibmrg32.exe --parameterfile=Zusatz_par.par
Involved files for the merge process
--inputfile=Zusatz_in.rtf --outputfile=!Zusatz_out.rtf --datafile=Adresse_pca.csvUnderstanding additional switches for HTML output
--html-switchesAccept field formatting despite switch--charformat=plain-values-onlySupport CSV with PCA character set--codepage=pcaEncrypt output
--encrypt
- Explanations
In the RTF module Zusatz_in.rtf, fields with additional switches are defined, which play a role when converting to HTML. In this example, these are single-line text fields which can be filled in via CIB dialog ({ REF first_name\* <cib-formfield type="text" info="first_name" testvalue="Max" /> }). To understand these additional switches, the parameter --html-switches has to be set.
The --charformat=plain-values-only parameter causes the fields that are equipped with such an additional switch to still retain the formatting of the field. In this case the fields First Name and Last Name are formatted bold. After the merge process, these fields are also displayed in bold, although they contain additional switches.
The used CSV file (address_pca.csv) uses the PCA character set. To display the data correctly (e.g. umlauts), the parameter --codepage=pca must be set.
The --encrypt parameter encrypts the output file Zusatz_out.rtf. Further processing with CIB modules is still possible.
10.2. Use case example Serial Letter
GeneralSimple merge call from command line
Serial letter with 3 datasets as multi-RTF
Serial letter with dynamic table and multi-CSV
Cancelling the merge process via progess bar
Serial letter with XML data source and alias definitions in the RTF
Serial Letter with XML data source, alias names in XML files, usage of prefixes
Calling an XML job from command line
Calling an XML job from Java
Define NEXT behavior in case of missing variables
General
If the payment reminder from the previous example is to be sent not only to one customer, but to several, this can be done without changing the cover letter. Only the CSV file must be supplemented with the additional data of the other customers. The automatic mail merge functionality is easiest to understand if there is a mental loop around the text which forwards the control file (implicit loop). The following assumes that you are in the Mail Merge subdirectory.
The CSV file Adressen.csv contains 4 datasets:
Vorname;Name;Strasse;PLZ;Ort;Geschlecht;KundenNr;AuftragsNr;Betrag Max;Müller;Teststr. 3;99999;Testort;M;0987392;232222-4;123118 Franz;Meier;Teststr. 4;12345;Musterdorf;M;9898989;111111-2;999 Maria;Huber;Teststr. 5;54321;Testheim;W;1234567;876564-1;500 Franziska;Bauer;Teststr. 6;77777;Neumusterdorf;W;6665554;981234-0;3333 Franziska;Bauer;Teststr. 6;77777;Neumusterdorf;W;6665554;981234-0;3333
Simple merge call from command line
The following simple command line call creates the desired serial letter (Serienbrief.bat):
cibmrg32.exe ..\Lueckentext\Anschreiben_in.rtf !Serienbrief_out.rtf Adressen.csv
The cover letter from the gap text example serves as input, the output file is called Serienbrief_out.rtf and the extended CSV file with 4 data sets is used as usage. CIB merge automatically generates a mail merge in this merge process, which contains a payment reminder (separated by section breaks) for each data set from the CSV file. Changes in parameters or RTF are not necessary.
Serial letter with 3 datasets as multi-RTF
Now a mail merge letter is to be created, which does not contain all data sets, but only the first three. Furthermore the result should be a multi-RTF and not, as before, an RTF separated by section breaks. Furthermore, the information shall be provided, how many documents were created in this merge process.
For the sake of clarity, the merge process will again be controlled by a parameter file, which contains the input, output, and data file as well as the necessary parameters to achieve the desired result (Serialletter.bat):
cibmrg32.exe --parameterfile=Serialletter_par.par
Content of the parameter file Serialletter_par.par
Errors shall be logged--logfile=!Serialletter_log.logInvolved files for the merge process--inputfile=..\Lueckentext\Anschreiben_in.rtf --outputfile=!Serialletter_out.rtf --datafile=Adressen.csvCreation of a multi-RTF
--serialletter=multiOutput of the amount of created documents--statistics=!count.txt -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@ --merge=3
- Explanations:
The --merge=3 parameter starts the merge process and uses all previously set parameters. The number 3 indicates that a mail merge is to be created using the first three data sets from the data source.
With --serialletter=multi the mail merge will be created as multi-RTF and not, as default, a document that contains the different data sets by section break.
Using the --statistics parameter, another file is created, which contains the number of generated documents. In this case the file count.txt has the content:
GeneratedDocumentCount=3
Serial letter with dynamic table and multi-CSV
The payment reminder is now to be extended by further information. For each customer, an overview of the open line items should be listed on a separate page.
The line items must be made available in a suitable form. The easiest way to do this is to use an additional CSV file Einzelposten.csv. In order to determine which line items belong to which customer, this CSV file contains for each line item the corresponding order number of the customer. The lines are sorted by these order numbers (both in the file Adressen.csv, as well as in the file Einzelposten.csv).
Now you must specify that several CSV files are to be loaded for this merge process. This is done by means of a multi-CSV file (multi.csv). It contains the names of all CSV files that are to be loaded in the current merge process. Using the fields in the header of the multi-CSV file, each CSV file is assigned an alias that can be used to access these CSV files in the document.
Extract from Adressen.csv:
Vorname;Name;Strasse;PLZ;Ort;Geschlecht;KundenNr;AuftragsNr;Betrag Franz;Meier;Teststr. 4;12345;Musterdorf;M;9898989;111111-2;999 Max;Müller;Teststr. 3;99999;Testort;M;0987392;232222-4;123118 …
Extract from Einzelposten.csv:
KundeAuftragsNr;Bezeichnung;EinzelBetrag 111111-2;Artikel1;999 232222-4;Artikel1;18 232222-4;Artikel2;123100 …
multi.csv:
Kunden;Einzelposten Adressen.csv;Einzelposten.csv
A dynamic table listing the individual items must be inserted in the cover letter.
A section break is inserted after the text of the cover letter. The new page contains a table listing all the associated line items. This is done via a loop.
Extract Einzelposten_in.rtf
…
The order {REF OrderNo } consists of the following single items:
|
Description |
Amount |
{ IF { = AND({ MERGEREC ?SingleItems};{ COMPARE { REF OrderNo } = { REF CustomerOrderNo } })} = 1
|
“{ REF Description } |
{REF SingleAmount} |
{ NEXT SingleItems }“ \* WHILE }
…
As long as a line item exists (check with { MERGEREC ?line item}) and the customer order no. corresponds to the customer order no. (COMPARE { REF order no. } = { REF CustomerOrderNo. }), the name and the amount of the line item is displayed in a table and in the line item.csv it is switched to the next data set ({ NEXT line item }). If the data for the comparison were purely numerical, the COMPARE could be omitted.
The implicit loop in the automatic mail merge functionality switches the control file on. If, as in this case, several control files are involved in the merge process, all control files would be forwarded. However, since the file Einzelposten.csv is switched in the RTF itself using the NEXT command, this is not desired here. To avoid this, an explicit loop is set around the letter and the serial letter function is switched off.
Extract from Einzelposten_in.rtf
{ IF {MERGEREC ?Customers } = 1“
…Here follows the complete cover letter…
{ NEXT Customers }{ IF {MERGEREC ?Customers } = 1“…Here section break…“}“ \*WHILE }
The loop goes through all customers from the file Addresses.csv and inserts a section break after each letter, if there is another customer.
The following call creates the desired form letter with dynamic table (Einzelposten.bat):
cibmrg32.exe --parameterfile=Einzelposten_par.par
Errors shall be logged--logfile=!Einzelposten_log.logInvolved files for the merge process--inputfile=Einzelposten_in.rtf --outputfile=!Einzelposten_out.rtf --datafile=multi.csvThe data file is a multi-CSV
--multidatafile -mThe mixing process uses the following input and output files: -m@Switch off serial letter functionality
--merge=1- Explanations:
The RTF file Line Einzelposten_in.rtf serves as input. As described, this file contains two loops with which the control files are forwarded.
The --multidatafile parameter indicates that the file specified with the --datafile parameter is a multi-control file.
As already described, the control files are forwarded in the RTF itself. Any forwarding resulting from the automatic mail merge functionality should be suppressed. The --merge=1 parameter executes the merge process as a single merge run. The mail merge is created only with the help of RTF field commands.Cancelling the merge process via progess bar
The RTF file Endlosschleife_in.rtf contains an endless loop due to a forgotten NEXT field. If the text programmer makes such an error, the merge process can only be aborted via the task manager. To avoid this, a progress dialog is shown below, which can be used to abort the merge process.
The following call starts the endless merge process with progress display (Endlosschleife.bat):
cibmrg32.exe --parameterfile=Endlosschleife_par.par
Errors shall be logged
--logfile=!Endlosschleife_log.logInvolved files for the merge process--inputfile=Endlosschleife_in.rtf --outputfile=!Endlosschleife_out.rtf --datafile=multi.csvThe data file is a multi-CSV
--multidatafile -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@Show progress bar
--dialog=topSwitch off serial letter functionality
--merge=1
- Explanations:
Input RTF is Endlosschleife_in.rtf. This produces an endless loop during the merge process.
The --dialog=top parameter sets a progress bar in the foreground, which also contains a button to cancel the merge process.
Serial letter with XML data source and alias definitions in the RTF
In the following, the data will not be transferred as CSV files, but as XML. The data should be in a single file Daten.xml. No multi-CSV file shall be used anymore.
The following extract from Daten.xml shows a possible conversion of data from CSV to XML:
<?xml version="1.0" encoding="ISO-8859-1" ?> <root> <data> <Kunden> <Kunde> <Vorname>Franz</Vorname> <Name>Meier</Name> <Strasse>Teststr. 4</Strasse> <PLZ>12345</PLZ> <Ort>Musterdorf</Ort> <Geschlecht>M</Geschlecht> <KundenNr>9898989</KundenNr> <AuftragsNr>111111-2</AuftragsNr> <Betrag>999</Betrag> </Kunde> weitere Kunden ...... </Kunden> <Posten> <Einzelposten> <KundeAuftragsNr>111111-2</KundeAuftragsNr> <Bezeichnung>Artikel1</Bezeichnung> <EinzelBetrag>999</EinzelBetrag> </Einzelposten> weitere Einzelposten.... </Posten> </data> </root>
The alias definitions are defined directly in the RTF input file NextDef_in.rtf using the { NEXT ”DEF:Aliasname;<filepath>” }. With this special variant of the NEXT switch a new control file can be assigned to a current alias name in the current document. This command automatically loads the first data set of this file.
In this case the following alias definitions are in the RTF:
{ NEXT ”DEF:customers;XML:{ REF XmlFilename };/root/data/customers/customer“ }
{ NEXT ”DEF:single_item;XML:{ REF XmlFilename };/root/data/items/single_item“ }
In order not to wire the name of the XML-file in the RTF, a variable XmlFilename is used here instead. This variable must be set externally via parameters. After the filename follows a semicolon separated XPath information to the respective data. /root/data/customer/customer returns all <customer>-node from the file XmlFilename.
The following call creates the desired serial letter with XML data supply (NextDef.bat):
cibmrg32.exe --parameterfile=NextDef_par.par
Errors shall be logged
--logfile=!NextDef_log.logInvolved files for the merge process--inputfile=NextDef_in.rtf --outputfile=!NextDef_out.rtfSet the filename for the XML data supply
--set=XmlDateiname=Daten.xml -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@Switch off serial letter functionality
--merge=1
- Explanations:
Input RTF is NextDef_in.rtf and contains alias definitions for the XML data.
The --set parameter sets the value Daten.xml to the file XmlFilename. This allows to set the filename variably from outside.
Due to the alias definitions in the raw text, a multi-control file is no longer required. The parameters --datafile and --multidatafile can therefore be omitted.
Since the series is also created by explicit loops in the raw text, the parameter --merge=1 disables the serial letter function.Serial Letter with XML data source, alias names in XML files, usage of prefixes
Now the alias definitions should no longer be in the raw text, but together with the data in the XML file. Furthermore, the uniqueness of the variables shall be guaranteed by usage of prefixes in the raw text. These prefixes should be prefixed to the variable name with the separator “.”.
To realize this, the Daten.xml is extended as follows. (Daten_mitAlias.xml)
<multi> <Kunden>XML:$(this);/root/data/Kunden/Kunde</Kunden> <Einzelposten>XML:$(this);/root/data/Posten/Einzelposten</Einzelposten> </multi>
The construct XML:$(this) specifies that an alias definition refers to data contained in the same XML file where the alias definition is located.
The input file must be extended so that all variable names are preceded by the respective alias followed by a dot.
So { REF first name } becomes { REF customer.first name } etc.
If, for example, the variable amount is used for both line items and customers, the prefix ensures uniqueness. As always, the parameters can be defined via a parameter file. An alternative would be to provide the parameters and data together in a so-called XML job. This job can also be executed via command line. Execution variants using Java and C++ are also explained in the following.
The following call generates the desired serial letter with XML data supply (Prefix.bat):
cibmrg32.exe --parameterfile=Prefix_par.par
Content of the file Prefix_par.par:
Errors shall be logged--logfile=!Prefix_log.logInvolved files for the merge process--inputfile=Prefix_in.rtf --outputfile=!Prefix_out.rtfPath to XML file
--headerfile=XML:Daten_mitAlias.xmlXPath to access the alias definitions--datafile=/root/multi --multidatafileDelimiter between alias and variable names (default is dot)
--prefix-delimiter -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@Switch off serial letter functionality
--merge=1
- Explanations:
Input RTF is Prefix_in.rtf, which was extended by alias names for the variables as described.
The --headerfile parameter sets the data source to use (Daten_mitAlias.xml) and --datafile the XPath to the alias names.
By adding the --multidatafile parameter, CIB merge interprets the alias definitions independently and provides the corresponding alias names.
This can eliminate the {next}-DEF field statements in the raw text.
The --prefix-delimiter parameter defines the dot as separator between alias and variable name. The raw text must be extended so that all variables are preceded by the corresponding alias followed by this separator.
The result is written to the file Prefix_out.rtf.
Calling an XML job from command line
If the data is available as XML anyway, it is possible to set the parameters in an XML as well. This way the data and the parameters can be placed in a single XML file. All necessary properties are set in a so-called merge step. This job XML (PrefixJob.xml) can then be called from the command line as follows (PrefixJob.bat):
cibrsh.exe -d PrefixJob.xml
Extract from the file PrefixJob.xml (Comments begin with <!-- and end with -->)
<step name="merge" command="merge"> <!-- List of properties for this step --> <properties> <!-- data transferred to the XML -->
<property name="--logfile">!PrefixJob_log.log</property>
<property name="--inputfile">Prefix_in.rtf</property>
<property name="--outputfile">!Prefix_out.rtf</property>
<property name="-h">XML:$(inline)</property>
<property name="--datafile">/root/multi</property>
<property name="--multidatafile"/>
<property name="--prefix-delimiter"/>
<property name="-@">1</property </properties> </step>
The data, which was previously provided via the file Daten_mitAlias.xml, can be passed directly with in the PrefixJob.xml. This is specified with XML:$(inline) at the parameter -h. Here the usage of the short form -h must be used explicitly, because it is expected in exactly the same way. The same applies to -@.
The data from Daten_mitAlias.xml can be transferred directly to PrefixJob.xml by inserting them directly below the <root> node.Calling an XML job from Java
If an XML job is used, it can also be executed via Java. For this usage the class JCibJobJob is used. In the following small Java application the file PrefixJob.xml is also executed:
Extract from MergeJob.java:
…
JCibJobJob t_Job = new JCibJobJob();
t_Job.initialize();
if (!t_Job.isInitialized())
{
// Error while initializing
System.err.println("Error while initializing");
System.exit(1);
}
try
{
t_Job.setProperty(ICibJobJob.PROPERTY_INPUTFILENAME,
"PrefixJob.xml");
//Execute job
t_Job.execute();
//Error handling
int t_Error = ((Integer)t_Job.getProperty(IComodJob.PROPERTY_ERROR)).intValue();
if (t_Error != 0)
{
// Error while executing the job
String t_Errortext =
(String)t_Job.getProperty(IComodJob.PROPERTY_ERRORTEXT);
System.err.println("Error while executing": "+t_Error+" "+t_Errortext);
}
}
finally
{
t_Job.terminate();
}
…
Define NEXT behavior in case of missing variables
In the following, an XML node is missing in a data set. The Daten.xml file is adjusted so that the node <CustomerNo> is missing in the third customer data set (Daten_NextMode.xml). In the result would simply be nothing at the position where this variable is inserted. In the following a variable, which is contained in a data set, but not in the next one, is to be deleted. This should lead to an error and the mixing process should be aborted.
The following call generates the desired behavior (NextMode.bat):
cibmrg32.exe --parameterfile=NextMode_par.par
Content of the file NextMode_par.par:
Errors should be logged--logfile=!NextMode_log.logInvolved files for the merge process--inputfile=NextDef_in.rtf --outputfile=!NextMode_out.rtfSet the file name for the XML data supply
--set=XmlDateiname=Daten_NextMode.xml -mDer Mischvorgang verwendet folgende Ein- und Ausgabedateien: -m@Set behavior for NEXT if variable does not exist
--next-mode=deleteSwitch off serial letter functionality
--merge=1
- Explanations:
The --next-mode parameter with the assignment "delete" causes the missing variable Customer No. to be deleted and thus no longer defined. This results in an error.
unknown variable:
name: customer no.
and the mixing process is aborted.
10.3. Use case example Report with various templates
GeneralUsage of subdirectories for data sources and RTF templates
Optimizations for templates with new colors, fonts, control lists
Define time of cancellation when errors occur
Handling unsupplied fields
Removing field results from raw text
Insert dynamic business graphics embed graphics
Analysis of the field structure in RTF templates
General
The following assumes that you are in the "Templates" subdirectory. The following example contains a letter from a bank to a client informing him of the current status of his accounts. It contains a list of his accounts, including account type, current balances and a total of the balances. A bank logo is also included. This is done in RTF using the field command
{ INCLUDEPICTURE „Logo.jpg“}.
The data is available in several CSV files. These contain customer data (knd_kunde.csv), information about his accounts (kont_konten.csv), bank data (bnk_bank.csv) and information about his contact person (ber_berater.csv). It is useful to store the data sources in a separate directory. In this case the files are located in the subdirectory „csv“.
This time the letter is not in a single RTF file, but is divided into several blocks. These RTF templates are also located in a separate subdirectory "templates". There is a root templates (wurzelbaustein.rtf), which attracts several building blocks. This is done with the field command { INCLUDETEXT "Baustein.rtf" }. Among other things, there are templates for headers and footers (different for the first page and subsequent pages), for the cover letter and for the account overview.
The account overview is realized as a dynamic table, which was already explained in detail in the application example serial letter:
|
LfdNo |
AccountNo |
Balance |
AccountType |
{ SET Balance_Sum 0 } { IF { MERGEREC ?Accounts } = 1
|
“{ MERGEREC Accounts } |
{ REF Acc_AccountNo } |
{ REF Acc_Balance \# 0,00 } |
{ REF Acc_AccountType } |
{ SET Balance_Sum { = { REF Balance_Sum } + { REF Acc_Balance } } }{ NEXT Account }" \* WHILE }
|
Sum balances |
{ REF Balance_Sum \# 0,00 } |
To form a sum over the balances, a variable Balance_Sum is defined before the loop using the SET field command and set to 0. In the loop, for each account the corresponding balance is added. At the end, a grand total is output.
The result should also be written in a separate subdirectory "result".
Usage of subdirectories for data sources and RTF templates
The following call creates the finished letter including account overview (Bausteine.bat):
cibmrg32.exe --parameterfile=Bausteine_par.par
Content of the file Bausteine_par.par
--logfile=!Bausteine_log.log
--target-directory=csvTemplates are located (relative to target) here--source-directory=..\templatesInput file (can be found in source)--inputfile=wurzelbaustein.rtfOutput explicitly to own directory--outputfile=!..\result\Kontenuebersicht.rtfData source is multi-CSV--datafile=multi.csv --multidatafile --charformat
- Explanations
The example uses the --target-directory parameter to set the path for the data files. Thus, no explicit path specification is required for the parameter --datafile. Here it is sufficient to specify the file name of the multi-CSV. All further CSV files are then also expected in this directory.
The --source-directory parameter sets the directory where the RTF root document and RTF templates are expected. The path is relative to the path specified with --target-directory. By setting this call parameter, no explicit path specification is required in the --inputfile parameter. Here it is sufficient to specify the name of the root module. All further templates are then also expected in this directory (if no explicit path specification is made with INCLUDETEXT).
The result Kontenuebersicht.rtf will be written though an explicit filepath in the subdirectory „result“. If no path were specified here, the result would be written to --target-directory.
The --multidatafile parameter specifies that the file with the --datafile parameter is a multi-control file.
Optimizations for templates with new colors, fonts, control lists
New colors, fonts and lists are used in the templates. By default these are also included in the result document, because the RTF header is rewritten at the end. Here different optimizations are possible, which can be switched off by the user. In the following the new fonts should be ignored, but all colors should be included, even those that are not used. This is useful, for example, if a printer can only print certain fonts. Since the document may still be edited after the merge process, all usage lists should be available here. Unused lists, however, should be removed.
The following call produces the desired result (Header.bat):
cibmrg32.exe --parameterfile=Header_par.par
Extract from Header_par.par:
… --replace-header=automatic --fonts=keep --colors=expand --lists=adjust
- Explanations
Without the --replace-header parameter, the fonts and lists as well as the colors are included in the result RTF. --replace-header=automatic causes the RTF header to be rewritten taking into account the settings of the parameters --fonts, --lists and --colors.
The --fonts parameter with the assignment “keep“ causes that the main font table is not extended by the new fonts. Also no additional optimization is performed, which removes the unused fonts.
The --colors parameter assigned to “expand” causes new colors to be added to the main color table and unused colors are not removed.
The --lists parameter with assignment „adjust” causes new lists to be added to the main list table, but unused lists are removed.
Define time of cancellation when errors occur
CIB merge aborts the processing if, for example, a variable is used which is not defined. In the following, instead of the correct CSV file kont_konten.csv, the CSV file kont_konten_undef.csv is used. In this file the variable kont_kontoart is written incorrectly (kont_kontart). If now a merge process is started, which uses this incorrect CSV file, a result RTF with a defective table is created. (OhneBreak_out.rtf).
The following call creates the RTF with defective table (OhneBreak.bat):
cibmrg32.exe --parameterfile=OhneBreak_par.par
Extract from OhneBreak_par.par:
… --outputfile=!..\result\OhneBreak_out.rtf --datafile=multi_undef.csv …
The merge process should now be continued, if possible, although the variable kont_kontoart is not defined. The table should still be output in such a way that a valid RTF is generated. Afterwards, however, the mixing process should be aborted.
The following call creates the desired result (BreakLoop.bat):
cibmrg32.exe --parameterfile=BreakLoop_par.par
The following parameter is additionally set here:
--break=loop
Now, even if errors occur, the mixing process should be carried out to the end and return an error.
The following call produces the desired result (BreakNever.bat):
cibmrg32.exe --parameterfile=BreakNever_par.par
The following parameter is set here:
--break=never
- Explanations
The --break parameter shifts the point in time at which CIB merge stops the mixing process in case of an error.
With --break=loop the following behavior is achieved: if the merge process is currently in a loop, it is only run to the end after the error, i.e. it is not repeated. Immediately afterwards the mixing process will be aborted.
--break=never causes CIB merge to execute the merge job to the end regardless of any errors and returns the error code of the first error.
Handling unsupplied fields
In some cases it may be desirable that a certain variable is not supplied by the data sources (e.g. for a possible later residual data acquisition). In the following, the variable kont_kontoart is intentionally not defined (the same input files can be used as in the previous example). In this case, the merging process should be continued and all unsupplied fields should remain as REF fields in the output file.
The following call produces the desired result (KeepFields.bat):
cibmrg32.exe --parameterfile=KeepFields_par.par
The following parameter is additionally set here:
--keep-fields=unresolved-ref
- Explanations
The --keep-fields=unresolved-ref parameter ensures that the merging process is continued despite missing data supply for the variable kont_kontoart and that the REF field for kont_kontoart in the output file KeepFields_out.rtf is preserved.
Removing field results from raw text
MS Word inserts so-called field results into the raw text, most of which are not required by the CIB modules. By the INCLUDETEXT statements in wurzelbaustein.rtf the RTF contains some of these unnecessary field results. To optimize the file size, most of them can be removed. The result should no longer contain unnecessary field results.
The following call produces the desired result (FieldResults.bat):
cibmrg32.exe
--parameterfile=FieldResults_par.par
The following parameters are set here:
Errors should be logged--logfile=!FieldResults_log.log
--target-directory=csvTemplates are located (relative to target) here--source-directory=..\templatesInput file (to find in source)--inputfile=wurzelbaustein.rtfOutput explicitly to own directory--outputfile=!..\result\wurzelbaustein_FieldResults.rtfRemove field-results
--field-results=pDo not merge contents--filter=f
- Explanations
The unnecessary field-results inserted by MS Word are removed by the --field-results parameter. By assigning a "p", those necessary for positioning images are retained.
Insert dynamic business graphics embed graphics
In the following, the overview of the account types will be presented graphically in a pie chart. For this purpose, a new CSV file is created which contains the distribution of the assets per investment type (investment type.csv). This CSV file looks like this:
Anlageform;Wert;Legende Girokonto;530,46;Girokonto 0,56% Sparkonto;16.700,00;Sparkonto 17,67% Festgeld;74.000,00;Festgeld 78,29% Depot;3.288,33;Depot 3,48%
This file contains the legend of the chart and the sum of the balances per investment. The file Vermoegensstruktur_torte.emf contains the graphic template that is to be used to create the dynamic business graphic. This graphic and the logo (Logo.jpg), which is inserted in the module Logo.rtf, should be embedded in the result RTF.
The following call generates the desired result (Chart.bat):
cibmrg32.exe --parameterfile=Chart_par.par
The following parameters are set here:
Errors shall be logged here--logfile=!Chart_log.logData sources can be found under this path--target-directory=csvTemplates are located (relative to target) here--source-directory=..\templatesInput file (to find in source)--inputfile=wurzelbaustein_chart.rtfOutput explicitly to own directory--outputfile=!..\result\Chart_out.rtfData source is multi-CSV--datafile=multi_chart.csv --multidatafile --charformatSetting the chart parameters
--chart-source=file --chart-target=embed --merge=1
Explanations
With --chart-source=file specifies that the business graphic should be calculated from the graphic inserted with { INCLUDEPICTURE }.
The --chart-target=embed specifies that all graphics should be embedded in the result RTF (both chart and non-chart graphics).
Analysis of the field structure in RTF templates
In the following, the field structure of the RTF modules is to be determined. The result is to be written into a CSV file Felder.csv This file contains all variables which could be evaluated by an application.
The following call generates the desired result (Analyse.bat):
cibmrg32.exe --parameterfile=Analyse_par.par
The following parameters are set here:
--logfile=!Felder.csv -mPfad;Feld;Wert --logfile=!Analyse_log.log --source-directory=templates --outputfile=- --analyse=+Felder.csv# for every text
--inputfile=Basisbaustein.rtf -m@ --filter --inputfile=Bezug.rtf -m@ --filter... für jeden RTF-Baustein...
--inputfile=wurzelbaustein.rtf -m@ --filter -mdone
- Explanations
The --analyse parameter creates the file Felder.csv, which looks like this after the analysis run (excerpt):
Pfad;Feld;Wert Basisbaustein.rtf;REF;knd_geschlecht Basisbaustein.rtf;REF;knd_nachname Basisbaustein.rtf;REF;ber_vorname Basisbaustein.rtf;REF;ber_nachname Basisbaustein.rtf;REF;ber_vorname Basisbaustein.rtf;REF;ber_nachname Bezug.rtf;REF;knd_bezug Briefkopf.rtf;REF;bnk_name Briefkopf.rtf;REF;bnk_erg_1 Briefkopf.rtf;REF;bnk_erg_2 Datum.rtf;REF;bnk_datumort … Logo.rtf;INCLUDEPICTURE;Logo.jpg wurzelbaustein.rtf;INCLUDETEXT;?KopfFolgeSeiten.rtf wurzelbaustein.rtf;INCLUDETEXT;KopfFolgeSeiten.rtf wurzelbaustein.rtf;INCLUDETEXT;?FussFolgeSeiten.rtf wurzelbaustein.rtf;INCLUDETEXT;FussFolgeSeiten.rtf wurzelbaustein.rtf;INCLUDETEXT;?FussErsteSeite.rtf wurzelbaustein.rtf;INCLUDETEXT;FussErsteSeite.rtf wurzelbaustein.rtf;INCLUDETEXT;?Briefkopf.rtf …
This output file thus provides an overview of all occurring variables. No output RTF is generated (--outputfile=-) and no fields are evaluated (--filter).
Fileless data entry with directory parameters:
|
Total balances (Summe Salden) |
{ REF Saldo_Summe \# 0,00 } |
11. Quick start
This chapter gives you a short overview of possible use of CIB merge from a customer application. The examples do not use the full functional range, but demonstrate the basic principle of using CIB merge.
For your specific use case, please contact CIB Support for further examples.
Note:
For quick use of CIB merge via the CIB runshell from the command line, there are ready-made examples in the transfer package. The calls of the CIB runshell are predefined in batch files.
Integrating CIB merge as C++ Codebeispiel
In the chapter Use case examples there are already code examples available, which demonstrate, how CIB merge can be called from C++. One example shows the call of CIB merge transferring several single parameters and another example using a parameter file.
If you want to integrate CIB merge directly into your C++ application, CIB Support will be glad to provide you with an example.Integrating CIB merge as Java code example
In the chapter Use case examples there are already code examples available, which demonstrate, how CIB merge can be called from JAVA. One example shows the call of CIB merge transferring several single parameters and another example using a parameter file.
If you want to integrate CIB merge directly into your JAVA application, CIB Support will be glad to provide you with an example.Integrating CIB merge as VB code example
If you want to integrate CIB merge directly into your VB application, CIB Support will be glad to provide you with an example“.
Integrating CIB merge as Delphi code example
If you want to integrate CIB merge directly into your Delphi application, CIB Support will be glad to provide you with an example.
Note for using GZIP on JAVA
CIB merge allows ZLIB compression with multiple headers with -z. Under JAVA it is not possible to unpack such files immediately with the GZIP class.
Therefore the example code below supports this:
/*
* Created on 01.08.2006
* <p>
* It was not possible to take the FilterInputStream as a base class because I
* had to call super(gzin) in the constructor. This is supposed to be the first
* line but there gzin is not initialized yet. Further is was not possible to
* call super(new ExtendedGZIPInputStream(...)) because the nested class cannot
* access the not then initialized enclosing class.
* </p>
*/
package de.cib.java.util.zip;
import java.io.ByteArrayInputStream;
import java.io.EOFException;
import java.io.IOException;
import java.io.InputStream;
import java.io.SequenceInputStream;
import java.util.zip.GZIPInputStream;
/**
* <p>
* This is a GZIPInputStream capable of reading a gzipped input stream
* consisting of multiple members.
* </p>
* <p>
* See RFC 1952 about gzip and multiple members.
* </p>
* <p>
* This implementation is based upon the java.io.GZIPInputStream which is not
* capable of reading further than the first member. For further information on
* the implementation see the comment for the java file.
* </p>
*
* @author CIB consulting GmbH, Tammo Wüsthoff
*/
public class MultipleMemberGZIPInputStream extends InputStream {
/**
* I need some data which is not public. So I have to subclass.
*
* @author Tammo
*/
protected class ExtendedGZIPInputStream extends GZIPInputStream {
/**
* Uses a default buffer size * * @param in * gzipped input stream * @throws IOException */ protected ExtendedGZIPInputStream(InputStream in) throws IOException { super(in);
}
/** * @param in * gzipped input stream * @param size * buffer size * @throws java.io.IOException */ public ExtendedGZIPInputStream(InputStream in, int size) throws IOException { super(in, size);
} /** * @return a new InputStream with the unprocessed bytes only or null if * there were none */ public InputStream createInputStreamForUnprocessedBytes() { final int n = getRemaining(); if (n > 0) { return new ByteArrayInputStream(buf, len - n, n); } return null;
}
/** * @return number of unprocessed bytes */ public int getRemaining() { return inf == null ? 0 : inf.getRemaining();
}
/** * @return true iff there is unprocessed data */ public boolean hasRemaining() { return getRemaining() > 0;
}
}
/**
* Unfortunately the trailer is checked in the unprocessed part of the
* buffer inside the original GZIPInputStream. Well, if I want to continue
* with the unprocessed data then I have to skip the trailer again. The
* readTrailer() is private. So I have to guess the length. But the 8 bytes
* are part of the specification RFC 1952.
*/ protected static final int trailerLength = 8;
/**
* gzipped input stream maybe with prepended unprocessed data
*/ protected InputStream base;
/**
* from time to time newly constructed input stream (once per gzip member)
*/ protected ExtendedGZIPInputStream gzin;
/**
* buffer size if given, -1 else, used for reconstruction of the member gzip
*/ private final int size;
/**
* Uses a default buffer size
*
* @param in * gzipped input stream
* @throws IOException
*/ public MultipleMemberGZIPInputStream(InputStream in) throws IOException { super(); base = in;
size = -1; gzin = new ExtendedGZIPInputStream(in);
}
/**
* @param in * gzipped input stream
* @param size * buffer size
* @throws IOException
*/
public MultipleMemberGZIPInputStream(InputStream in, int size)
throws IOException {
super();
base = in;
this.size = size;
gzin = new ExtendedGZIPInputStream(in, size);
}
/**
* @see java.io.InputStream#available()
*/ public int available() throws IOException { if (gzin.available() > 0 || base.available() > 0 || gzin.hasRemaining()) return 1; return 0;
}
/**
* @see java.io.InputStream#close()
*/ public void close() throws IOException { gzin.close();
}
/**
* @see java.io.InputStream#mark(int)
*/ public synchronized void mark(int readlimit) { gzin.mark(readlimit);
}
/**
* @see java.io.InputStream#markSupported()
*/ public boolean markSupported() { return gzin.markSupported();
}
/**
* read a single byte retrying if a gzip member ends just here
*
* @see java.io.InputStream#read()
*/
public int read() throws IOException { int value; do { value = gzin.read();
} while (value == -1 && retry()); return value;
}
/**
* @see java.io.InputStream#read(byte[])
*/
public int read(byte[] b) throws IOException { return read(b, 0, b.length);
}
/**
* read a sequence of bytes retrying if a gzip member ends just here
*
* @see java.io.InputStream#read(byte[], int, int)
*/ public int read(byte[] b, int off, int len) throws IOException { int n; do { n = gzin.read(b, off, len);
} while (n == -1 && retry()); return n;
}
/**
* @see java.io.InputStream#reset()
*/ public synchronized void reset() throws IOException { gzin.reset();
}
/**
* If unprocessed input is available then prepend the remaining bytes to the
* input and skip the trailer. If no unprocessed input is available or after
* skipping the trailer look if there are more bytes in the input. If yes
* then make a new gzip input.
*
* @return true iff further data available
* @throws IOException
*/
protected boolean retry() throws IOException { InputStream unprocessed = gzin.createInputStreamForUnprocessedBytes(); if (unprocessed != null) {
base = new SequenceInputStream(unprocessed, base); base.skip(Math.min(trailerLength, gzin.getRemaining()));
}
// well, looking if there are more bytes using available fails for
// several reasons; other solution: try to initialize gzin; this should // read the gzip header or give eof try { if (size == -1) { gzin = new ExtendedGZIPInputStream(base); } else { gzin = new ExtendedGZIPInputStream(base, size); }
} catch (EOFException e) { return false;
} return true;
}
/**
* @see java.io.InputStream#skip(long)
*/ public long skip(long n) throws IOException { return gzin.skip(n);
}
}
private static void testGunzip() {
try {
FileInputStream fin = new FileInputStream( "d:\\cib\\temp\\output.rtf");
MultipleMemberGZIPInputStream gzin = new MultipleMemberGZIPInputStream(
fin);
StringBuffer stringbuffer = new StringBuffer();
final int size = 512;
byte[] bytebuffer = new byte[size];
char[] charbuffer = new char[size * 4];
int read;
while ((read = gzin.read(bytebuffer)) != -1) {
int converted = ByteToCharConverter.getDefault().convert(
bytebuffer, 0, read, charbuffer, 0, charbuffer.length);
stringbuffer.append(charbuffer, 0, converted);
}
String output = stringbuffer.toString();
System.out.println(output);
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
12. Annex
12.1. Error handling
CIB merge returns unequal 0 if an error occurred. In addition, an error log file can be written during a CIB merge run, which contains detailed information about the occurred error.
The return value can be evaluated by the application, see chapter program return values.
The error log file can be scaled in many ways by the application developer using error categories and diagnostic levels. It is especially helpful for the raw text developer, but can also be used by the user for error analysis. See chapter Error log file.
CIB merge can optionally generate detailed trace files. These are often very useful for CIB support when analyzing complex support cases. See chapter Trace options.
12.2. Program return values
The following list gives an overview of possible error returns by CIB merge. There are interfaces for application developers CoMod to query the text of an error number directly and to help the end user with concrete hints.
With version 3.11 of CIB merge the return values have been changed. Essentially they have been moved from the range 0-20 to the new range 800-820. In the future, the error numbers 800-850 are reserved for CIB merge.
To look up the error numbers of older CIB merge versions, please add 800 to the amount of the last two digits. Examples: 4 -> 804, 302 -> 802.
The error numbers have the following meaning:
|
Return value |
Description |
|
-1 |
The mixing job was cancelled by the user. Cause: In the percentage display the "Cancel" button was pressed or the ESC key was triggered. |
|
0 |
Everything OK. |
|
801 |
invalid parameter identification parameters without parameter identification no input file specified for document syntax: -wHWND;WINID compressed output only possible with files (not with standard input and output) |
|
802 |
file is corrupt |
|
803 |
file not found file already exists file is used by another process read access to file not allowed write access to file not allowed FD/HD memory is full access to file not allowed Has to do with file accesses: Experience from the support: 1) On explicit request, merge already writes a temporary file. A non-existing TEMP directory is set by patch or environment. More concrete: Environment variable CIB_MRGINTERMEDIATE or patch at the position g_pszIntermediate[]= "\0INTERMEDIATE". You can also specify such an
intermediate file by call parameters:
|
|
804 |
file not found syntax error when determining a data source file is not positionable file is default input/output device no file name specified |
|
805 |
message of the parser for time values ... message of the scanner/parser for printout field ... no database access object created |
|
807 |
parameter does not exist anymore parameter lost |
|
808 |
corrupt RTF formatting wrong control worlds |
|
809 |
document is empty |
|
810 |
bookmark of expression not found alias name not found syntax error: ... division by 0 0 exponent 0 negative base high non-integer exponents wrong number of parameters unknown field statement unknown comparison operator in condition invalid information identifier value behind info is not correct unknown switch no control file unknown variable syntax error: " missing {.. " ..} |
|
811 |
no connection to database SQL statement not executed correctly not correctly separated from the database error from database access object could not determine line number alias names exist multiple times could not put on the first line |
|
812 |
time was calculated incorrectly weekday was calculated incorrectly month was incorrectly calculated accessors incompatible invalid index illegal Index illegal status too few fields in the data set too many fields in the data set invalid separator message of the parser for time values ... message of the scanner/parser for printout field ... invalid information identifier invalid field command advance outside the borders unexpected end of list ring buffer too small search tree for RTF token is defective read was called without prior endOfMem check block too large "default:" reached invalid source code page invalid target code page itoa called with base!=10! document variables not known |
|
813 |
in current context invalid values/data |
|
814 |
cancellation by user |
|
815 |
CIB merge encounters an unimplemented field statement / field switch (e.g., typo for switches in REF \* xxxxx ) |
|
817 |
functionality not implemented yet |
|
818 |
allowable total size exceeded |
|
819 |
endless inclusion detected |
|
820 |
error in Recombine |
|
821 |
maximum execution time exceeded |
12.3. Error log file
GeneralDiagnosis level
Error categories
Error log file until CIB merge 3.8.x
General
With the parameter -L(!)<Error log file> CIB merge writes a description of the error message to the specified log file. If no error occurs, an empty file is written. See also Chapter -L<Logfile>.
Error log file with --verbose from CIB merge 3.9.x
As of version 3.9.x, CIB merge writes an error log file freely scalable according to error categories and diagnostic levels, which can thus be individually tailored to the needs of the user.
Diagnosis level
The diagnostic levels indicate the level of detail of the log file as follows:
|
level |
verbosity |
name |
standards |
function |
remarks |
|
0 |
nothing |
silent/still/stumm |
|
quiet |
|
|
1 |
severe errors |
severe/schwer(wiegend) |
|
errors |
|
|
2 |
all errors |
error(s)/Fehler |
|
|
|
|
3 |
important consequences |
initial |
initial |
|
|
|
4 |
helpful consequences |
""/default/standard |
default |
|
|
|
5 |
all consequences |
stack |
|
|
|
|
6 |
helpful information |
info(rmation) |
|
trace |
|
|
7 |
technical information |
technical/technisch |
|
|
|
|
8 |
timing information |
timing/Zeit(en) |
|
|
reserved |
|
9 |
memory information |
memory/Speicher |
|
|
reserved |
If --verbose is not set, the initial level 3 is set. If --verbose is set without a diagnostic level, the default level 4 applies.
Error categories
CIB merge distinguishes different error categories for logging with --verbose:
ALL/ALLE, DATA/DATEN, DIALOG, DOC/DOCUMENT/DOK/DOKUMENT, INCLUDE/EINFUEGEN, FIELD/FELD, FILE/DATEI, PAR, REF, SOURCE/QUELLE, SOURCEPATH/QUELLPFAD
These can be combined as desired, e.g. --verbose +DATA +DOK +INCLUDE or --verbose +ALL -SOURCE
Error log file until CIB merge 3.8.x
The error log file and contains information for application developers, raw text developers and CIB support. Scaling with --verbose is not possible, the file is structured as follows:
The first line indicates the error type and category.
The second line describes in which file the error occurred. CIB merge versions < 3.8.108 give information for the CIB support in the second line.
In the following lines the user gets the necessary information to trace the cause of the error.
The last line of the error messages contains the following information:
Program return value: xxxx - see chapter Program return values "==>" always indicates the consequences in CIB merge.
Notes on the analysis of the error log file
Field statements are always evaluated from inside to outside, CIB merge therefore lists first the "innermost" error and then the resulting errors in the outer fields.
Example
A variable is compared to a fixed value in an IF condition. The template is part of a larger project and is inserted into the root document with INSERT TEXT. If the variable is now missing in the data supply, CIB merge will output the following:
ERROR: error condition: incorrect field statement
Error during the file baustein.rtf
unknown variable
Name: dummy_feld
==> could not evalute field statement
command: REF
parameters: 2 pieces
1: REF
2: dummy_field
Switch: 0 pieces
==> field not recalculated
==> left operand not evaluated
==> condition not evaluated
==> could not evaluate field statement
command: IF
parameters: 6 pieces
1: IF
2: {REF dummy_field}
3: <>
4: ""
5: "REF dummy field is not empty
6: "REF Dummy field is empty".
switch: 0 pieces
==> field result not recalculated and written
==> field not correctly evaluated and written
==> document not completely edited and written
==> data set no.: 1
==> could not evaluate field statement
command: INSERT TEXT
parameters: 2 pieces
1: INSERT TEXT
2: "building block.rtf
switch: 0 pieces
==> field result not recalculated and written
==> field not correctly evaluated and written
==> single document not completely edited and written
==> mixing process cancelled
==> document not completely edited and written
==> data set no.: 1
==> document not processed correctly
Program return value 0010
12.4. Trace possibilities
By optionally setting environment variables in your system environment, you can perform a trace run with our components on demand. The corresponding log files are generated in the desired directory, which can be very helpful for our support.
Setting trace file with environment variables
The trace file will be deleted and rewritten when CIB merge is retriggered. For server applications we recommend the patching of the CIB merge dll described below.
For the trace output please set the environment variable:
CIB_MRGTRACE = <path + filename> (e.g. CIB_MRGTRACE=c:\temp\mrg.log)
Note:
For
older CIB merge versions (up to 3.7.64), the environment variable is CIB_TRACE.
CIB_TRACE = <path + filename> (z.B. CIB_TRACE=c:\temp\mrg.log)
If in doubt, simply set both environment variables.
Patching trace file directly in the dll
You can also patch the trace output directly in the CIB merge dll, this is especially interesting for server applications where CIB merge is always attracted and the trace file would otherwise grow more and more. If the trace output is set by patch, the trace file is deleted after each error-free merge job.
Open the file with a hex editor and search for "EXTERN_CIB_TRACE". Start one character before "EXTERN_CIB_TRACE" and enter the path and name of the trace file in overwrite mode, e.g. c:\temp\cibmrgtrace.txt. This feature is available in CIB merge version 3.7.84d.
12.5. Scope of delivery
CIB merge, is delivered as binary module in form of DLLs or shared libraries (Unix).
|
Component |
Software scope |
|
CIB merge |
WIN32 |
|
|
|
WIN64 |
|
|
|
|
UNIX |
|
|
|
|
XML-Zugriffe |
WIN32 |
|
|
|
WIN64 |
|
|
|
|
UNIX |
|
|
|
|
(optional) |
WIN32 |
|
|
|
WIN64 |
|
|
|
|
UNIX |
|
|
|
|
CIB runshell |
WIN32 |
|
|
|
WIN64 |
|
|
|
|
UNIX |
|
|
Zusätzlich werden die für die C(++) Programmierung erforderlichen Header- und Library Dateien und eine ausführliche Versionshistorie mitgeliefert.